What is Representation Learning?
Representation learning is an area of research that focuses on how to learn compact, numerical representations for different sources of signal. These signals are most often video, text, audio, and image. The goal of this research is to use these representations for other tasks, such as querying for information. A well-known example of this is when searching for videos on YouTube: a user provides text keywords resulting in YouTube returning a set of videos most similar to those words.
In computer vision literature, representations are learned by training a deep learning model to embed (or transform) raw input to a numerical vector. When embedding videos, audio, or text, the numerical vectors are often multi-dimensional to maintain temporal relationships. The ways in which researchers train these model varies drastically. The downstream tasks are how these methods are evaluated and are the focus of this article.
Datasets
Many of the papers that I have read use the dataset HowTo100Mto train the model. This corpus contains a total of _1.2 million videos _with a range of 23k activities! The types of activities are diverse, ranging from cooking to crafting to fitness to gardening, and much much more. This dataset is HUGE, and would take a long time for the average researcher to train a model with. However, if you have the computation power, it is a great dataset to use for representation learning. Each video contains a short description of the task and a set of captions that were automatically generated. From my experience, and the experience of the original researchers, the captions are very noisy with alignment issues coupled with inaccurate audio-to-text translations. The short task descriptions are not ALWAYS accurate or are extremely general. However, this is because of the YouTube extraction, not the fault of the researchers.
For each downstream task there are datasets that have annotations specific for the task’s evaluation. These are datasets that have a smaller set of videos focused on a smaller set of activities.
Datasets
Datasets that are great for text-related video tasks are:
YouCook2 is a cooking based dataset of 2K untrimmed videos of 89 cooking recipes with step-by-step annotations. This dataset also includes temporal boundaries that are useful for temporal targeted tasks. MSR-VTT is a more general dataset of 10K video clips with 200K human annotated clip-caption pairs on 257 different topics. While not specifically instructional, the LSMDC dataset contains 101k unique video clip-caption pairs with descriptions coming from either the movie script or audio description.
Datasets more commonly used for action-related video tasks are:
CrossTaskcontains 2.7k instructional videos with step-by-step action annotations for each frame. COINis also a general instructional video dataset with 11,827 videos showing 180 tasks with annotations associated with the actions that occur during the video.
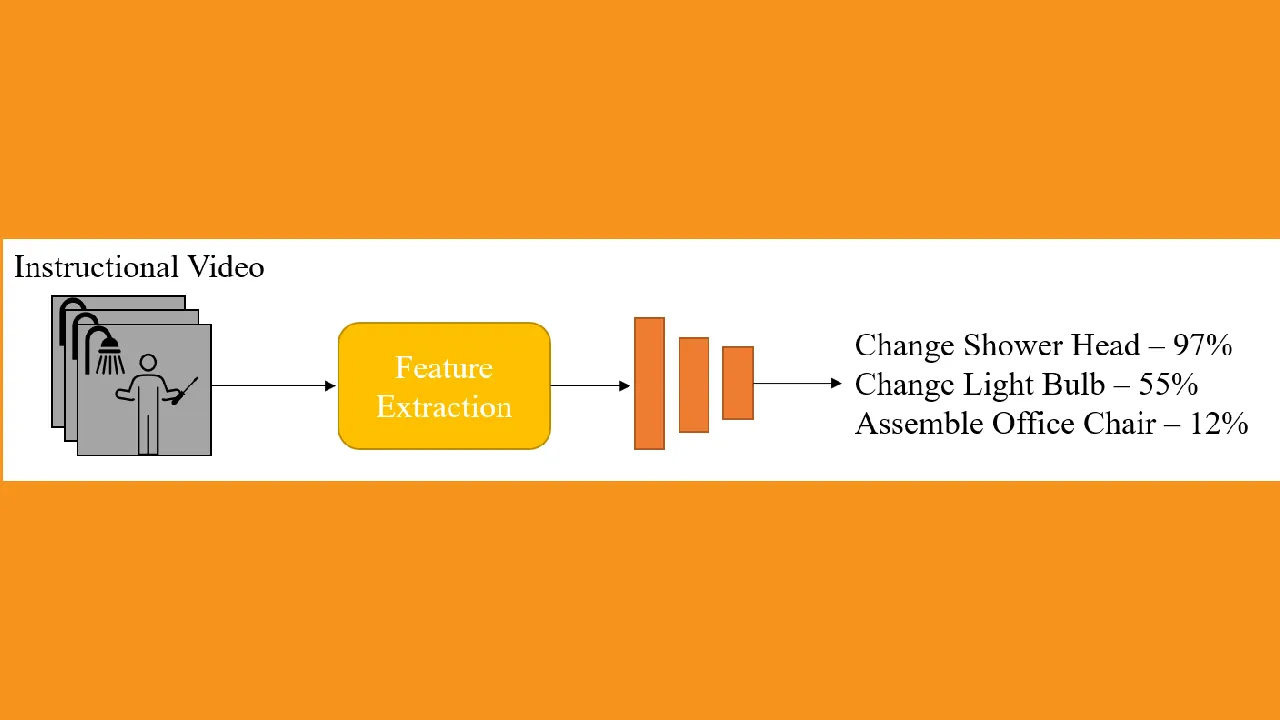
Downstream Tasks
Video/Action Classification
The quickest downstream task to set up is a classification task for the entirety of the video, or a trimmed version. The goal of this task is to have high accuracy on classifying a given video to the complex action it is showing. The goal is that the average accuracy across all classes is high. Some visualizations that help show this space is clustering. Ideally videos from the same class should be near the same cluster. To modify the original model for this downstream task, you add a small feed-forward network that outputs _d=the number of classes. _A **zero-shot **experiment would mean that you do not train this modified network on the downstream dataset but only test. It is more common, however, to train for a handful of epochs to update the parameters of the new layers from being random. Measuring accuracy is based on the number of videos accurately classified over the total number of videos.
#video-retrieval #action-learning #model-evaluation #deep-learning