Web scraping and data analysis of an F1 season with Beautiful Soup and Pandas

Source: Unsplash.com
Data is everywhere
Sometimes as a data scientist, you won’t have the data you require at your fingertips, or there is no existing pipeline feeding you the data you need. At other times, you might simply be interested in exploring an area that doesn’t have a freshly scrubbed dataset available. Fortunately, the internet has an intergalactic ocean of data (in case you didn’t already know) on virtually any subject you could wish to analyse, and Python has all the tools you need to scrape and format that data for your chosen project.
For me, the subject I’m going to explore here, and in some future posts, is historical Formula One results. For the uninitiated, F1 is the elite motorsport category in the world in which legends like Aryton Senna and Michael Schumacher wrestled their 200mph steeds in wheel-to-wheel combat!
Luckily for me, the official formula 1 website contains archived data from F1 championships, beginning in 1950, up to the present day. Races results, qualifying times, championship positions and many other results are there in the archive (see below) and it is easy to navigate the website to find any information you’re interested in.
Source: screenshot of formula1.com webpage
Before I get you revved up too high on all this F1 stuff, let’s use Python to extract some information from the archive and display it with Pandas.
Beautiful Soup
Beautiful Soup is a great package for parsing the HTML data making up a webage into a more readable and useable format. I used Beautiful Soup, urllib and Pandas to scrape data from the F1 archive and present it in a DataFrame. Some of the historical data is a little sparse if we go further back in time circa 1950, so for the moment I am going to begin in 1990 —that is, with modern era F1 and comprehensive data on results.
Starting with something simple, I decided to scrape the overall championship placings from 1990 and plot the results. First, I used **urllib.request.urlopen() **to open the webpage containing the 1990 driver’s championship results (you can navigate to the relevant webpage and copy the link). Then I used the find_all() method with the ‘table’ argument to search for tables contained in the webpage (here there is only one). Finally, I used the Pandas method read_html() to transform the data into a DataFrame. This is a really useful method for anyone scraping data from a webpage for subsequent analysis as it makes it simple to begin working with Pandas functions immediately.
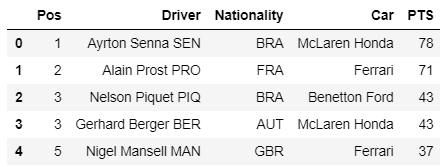
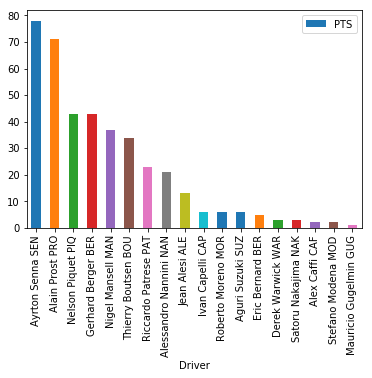
Source: plot made for this post (Ciaran Cooney)
Okay, so I successfully extracted some data from a website, and although we can see that Aryton Senna beat Alain Prost to the 1990 F1 world title, there is nothing terribly interesting here!
#formula-1 #beautifulsoup #web-scraping #python #data-science