“Recipe Guru” uses NLP technologies to recommend similar recipes to the ones one might like, currently based on 18000 recipes out of Recipe 1M+. Under the hood, this web app uses Recipe 1M+ data and natural language processing (NLP) models to recommend recipes based on the ones the user likes.
It uses a similarity matrix to document similarities between recipes based on title, ingredients, and instructions. Bag of Words (BoW), Doc2Vec, and BERT (Bidirectional Encoder Representations from Transformers) models are used to estimate degrees of similarities between recipes and provide recipe recommendations. (Here is my medium blog post that talks about BERT and other recent NLP technologies, including XLNet. )
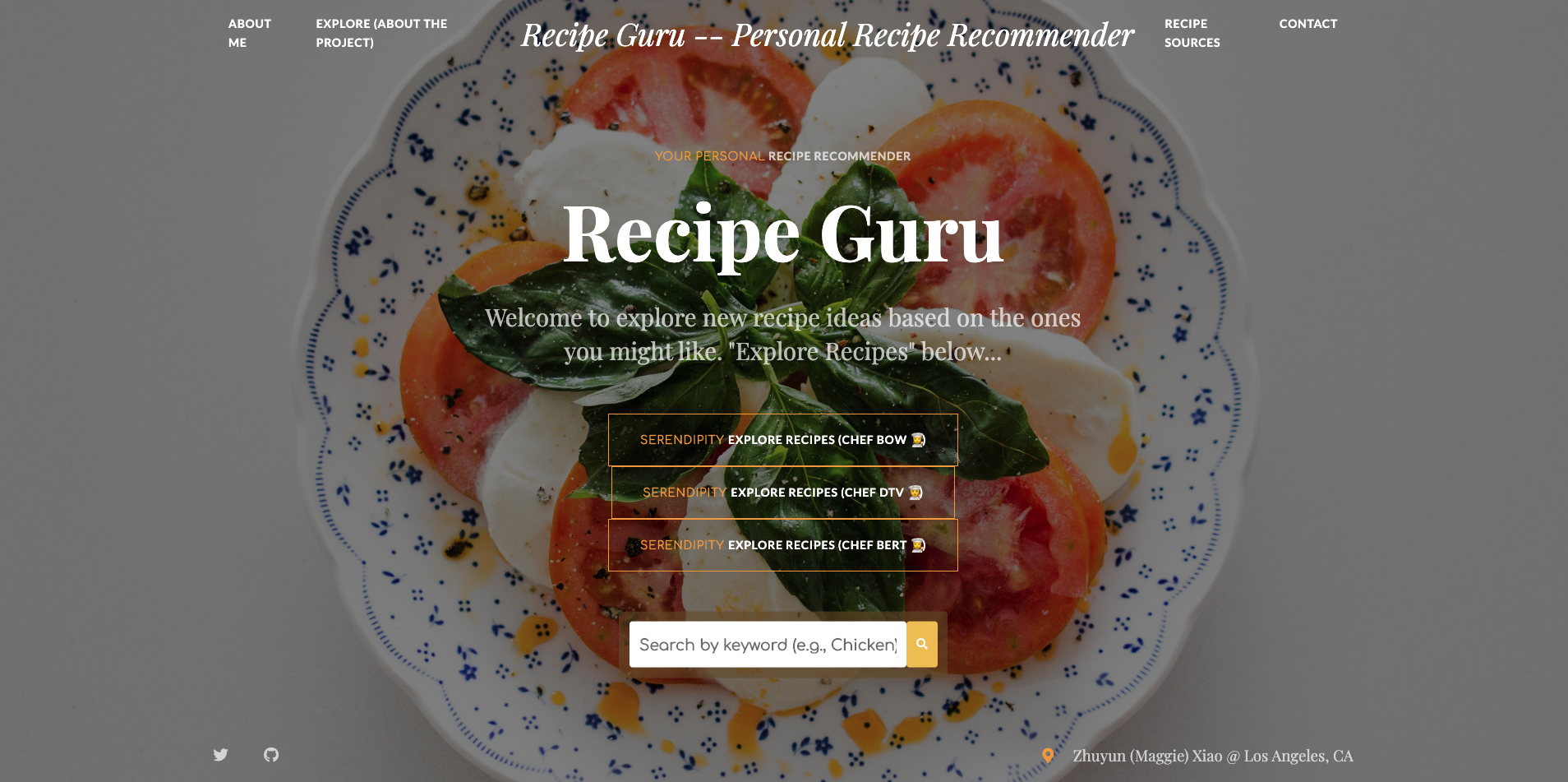
Home Page of the “Recipe Guru” with different chef recommendation options based on three NLP techniques.
About the Data Set
For this project, I used the Recipe 1M+ dataset from MIT researchers: a new large-scale, structured corpus of over one million cooking recipes and 13 million food images. The dataset can be used for NLP and CV projects. Here, we focus on the text recipes (comes in JSON) that include the following information: the recipe URL, title, id, ingredients, and instructions.
The preprocessing step combines title, ingredients, and instruction into one string for each of the 1M+ recipes and different Natural Language Processing techniques are applied on the clean dataset to generate embeddings and cosine similarity matrix.
Cosine Similarity Matrices
Due to the large size of the cosine similarity matrix, rather than using the sklearn function “metrics.pairwise_distances” and scipy’s “spatial.distance.cosine” to get pairwise cosine similarity, I used TensorFlow and GPU to speed up the cosine similarity matrix calculation and also tried using Spark distributed computing.
1. Getting the cosine similarity matrix with TensorFlow:
import tensorflow as tf
## use tf rather than sklearn.metric
def compute_cosine_distances(a, b):
## x shape is n_a * dim
## y shape is n_b * dim
## results shape is n_a * n_b
normalize_a = tf.nn.l2_normalize(a,1)
normalize_b = tf.nn.l2_normalize(b,1)
distance = 1 - tf.matmul(normalize_a, normalize_b, transpose_b=True)
return distance
## similarity matrix (tensorflow.python.framework.ops.EagerTensor)
sim_matrix = 1 - compute_cosine_distances(recipes_vector, recipe_vector) ## recipe vector shape: (18000, 5200)
sim_matrix = np.array(sim_matrix)
## replace all perfect matches (match with itself) to zero, fill diag with 0
## so the recipe closest to the target recipe won't be itself during ranking
np.fill_diagonal(sim_matrix, 0)
## for the 1st recipe, check sim_matrix[0]
recipe1 = sim_matrix[0]
## get the index of the top N recipes recommendations based of their closeness to recipe1
most_similar_recs = np.argpartition(recipe1, -N)[-N:]
One side note about storing the large cosine similarity matrix (a few GB for a 20k * 20k matrix with information on 20k recipes), one way to efficiently store it is to keep the indices of non-zero entries by converting the matrix into a sparse matrix. You can check out more about handling sparse matrices in the SciPy docs.
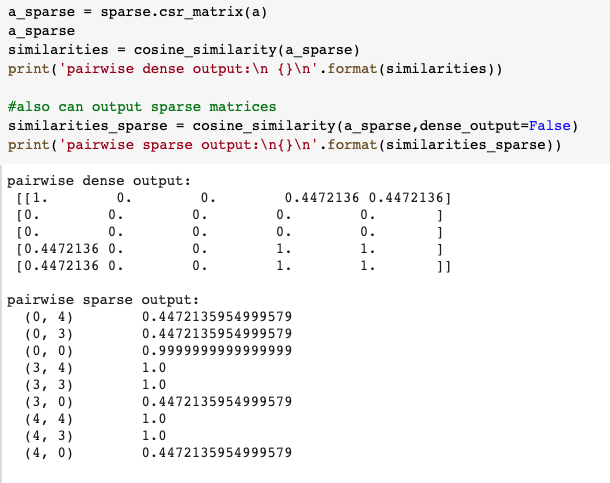
An example of saving sparse matrices
Since I am going to deploy the web app along with the pickled cosine similarity matrices, I am concerned about the large file sizes (1–2 GB). So before converting to csr_matrix, I set the similarity score of recipes with the target recipe to 0 if the score is not in the top 10. Then we only need to pickle ~recipe_num * 10 elements in the compressed sparse row formatted matrix. The file size goes from 1.67 GB to 2 MB :D. By the way, I ran into this medium post today on his journey of pickling large NLP data files, hopefully, it can also help you if you are facing similar deployment issues.
sparse.csr_matrix(sim_matrix)
## <18000x18000 sparse matrix of type '<class 'numpy.float32'>' with 202073252 stored elements in Compressed Sparse Row format>
## Let's keep top 10 elements of each row whose indices are of the recipes to be recommended.
for i in range(len(sim_matrix)):
row = sim_matrix[i]
## cos sim of top 10th element
threshold = heapq.nlargest(10, row)[-1]
row[row < threshold] = 0
sparse.csr_matrix(sim_matrix)
## <18000x18000 sparse matrix of type '<class 'numpy.float32'>' with 202070 stored elements in Compressed Sparse Row format>
#data-science #nlp