Making a sound model is very similar to making a Data, NLP or Computer Vision. The most important part is to understand the Basics of sound wave and how we pre-process it to put it in a model.
You can check out the previous Part1 and Part2 of this series to know how we work with a sound wave.
We would be using the DataSet used in this competition to create our SpeechToText Classifier. The Dataset consists of several occurrences of 12 words -”yes” ,”no”,” up”,” down”,” left”,” right”,” on”,” off”,” stop” ,”go”,” silence” and unknown sounds. Given we would be creating a Classifier model the model would only be able to predict either of the 12 words.
You can find the entire Notebook Here
Step 1: Browsing Sub Folders to read our Sound files
Step 2: Chopping and Padding Sound Files
One key requirement for a Classifier model is that the Input length of every word has to be of the same length. Thus we would make sure to chop extra time and pad silence at the end of words whose occurrence time is not equal to 16 sec.
Step 3: Feature Extraction from sound wave
To learn in depth on this please refer to my previous Blog. For this problem we would be extracting the MFCC features of the sound and using them as an input for my Classifier model.
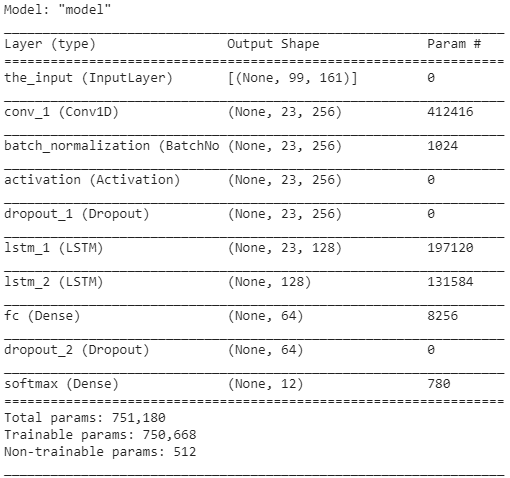
Step 4: Model Architecture
Given every word consist of Phonemes, the first step which the model needs to do is extract necessary features/phonemes out of the entire word. Thus we would be using a CNN model to capture these features. In the next step we need to look into all the features/phonemes and classify the word into one of the categories. The sequence plays an important role out here. Thus we would add an LSTM layer too.
The final architecture looks like:
#machine-learning #speech-to-text-api #pyaudio #speech-recognition #speech-analytics