Suppose you’re a software developer, a data scientist, or a programmer. In that case, you must have come across Git at some point along your journey. Mastering version control is one of the essential skills that is shared among all software-related fields.
Version control systems are a particular type of software designed to help programmers track any specific application source code changes.
In general, there are two types of version control systems, _centralized _and _distributed _systems. The main difference between those two types is, in centralized systems, the code files and the information about the contributors are stored in a single server. In distributed systems, however, the code files are copied on every contributor’s machine.
Git is a commonly used distributed version control system based on repositories. It was created by Linux’s creator Linus Torvalds. Torvalds created Git for the management of the Linux kernel source code. Git at the core of many services like GitHub and GitLab.
In this article, we will cover how Git works and its basic building blocks.
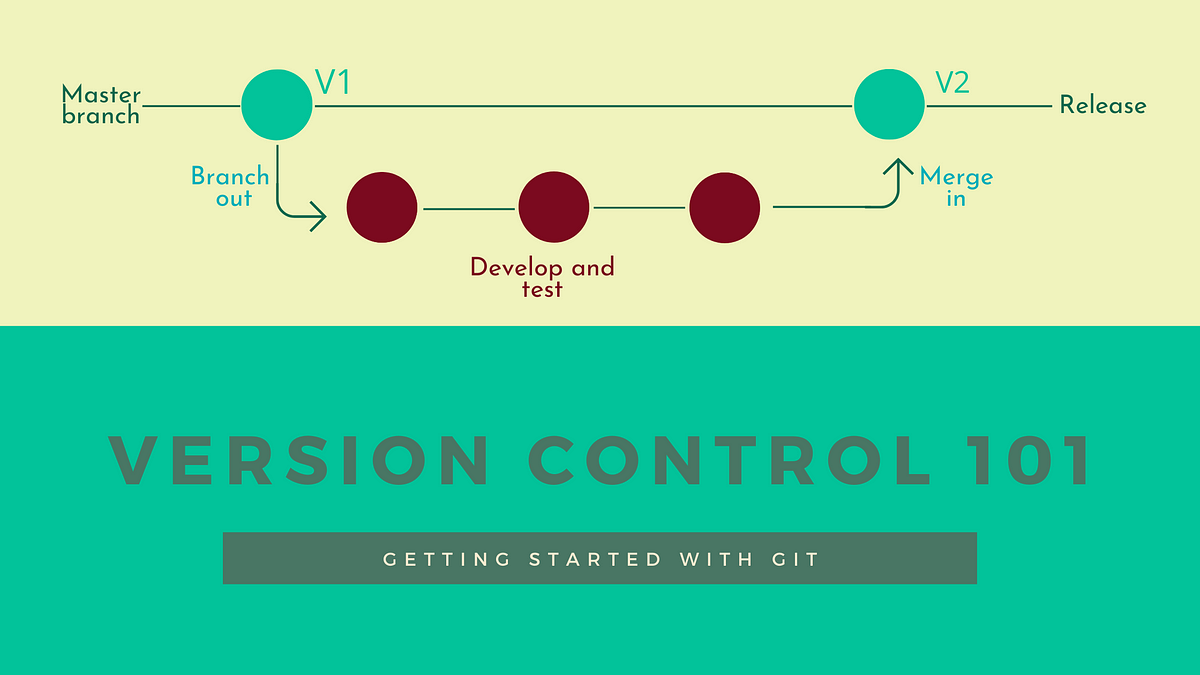
How does Git work?
Git’s algorithms are designed to take advantage of real source code file trees’ common attributes and how they usually get modified over time.
When dealing with code files, Git doesn’t focus on the file’s name and instead keeps track of its content. Git was designed this way because, most often, the names of code files are not fixed.
To store code files, Git uses delta encoding — which keeps the difference in file content — to save repository contents and the version’s metadata explicitly.
The way Git handles changes in the content is by storing different snapshots. Each snapshot is linked to a specific change in the source code. Git is also designed to work very well to apply or roll back the modifications performed between two snapshots.
#women-in-tech #technology #programming #data-science #web-development