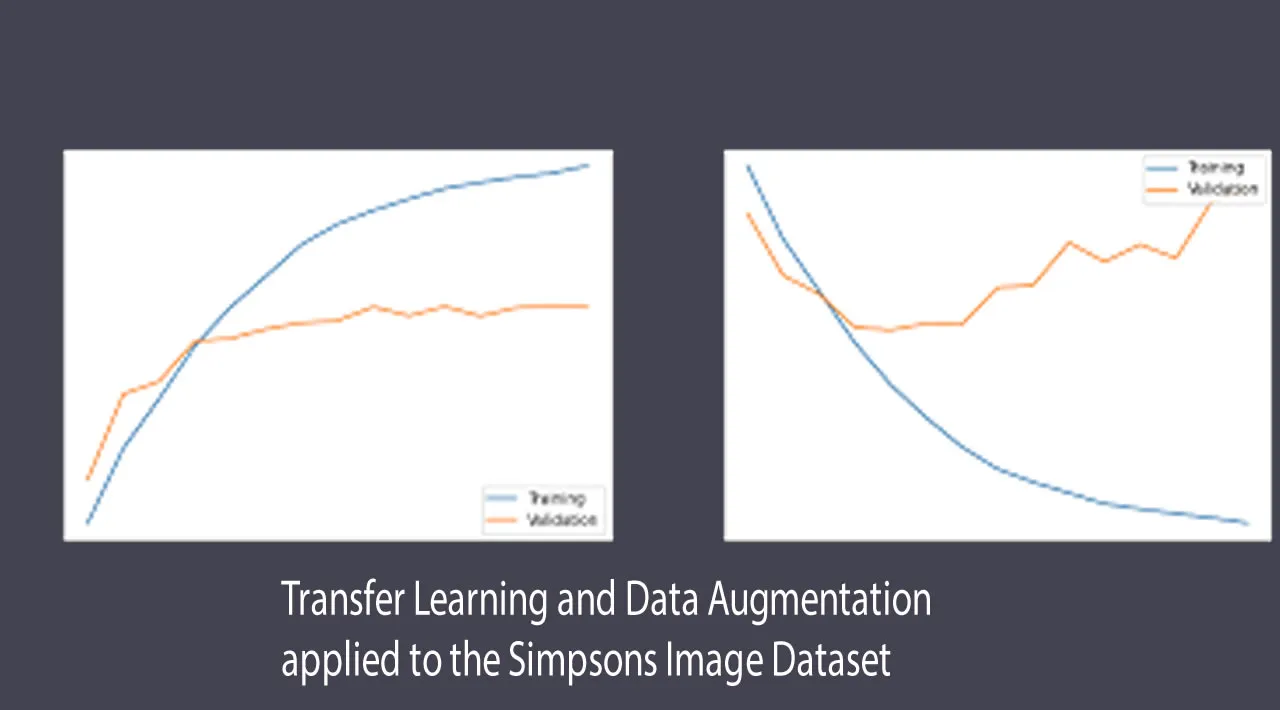
In the ideal scenario for Machine Learning (ML), there are abundant labeled training instances, which share the same distribution as the test data [1]. However, these data can be resource-intensive or unrealistic to collect in certain scenarios. Thus, Transfer Learning (TL) becomes a useful approach. It consists of increasing the learning ability of a model by transferring information from a different but related domain. In other words, it relaxes the hypothesis that the training and testing data are independent and identically distributed [2]. It only works if the features that are intended to be learned are general to both tasks. Another method to work with limited data is by using Data Augmentation (DA). It consists of applying a suite of transformations to inflate the dataset. Traditional ML algorithms rely significantly on feature engineering, while Deep Learning (DL) focuses on learning data by unsupervised or semi-supervised feature learning methods and hierarchical feature extraction. DL often requires massive amounts of data to be trained effectively, making it a strong candidate for TL and DA.
#computer-vision #tensorflow #data-augmentation #transfer-learning #deep-learning