YOLO_ object detection algorithm which can perform classification and object localization(detection) at the same time, looking at the image just once. Hence, the name of the algorithm is You Only Look Once._
1. Introduction
Over the years, the field of computer vision has been living and growing with us, from Instagram filters, Google Lens to Tesla cars which are the products inspired by the creation of computer vision algorithms. In this article, I will explain to you the working principle behind the most popular object detection algorithm YOLOv3. But before that, let me try and explain the difference between, classification task vs object detection.
Note: All the 3 versions of YOLO have a similar working principle, with minor changes in the network architecture which aid in an overall improvement of its performance.
Prerequisites
To thoroughly understand this article
- You should understand the working behind Convolutional Neural Networks.
- Be able to construct simple neural networks with ease.
- Most importantly, the desire to learn.
2. Classification vs Object Detection
**Classification **is the task of predicting the class of object in the image. For example, an image classification network trained to classify a deck of cards, or differentiate between an image of a cat vs dog.
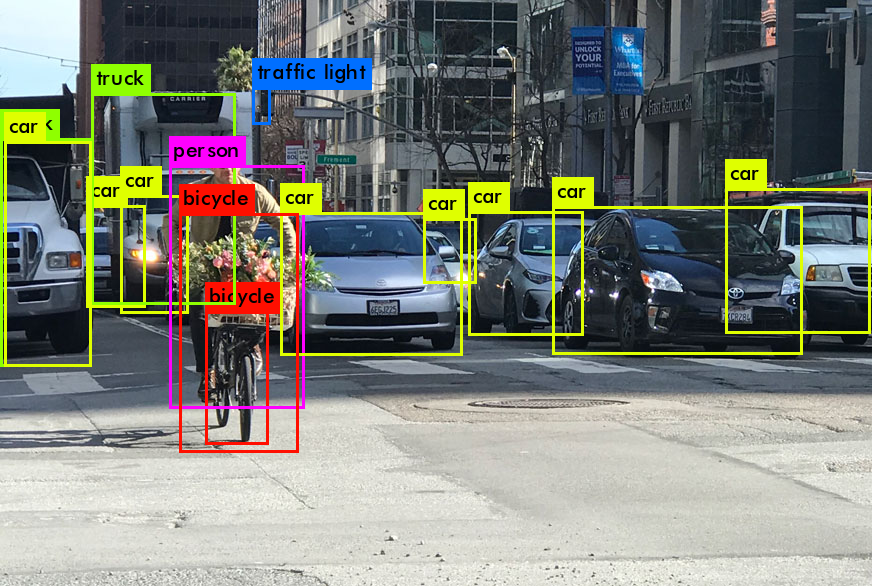
Object detection is the task of identifying the location of the object as well as the class of the object in the image. The object in the image is enclosed in a rectangular box indicating the class of the object as well.
For example, if one wants to count the number of cars at a traffic junction or count the number of faces while clicking a selfie, the task of object detection is employed. The task of classification cannot be applied directly on an input image feed in real-world scenarios, it is always accompanied by the task of detection or segmentation.

3. Working Principle of YOLO
YOLO uses a single CNN to predict the classes of objects as well as to detect the location of the objects by looking at the image just once. Let us first look at the network architecture of YOLO.

Let me try and describe the above diagram (fig 1) in words, YOLO network accepts an image of fixed input dimension. Theoretically, YOLO is invariant(flexible) to the size of the input image. However, in practice, we resize our input to a fixed dimension of 416x416 or 608x608. Doing this allows us to process images in batches (images in a batch can be processed in parallel by GPUs) which help us train the network faster.
Multiple convolutions are applied to the image as it is propagated forward through the network learning the features, colour, shape & many more aspects of the object. At each layer, we obtain a convoluted image aka feature map of that layer. The output of a CNN layer is a 3D feature map. Each depth channel encodes a feature of the image or object.
To learn more about the feature maps.
After a certain number of convolutions when the network stride reaches 32, we get the output feature map, the layer we obtain it from is called a detection layer.
3.1 How is this output feature map interpreted?
Output feature map is the resultant tensor representing the features learned by all the preceding convolutional layers, as it passes the image from the input layer to the detection/output layer. The** output/detected feature map **is of 13x13x125.
3.2 Let’s break down to see what’s inside it.
13 is the width and height of the output feature map. Each cell (square) in the 13x13 can see a region/portion of the input image as a result of the convolutions that took place. This is called a receptive field.). The** receptive** field of the network is the region of the input image that is visible to a cell (neuron) in the output feature map.
Also, each cell in the 13x13x125 feature map has 5 bounding boxes to detect the objects in the image. A cell can detect an object in the image via one of its 5 bounding boxes only if the object falls within the receptive field of that cell (Receptive field is the region/portion of the input image visible to that cell).

fig 2
To do that, YOLO divides the input image into 13x13 grids. Each cell in the 13x13x125 output feature map represents each corresponding 13x13 grid of the input image. (Say, red cell of feature map represents the red grid on the dog’s image). (Each square 13x13 on the dog’s image is referred to as a grid & each neuron on the 13x13 feature map is called as a cell.)
Now as each cell in 13x13x125 has 5 bounding boxes, these bounding boxes can be localised (used to locate objects) using this 13x13 grid on the input.

If the centre/midpoint of the object falls within a particular grid (red grid contains the midpoint of the dog) that grid is responsible for detecting the object.
In simpler terms, the bounding boxes which enclose an object or a part of an object are the boxes that will be used to detect/localise the objects in the image. These boxes have a higher confidence score than others.
3.3 Now coming to the 3rd dimension in the tensor, 125. What does this represent?
This is where the actual output predictions are enclosed. As discussed each cell in the 13x13x125 feature map has 5 bounding boxes to make predictions.

Each bounding box is represented by its,
- centroid-x (tx), centroid-y (ty), bounding-box-width (btw), bounding-box-height (th).
- confidence/objectness score (Po)(probability of an object within a bounding box).
- class probabilities (P1, P2,…) i.e. which class does the object belong to (softmax values of each class in the dataset).
In total, this accounts to 4 values from the bounding box coordinates, 1 value for objectness score, N classes it is being trained (Here, N=20). That adds up to 25 values per bounding box.
Each cell has 5 bounding boxes (YOLOv2), thus that makes 125 values per cell in the feature map.
#deep-learning #object-detection #deep learning