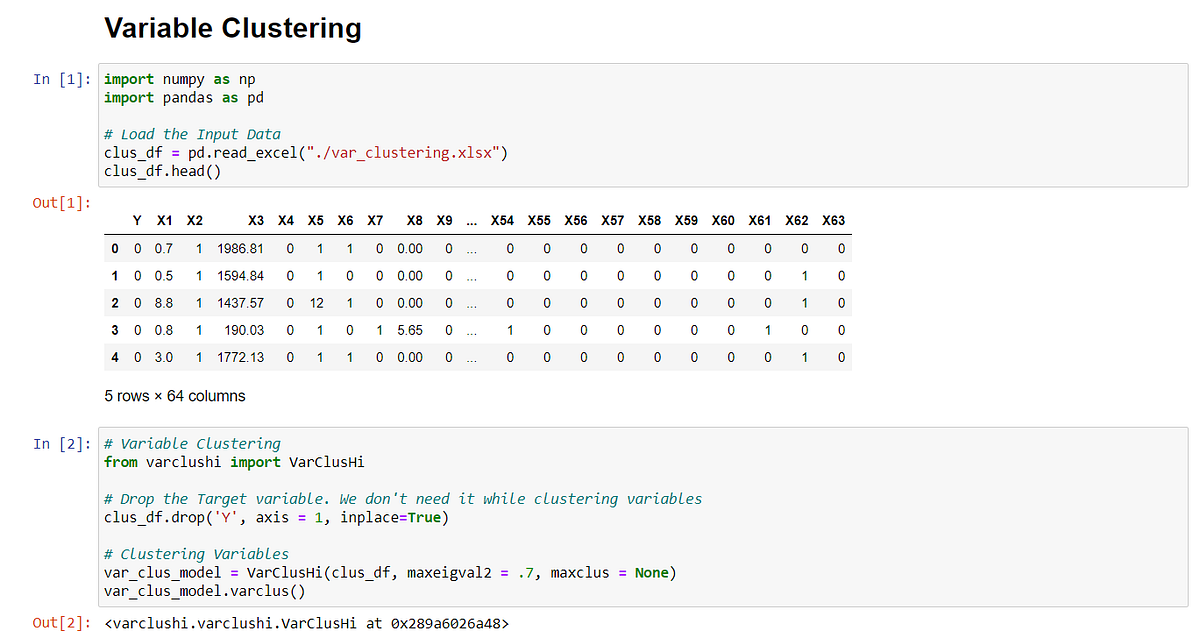
Hello Everyone,
In this article, I am trying to showcase my understanding of the Variable Clustering algorithm (the most popular technique for dimension reduction).
Disclaimer: This article is aimed to share my knowledge of Variable Clustering. This does not include any project-related data, codes, and so on. SAS/Python codes used in this article are purely based on publically available datasets and not relate to any company project. The reader of this article must have a background in Statistics, SAS, and Python
The complexity of a dataset increases rapidly with increasing dimensionality. It increases the computation time, affects the ability to explore the model relationship, model scoring, increases the redundancy in the dataset, and so on.
One of the remedial measures can be Variable Clustering. It finds a group of variables that are as correlated as possible among themselves within a cluster and as uncorrelated as possible with variables in other clusters.
OK. Now, let’s understand how it is done.
PCA — Principal Component Analysis is the heart of the algorithm. Let us understand how it works.
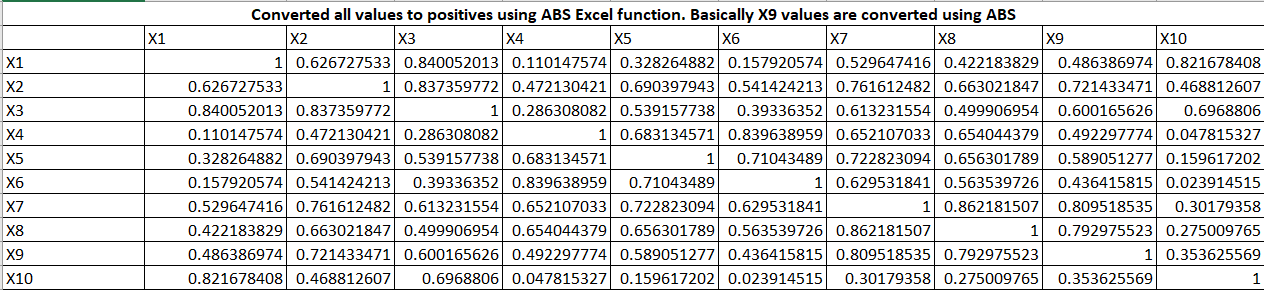
Suppose, we have 10 variables and their correlation among themselves are as follow:
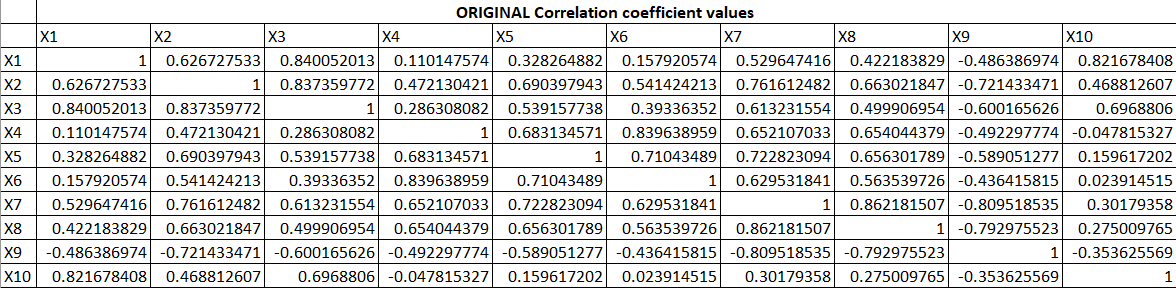
Table 1
#machine-learning #statistics #python-pandas #unsupervised-learning #data-science #python