Moving from Pandas to Spark with Scala isn’t as challenging as you might think, and as a result your code will run faster and you’ll probably end up writing better code.
In my experience as a Data Engineer, I’ve found building data pipelines in Pandas often requires us to regularly increase resources to keep up with the increasing memory usage. In addition, we often see many runtime errors due to unexpected data types or nulls. As a result of using Spark with Scala instead, solutions feel more robust and easier to refactor and extend.
In this article we’ll run through the following:
- Why you should use Spark with Scala over Pandas
- How the Scala Spark API really isn’t too different from the Pandas API
- How to get started using either a Jupyter notebook or your favourite IDE
What is Spark?
- Spark is an Apache open-source framework
- It can be used as a library and run on a “local” cluster, or run on a Spark cluster
- On a Spark cluster the code can be executed in a distributed way, with a single master node and multiple worker nodes that share the load
- Even on a local cluster you will still see performance improvements over Pandas, and we’ll go through why below
Why use Spark?
Spark has become popular due to its ability to process large data sets at speed
- By default, Spark is multi-threaded whereas Pandas is single-threaded
- Spark code can be executed in a distributed way, on a Spark Cluster, whereas Pandas runs on a single machine
- Spark is lazy, which means it will only execute when you _collect _(ie. when you actually need to return something), and in the meantime it builds up an execution plan and finds the optimal way to execute your code
- This differs to Pandas, which is eager, and executes each step as it reaches it
- Spark is also less likely to run out of memory as it will start using disk when it reaches its memory limit
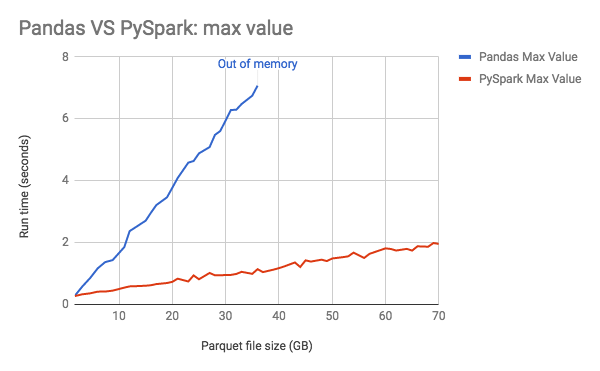
For a visual comparison of run time see the below chart from Databricks, where we can see that Spark is significantly faster than Pandas, and also that Pandas runs out of memory at a lower threshold.
https://databricks.com/blog/2018/05/03/benchmarking-apache-spark-on-a-single-node-machine.html
Spark has a rich ecosystem
- Data science libraries such as Spark ML, which is built in, or Graph X for graph algorithms
- Spark Streaming for real time data processing
- Interoperability with other systems and file types (orc, parquet, etc.)
Why use Scala instead of PySpark?
Spark provides a familiar API, so using Scala instead of Python won’t feel like a huge learning curve. Here are few reasons why you might want to use Scala:
- Scala is a statically typed language, which means you’ll find your code will likely have fewer runtime errors than with Python
- Scala also allows you to create immutable objects, which means when referencing an object you can be confident its state hasn’t been mutated in between creating it and calling it
- Spark is written in Scala, so new features are available in Scala before Python
- For Data Scientists and Data Engineers working together, using Scala can help with collaboration, because of the type safety and immutability of Scala code
Spark core concepts
- DataFrame: a spark DataFrame is a data structure that is very similar to a Pandas DataFrame
- Dataset: a Dataset is a typed DataFrame, which can be very useful for ensuring your data conforms to your expected schema
- RDD: this is the core data structure in Spark, upon which DataFrames and Datasets are built
In general, we’ll use Datasets where we can, because they’re type safe, more efficient, and improve readability as it’s clear what data we can expect in the Dataset.
Datasets
To create our Dataset we first need to create a case class, which is similar to a data class in Python, and is really just a way to specify a data structure.
For example, let’s create a case class called FootballTeam, with a few fields:
case class FootballTeam(
name: String,
league: String,
matches_played: Int,
goals_this_season: Int,
top_goal_scorer: String,
wins: Int
)
Now, let’s create an instance of this case class:
val brighton: FootballTeam =
FootballTeam(
"Brighton and Hove Albion",
"Premier League",
matches_played = 29,
goals_this_season = 32,
top_goal_scorer = "Neil Maupay",
wins = 6
)
Let’s create another instance called _manCity _and now we’ll create a Dataset with these two FootballTeams:
val teams: Dataset[FootballTeam] = spark.createDataset(Seq(brighton,
manCity))
Another way to do this is:
val teams: Dataset[FootballTeam] =
spark.createDataFrame(Seq(brighton, manCity)).as[FootballTeam]
The second way can be useful when reading from an external data source and returning a DataFrame, as you can then casting to your Dataset, so that we now have a typed collection.
#pandas #spark #scala #data-science #developer
