Introduction
Apache Airflow is one of the best workflow management systems (WMS) that provides data engineers with a friendly platform to automate, monitor, and maintain their complex data pipelines. Started at Airbnb in 2014, then became an open-source project with excellent UI, Airflow has become a popular choice among developers. There are many good resources/tutorials for Airflow users at various levels. You can start learning Airflow with many good tutorials such as this step-by-step guideline, or this series on Medium in which you can also learn about workflow management system in general. For users already familiar with Airflow, this resource may help you gain a very deep understanding of many aspects of Airflow.
In this post, I simply want to share my experience when creating a data warehouse ETL pipeline on AWS with Airflow. I hope it is helpful. And please, correct me if you found something wrong in my post.
Cautions
1. This article assumes that you__already have some working knowledge of data warehouse, AWS, Amazon Redshift in particular, Apache Airflow, command line environment, and Jupyter notebook.
2. This is your responsibility for monitoring usage charges on the AWS account you use. Remember to terminate the cluster and other related resources each time you finish working.
_3. This is one of the assessing projects for the Data Engineering nanodegree on Udacity. So to respect the Udacity Honor Code, I would not include the full notebook with the workflow to explore and build the ETL pipeline for the project. Part of the Jupyter notebook version of this tutorial, together with other data science tutorials could be found on my _github.
Reference
- Some of the materials are from the Data Engineering nano degree program on Udacity.
- Some ideas and issues were collected from the Knowledge — Udacity Q&A Platform and the Student Hub — Udacity chat platform. Thank you all for your dedication and great contribution to us.
Project Introduction
Project Goal
Sparkify is a startup company working on a music streaming app. Through the app, Sparkify has collected information about user activity and songs, which is stored as a directory of JSON logs (log-data - user activity) and a directory of JSON metadata files (song_data - song information). These data reside in a public S3 bucket on AWS.
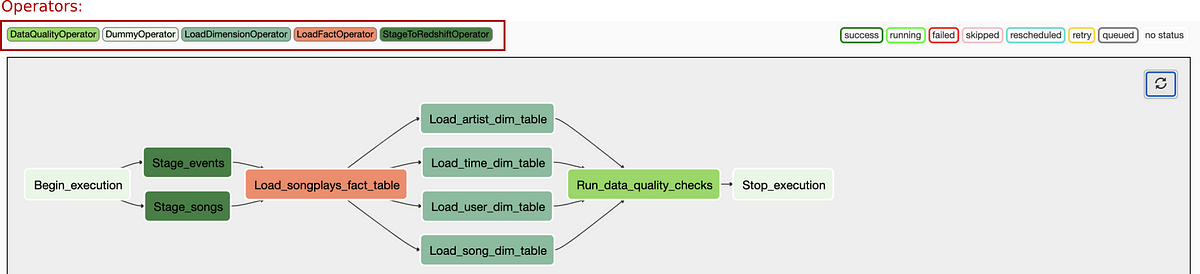
This project would be a workflow to explore and build an ETL (Extract — Transform — Load) pipeline that:
- Extracts data from S3 and stages them on AWS Redshift as staging tables (user activity —
Stage_eventstable and song data —Stage_songstable). - Transforms data from staging tables into a set of fact table (
songplays) and dimensional tables (includingartists, time, users, and songstables) for analytics purposes. More detail about these tables could be found in my other related project. - This high-grade ETL pipeline must be dynamic, could be monitored, and allow easy backfills if necessary. This requirement is satisfied by introducing Apache Airflow into the system.
#airflow #aws #data-science #infrastructure-as-code #programming