And here we are, the final project of my Metis Data Science Bootcamp. The first four projects I’ve done are as follows:
- MTA Turnstile Data: My First Taste of a Data Science Project
- MyAnimeList user scores: Fun with web scraping and linear regression
- Is a trawler fishing? Modelling the Global Fishing Watch dataset
- Identifying fake news: The LIAR dataset and its limitations
This time round, my aim is to generate short poetry by feeding a poetry corpus into a Long-Short-Term Memory (LSTM) neural network.
TL;DR:
- Retrieved a corpus of 3-line poetry
- Trained an **LSTM model **with two approaches: cleaned word sequences; and raw word sequences paired with Stanford’s GloVe embeddings
- Training on cleaned word sequences produced poetry that didn’t quite make sense; training with GloVe embeddings produced much better results, but inconsistently
- Next steps would be to try additional seeds, additional features, different model hyperparameters, and a larger and/or improved poetry corpus
I. Background
For my capstone, I wanted to find a way to marry my burgeoning skills in machine learning with my existing interest in poetry (both reading and writing; incidentally a collection of my haikus on Instagram can be found here).
One of the haikus from my Instagram account, paired with a photograph that I took.
Generative poetry seemed like a good place to start. Beyond the appeal to my interests, however, such a model can have practical applications:
- It can be used as a **spur **for further poetry and creative writing
- If poems can be generated based on themes/images, this can have broader applications in various domains, for example in advertising and marketing.
II. The dataset
For this project, I used the dataset of 3-line poems put together by Jeremy Neiman for his own post on generative poetry; in his case he focused on generating haikus (hence the restriction to 3 lines).
Generating Haiku with Deep Learning
Using neural networks to generate haiku while enforcing the 5–7–5 syllable structure.
This dataset was in turn put together from various other datasets as follows.

31,410 poems in total
III. The model
I used Keras to put together an LSTM neural network model that takes in a sequence of 15 tokens and outputs the next token (or more accurately the probabilities of the next token). The model structure is illustrated below.
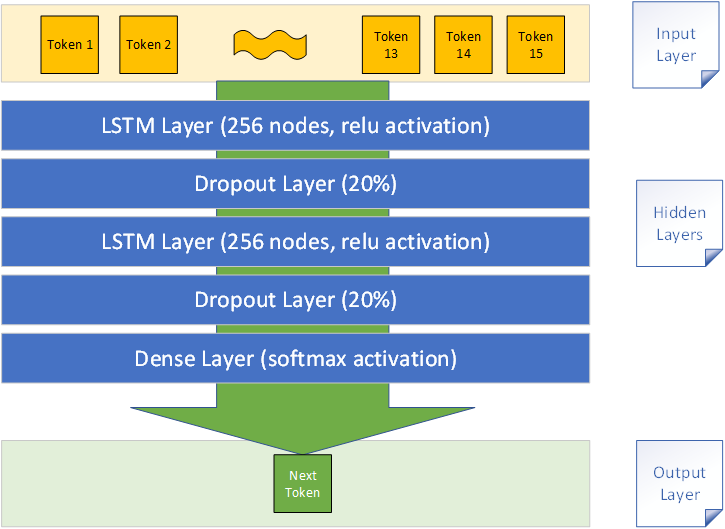
My LSTM model
Using this model, I tried out two approaches as follows, training for 200 epoches:
a) Word tokenization with cleaned words
With this approach, I first cleaned the words by lower-casing them and removing all non-alphanumeric characters; I kept stop words as they could have meaning in poetic contexts.
Capital letters and punctuation can have poetic meaning as well, though arguably not as much, so I decided to ignore them in this approach.
I then processed each poem into a series of 15-token sequences:
- The first sequence for a poem would be the first word padded with 14 blanks.
- Each subsequent sequence would push the next word into the sequence, dropping the excess token. So for instance the second sequence would be the first two words padded with 13 blanks.
- Special tokens were used for end-of-line and end-of-poem.
The resulting sequences for all poems were then concatenated. The diagram below illustrates this process.
#nlp #metis #bootcamp #deep-learning #poetry #deep learning
