Humans have the innate ability to identify the objects that they see in the world around them. The visual cortex present in our brain can distinguish between a cat and a dog effortlessly in almost no time. This is true not only with cats and dogs but with almost all the objects that we see. But a computer is not as smart as a human brain to be able to this on its own. Over the past few decades, Deep Learning researchers have tried to bridge this gap between human brain and computer through a special type of artificial neural networks called Convolutional Neural Networks(CNNs).
What is a Convolutional Neural Network?
After a lot of research to study mammalian brains, researchers found that specific parts of the brain get activated to specific type of stimulus. For example, some parts in the visual cortex get activated when we see vertical edges, some when we see horizontal edges, and some others when we see specific shapes, colors, faces, etc. ML researchers imagined each of these parts as a layer of neural network and considered the idea that a large network of such layers could mimic the human brain.
This intuition gave rise to the advent of CNN, which is a type of neural network whose building blocks are convolutional layers. A convolution layer is nothing but a set of weight matrices called kernels or filters which are used for convolution operation on a feature matrix such as an image.Convolution:
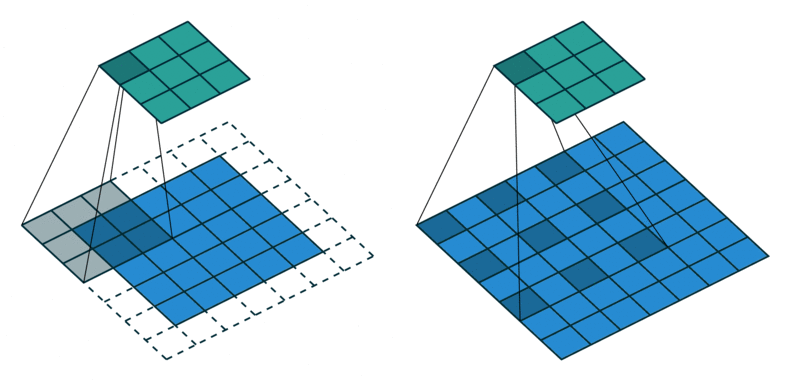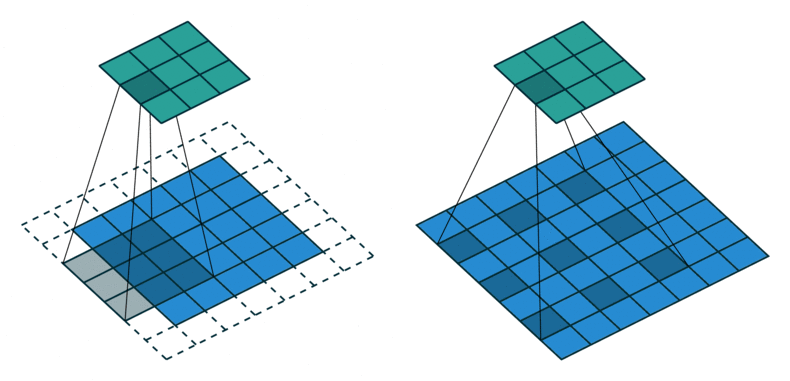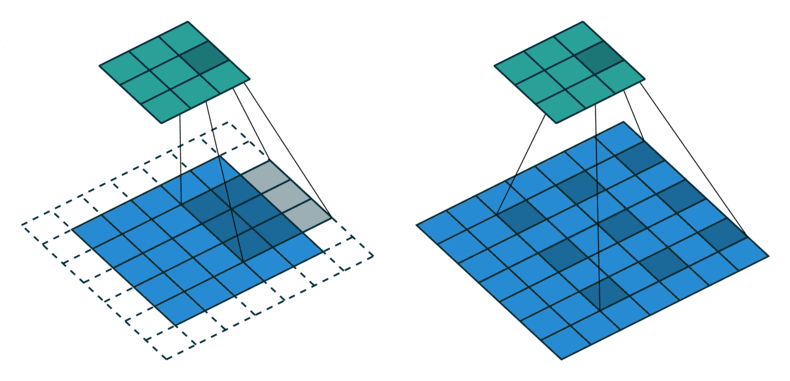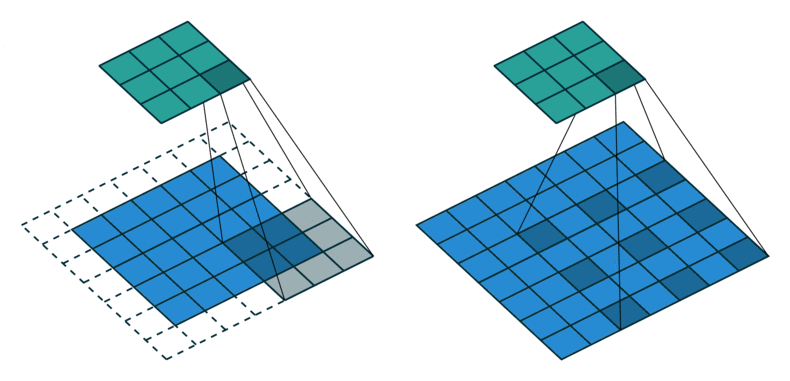
2D convolution is a fairly simple operation, you start with a kernel and ‘stride’ (slide) it over the 2D input data, performing an element-wise multiplication with the part of the input it is currently on, and then summing up the results into a single output cell. The kernel repeats this process for every location it slides over, converting a 2D matrix of features into another 2D matrix of features.
The step size by which the kernel slides on the input feature matrix is called stride. In the below animation, the input matrix has been added with an extra stripe of zeros from all four sides to ensure that the output matrix is of the same size as the input matrix. This is called (zero)padding.
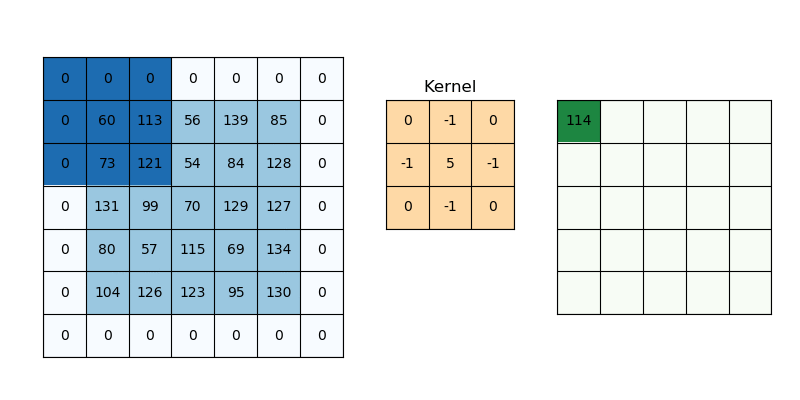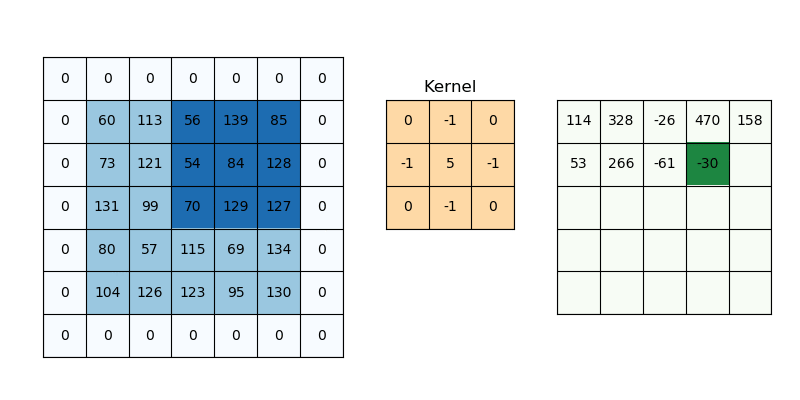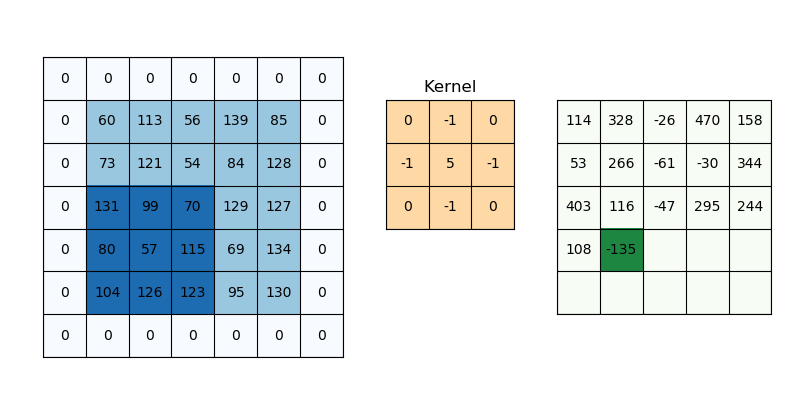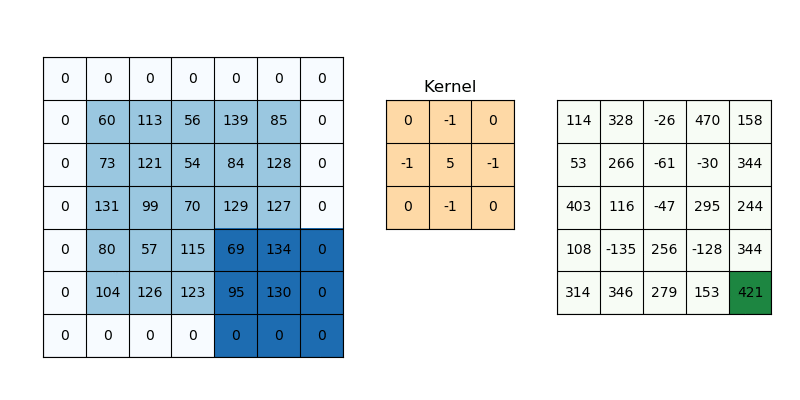
2D Convolution: kernel size=3x3, padding=1 or ‘same’, stride=1
Semantic Image Segmentation
Image segmentation is the task of partitioning a digital image into multiple segments (sets of pixels) based on some characteristics. The objective is to simplify or change the image into a representation that is more meaningful and easier to analyze.
Semantic Segmentation refers to assigning a class label to each pixel in the given image. See the below example.
Note that segmentation is different from classification. In classification, complete image is assigned a class label whereas in segmentation, each pixel in an image is classified into one of the classes.
1. Business Problem
Having a fair idea about convolutional networks and semantic image segmentation, let’s jump into the problem we need to solve.


Severstal is among the top 50 producers of steel in the world and Russia’s biggest player in efficient steel mining and production. One of the key products of Severstal is steel sheets. The production process of flat sheet steel is delicate. From heating and rolling, to drying and cutting, several machines touch flat steel by the time it’s ready to ship. To ensure quality in the production of steel sheets, today, Severstal uses images from high-frequency cameras to power a defect detection algorithm.
Through this competition, Severstal expects the AI community to improve the algorithm by localizing and classifying surface defects on a steel sheet.Business objectives and constraints
- A defective sheet must be predicted as defective since there would be serious concerns about quality if we misclassify a defective sheet as non-defective. i.e. high recall value for each of the classes is needed.We need not give the results for a given image in the blink of an eye. (No strict latency concerns)
2. Machine Learning Problem
2.1. Mapping the business problem to an ML problemOur task is to
- Detect/localize the defects in a steel sheet using image segmentation andClassify the detected defects into one or more classes from [1, 2, 3, 4]
To put it together, it is a semantic image segmentation problem.2.2. Performance metricThe evaluation metric used is the mean Dice coefficient. The Dice coefficient can be used to compare the pixel-wise agreement between a predicted segmentation and its corresponding ground truth. The formula is given by:
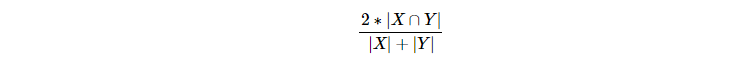
where X is the predicted set of pixels and Y is the ground truth.
Read more about Dice Coefficient here.2.3. Data OverviewWe have been given a zip folder of size 2GB which contains the following:
**train_images**—a folder containing 12,568 training images (.jpg files)**test_images**— a folder containing 5506 test images (.jpg files). We need to detect and localize defects in these images**train.csv**— training annotations which provide segments for defects belonging to ClassId = [1, 2, 3, 4]**sample_submission.csv**— a sample submission file in the correct format, with each ImageId repeated 4 times, one for each of the 4 defect classes.
More details about data have been discussed in the next section.
3. Exploratory Data Analysis
The first step in solving any machine learning problem should be a thorough study of the raw data. This gives a fair idea about what our approaches to solving the problem should be. Very often, it also helps us find some latent aspects of the data which might be useful to our models.
Let’s analyze the data and try to draw some meaningful conclusions.3.1. Loading train.csv file
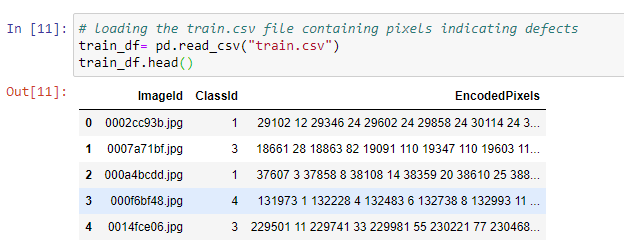
**_train.csv _**tells which type of defect is present at what pixel location in an image. It contains the following columns:
**ImageId**: image file name with .jpg extension**ClassId**: type/class of the defect, one of [1, 2, 3, 4]**EncodedPixels**: represents the range of defective pixels in an image in the form of run-length encoded pixels(pixel number where defect starts pixel length of the defect).- e.g. ‘29102 12’ implies the defect is starting at pixel 29102 and running a total of 12 pixels, i.e. pixels 29102, 29103,………, 29113 are defective. The pixels are numbered from top to bottom, then left to right: 1 corresponds to pixel (1,1), 2 corresponds to (2,1), and so on.
#convolutional-network #semantic-segmentation #computer-vision #dilated-convolution #deep-learning #deep learning