About This blog post
This blog post provides an explanation of GPT-3 [1]. The summary of the content is as follows.
- In GPT-2, the predecessor of GPT-3, the authors built a language model with a huge dataset and a huge network, and they got good results without having to train it in each task.
- In GPT-3, the authors built a language model with an even bigger dataset + an even bigger network, and got great results when the model see dozens of samples.
- On the other hand, the limitations of scaling up the language model alone for various tasks are becoming apparent.
- There are also issues of bias towards race, gender, and religion, as well as challenges against willful misuse.
This article goes as follows.
1. Description of the Transformer, GPT-2
2. Concept and Technical Description of GPT-3
3. Tasks that work well using GPT-3
4. Tasks that do not work well using GPT-3
5 . Views on bias and misuse
Transformer
Before we get to GPT-2, the predecessor of GPT-3, let’s take a look at the Transformer Encoder[2] that was used in it. The proposed model, with a provocative title for those who loved LSTM/CNN, also made a splash.
It’s a mechanism called dot product Attention, which is neither CNN nor LSTM, and it’s a model that stacks them together (Transformer), and it far outperforms existing methods.
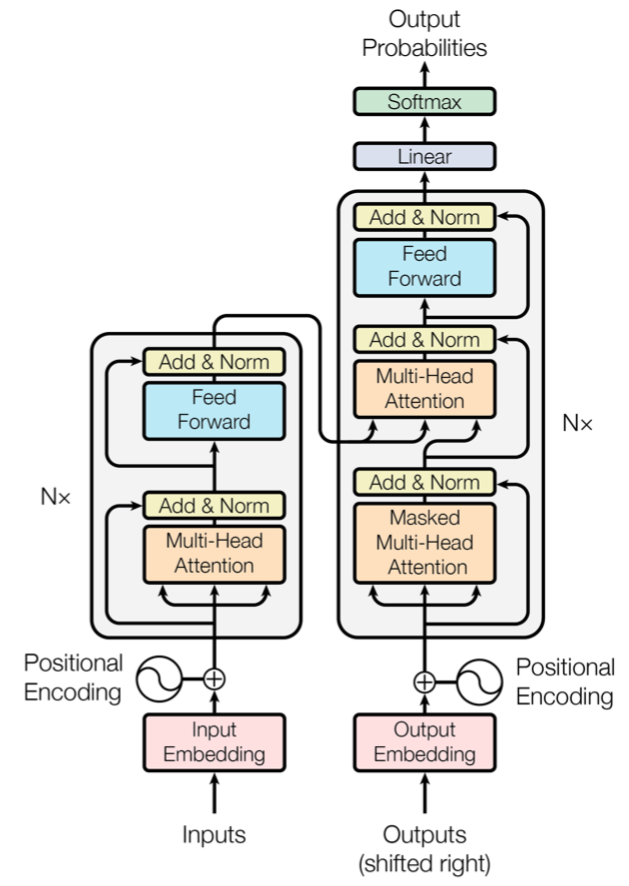
Taken from [2], an overview of the Transformer model
There are three variables, Query, Key, and Value, in (dot-product) Attention that are used in the Transformer. Simply put, the system calculates the Attention Weight of the Query and Key words, and multiplies each Key by the Value associated with it.

dot product attention
Multi-Head Attention, which uses multiple Attention Heads (in term of MLP, the “number of hidden layers” is increased), is defined as follows. The (Single Head) Attention in the above figure uses Q,K as it is, but in the Multi-Head Attention, each Head has its own projection matrix W_i^Q, W_i^K, and W_i^V, and the features projected by these matrices are used to create the Attention.
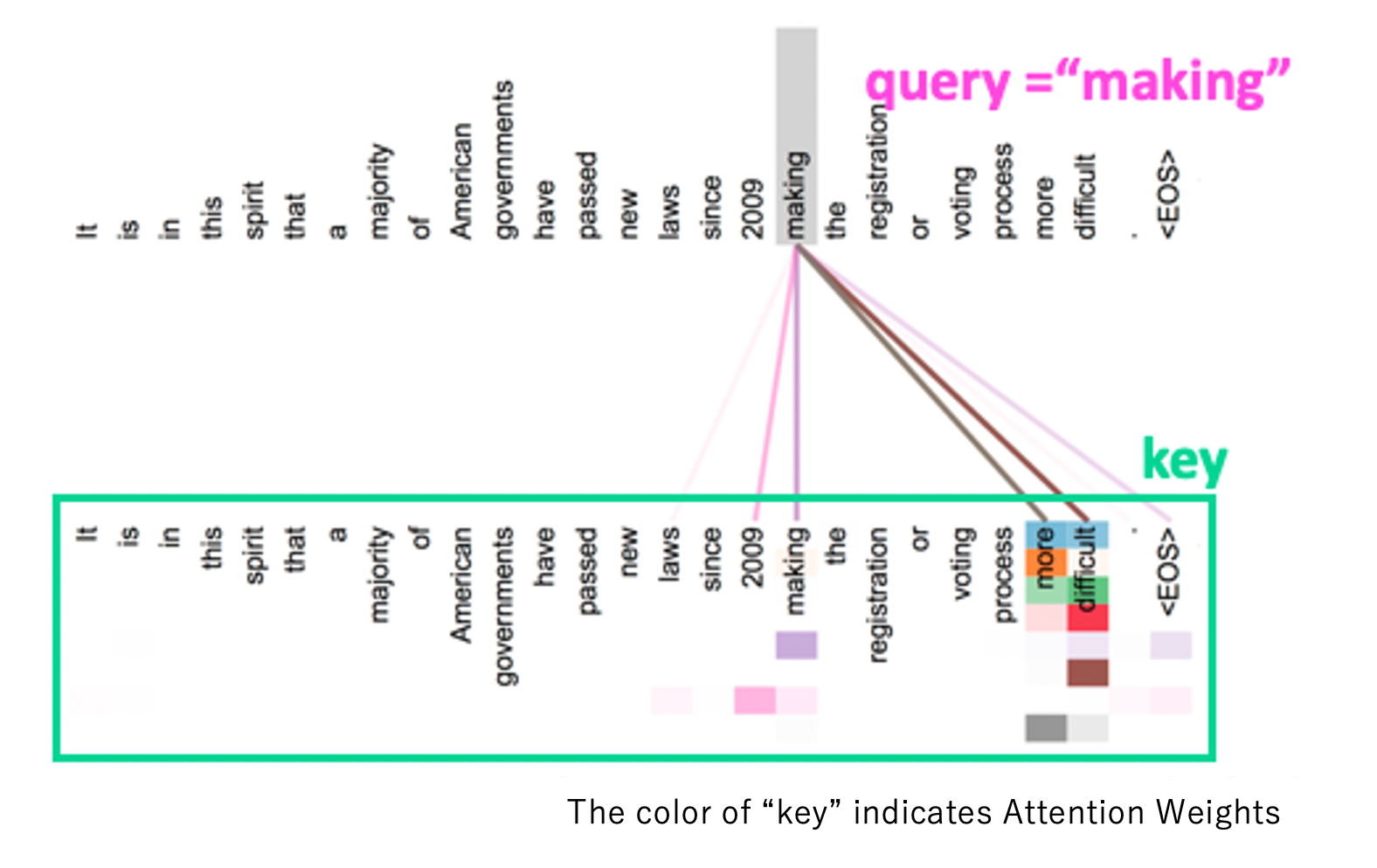
The Q, K, and V used in this dot product Attention are called Self-Attention when they are all derived from the same data. This is called Self-Attention when the Q, K, and V used in this dot product Attention are derived from the same data. In Transformer, the part of the Encoder and the part below the Decoder are Self-Attention. The upper part of the Decoder is not Self-Attention because the Query is brought from Encoder and the K,V are brought from Decoder. The following figure shows the example of attention weights. In this figure, the word “making” is used as a query and the Attention Weight for each key word is calculated and visualized. The each keys in attention heads are learning different dependencies. the words of “key” are colored in multiple ways to represent the Attention Weight of each head.
GPT-2
GPT-2 is a research on autoregressive language models using huge datasets and highly expressive language models, and the language models are used as they are to solve various tasks (zero-shot). It consists of three elements: “zero-shot by autoregressive models”, “large scale models” and “a large dataset”.
autoregressive language model and zero-shot
An autoregressive language model refers to a model that defines the probability of occurrence of the next word using the words that have appeared before.
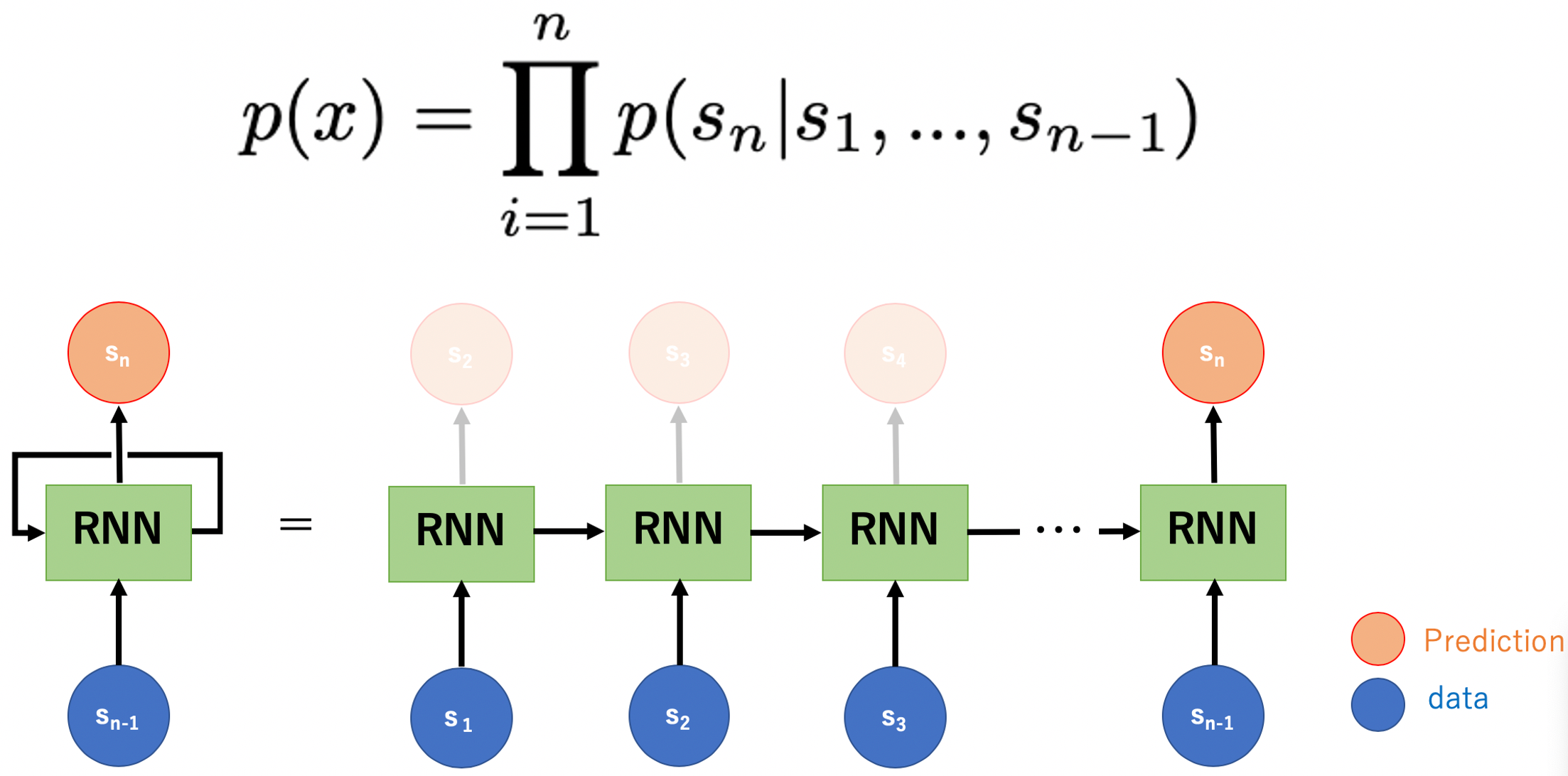
Conceptual diagram of an autoregressive language model using RNN. The probability of occurrence of the nth token (word) s_n in sequence x is defined by the conditional probability of s_1~ s_(n-1).
The “zero-shot” method used in GPT-2 is use a language model’s next word predictions as answer of a task. For example, if you want to translate the word “cheese” from English to French as shown in the figure below, you can use s_1~s_(n-1) as “Translate English to French: cheese =>”, and s_n as “fromage” which means cheese in French as output.

translation using zero-shot
Highly expressive large scale models
In GPT-2, instead of RNN, the authors use the aforementioned Transformer’s Encoder block (Multi-head Attention + Feed Forward = Transformer Encoder), which is highly expressive, to construct an autoregressive language model. However, instead of using it as it is, they changed the initialization and the network structure slightly. The network structure has been changed from the original Transformer Encoder (on the left figure) to the Transformer Encoder (on the right figure), as shown in the following figure.
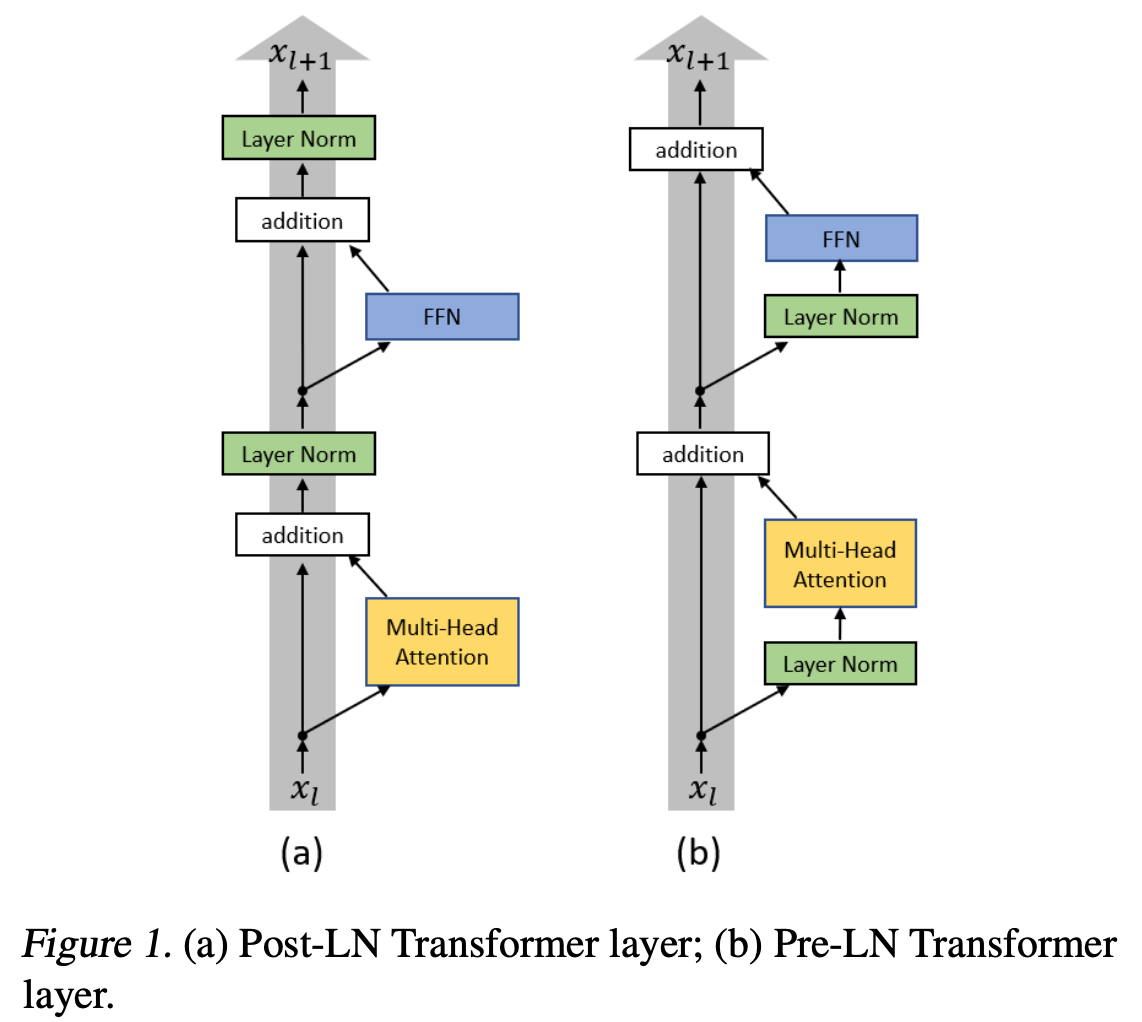
Quoted from [4], where the Pre-LN Transformer structure is used in GPT-2
The benefits of this structure are discussed in detail in the paper “On Layer Normalization in the Transformer Architecture”[4]. In the original structure, the transformer must use a technique called “warm up”, which allows a small learning rate in the early stages of training (from a few hundred to a few thousand steps) to be used in order for the transformer to learn well (see left-hand side below). On the other hand, the Pre-LN Transformer structure used in GPT-2 ( the name of “Pre-LN” is not used in the GPT-2 paper because the GPT-2 paper was published earlier) limits the size of the gradient by the depth of the layers (L), which makes it possible to train the transformer without warming up and increases the accuracy (see Figure below, right). By the way, if you use Rectified Adam (RAdam), which is an Adam that does not need warm up, you can learn without warm up.
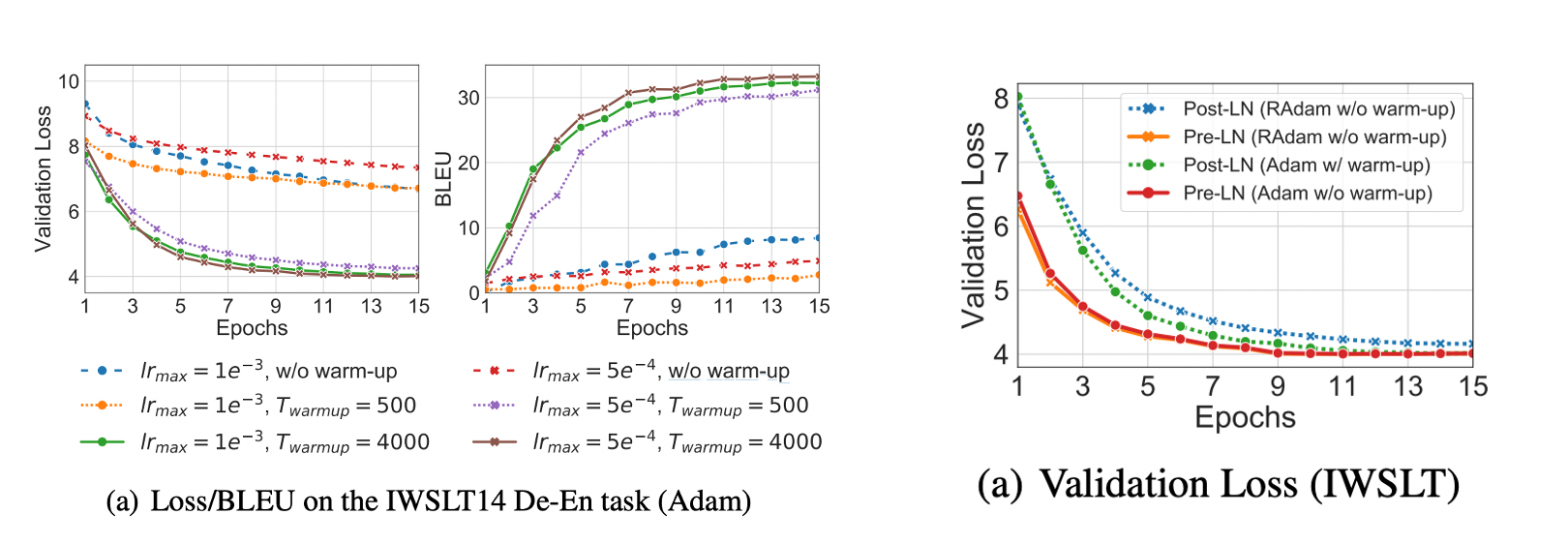
Quoted from [4]. (Left) Accuracy and accuracy with and without warm up in Post-LN, the original structure. (right) Pre-LN, the structure adopted by GPT-2, when it is trained without warming up.
GPT-2 proposes four different sized models, and uses the modified Transformer Encoder mentioned above, up to 48 layers. Considering that the original Transformer has only 12 layers (6 layers for Encoder and 6 layers for Decoder), you can see that this is a very large model. In terms of the number of parameters, the largest model has 1.5 billion, which is about 25 times larger than ResNet152 (about 60 million parameters), which is often used for single-image tasks.

Quoted from [3]. Four different sizes are available.
A large dataset
They are using a large dataset called WebText for GPT-2 training. As the name implies, this is a set of text data fetched from the web, and it’s a huge dataset of 40 GB in total, containing 8 million documents.
As an aside, on image tasks, there is a trend to achieve high accuracy using large datasets and large models too. And a famous one is BiT [7]. In this study, a huge pre-trained model trained with a huge dataset showed high performance in fine-tuning. The model has 4 times the number of ResNet152 channels and is trained with 300 million data JFT-300M for several months. The results show that fine-tuning can be done with a small amount of data and optimization is fast and efficient.
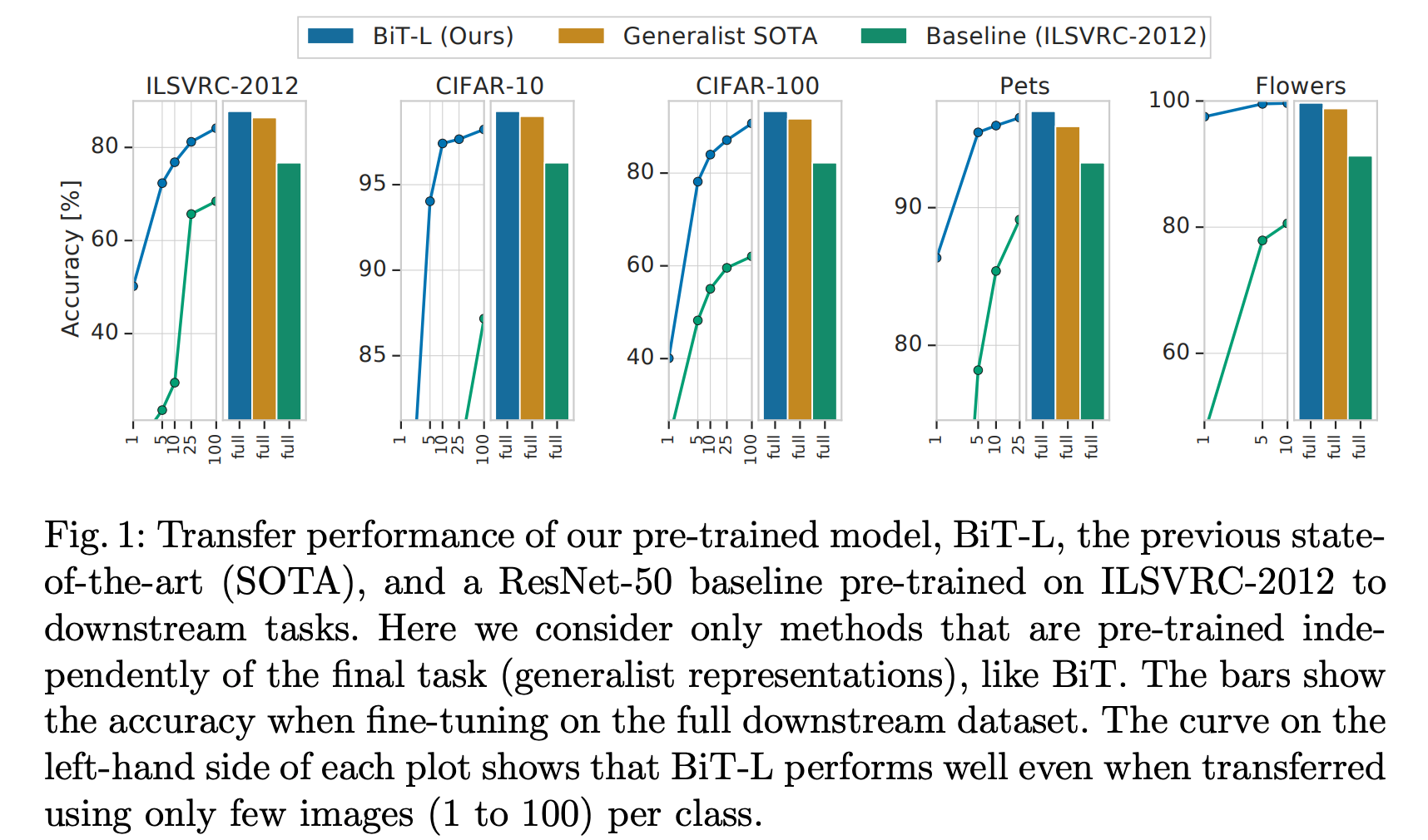
Quoted from [7]
GPT-2 Results
The table below shows the results by GPT-2, which consists of three components: “zero-shot by autoregressive models”, “large scale models” and “a large dataset”. It has updated SOTA with various datasets. Note that GPT-2 did not use fine-tuning or even few-shot learning on each dataset, showing that, as the title of the GPT-2 paper suggests, “Language Models are Unsupervised Multitask Learners”.
#gpt-3 #nlp #deep-learning #deep learning
