I’m sure that every Data Scientist/ ML Practitioner has faced the challenge of missing values in their dataset. It is a common data cleaning process, but frankly, a very overlooked and neglected one. However, an effective missing value strategy can have a significant impact on your model’s performance.
Reasons for the occurrence of missing values
The reason as to why missing values occur is often specific to the problem domain. However, most of the time they occur from the following scenarios:
- Code Bug: The data collection method encountered a bug and some value were not properly obtained(for example, if you were to collect data via a REST API and you possibly didn’t parse the response properly, then the value would be missing.)
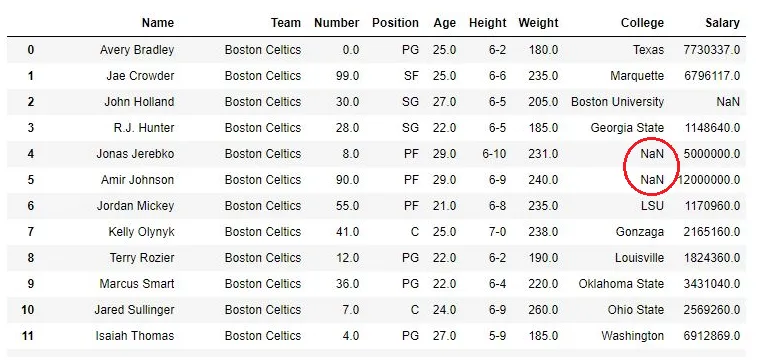
- Unavailability: Not enough data available for a given observation(for example, if there was a feature named “College”, but the observation(person/athlete etc) did not attend a College, then obviously the value would be empty.)
- **Deliberate NaN imputation: **this can occur in coding competitions such as Kaggle, where part of the challenge is to deal with missing values.
The reason you should deal with missing values is because many ML algorithms require numeric input values, and can’t operate with missing values, therefore if you try run the algorithm with missing values, it will respond with an error(scikit-learn). However, some algorithms, such as XGBoost, will impute values based on training loss reduction.
#data #machine-learning #artificial-intelligence #data-visualization #data-science