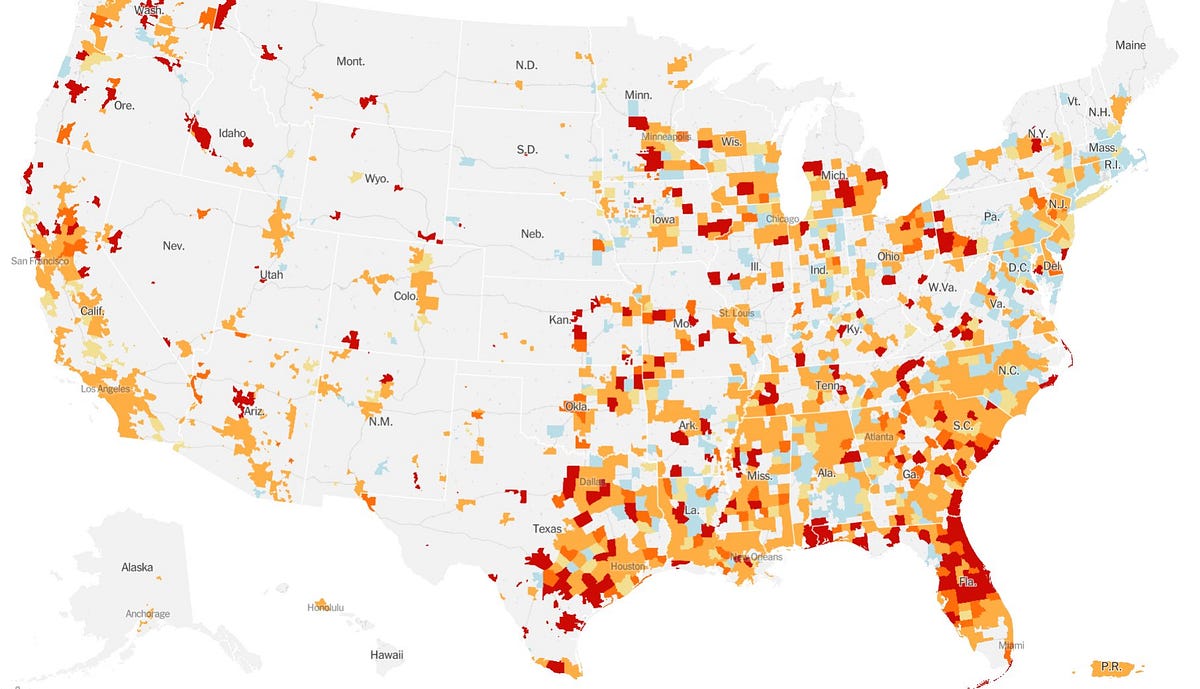
Recently, as pointed out by Abhishek Nagaraj on Twitter, the New York Times has started publishing dasymetric maps where they show Covid data but color each county based only the pixels within the county that are actually populated:

Compare that against their older maps:

And you can see how much better this is. The key thing to notice is that both of these are county-level data. But counties in the dasymetric map are colored only by the pixels within them that have > 10 people per square kilometer — sparsely populated parts of the county, such as forests, are ignored and this makes the resulting visualization more representative of things that affect people (and not land).** In both maps, every county is represented.**
It would be so much easier if there were a readily accessible dataset that gives you county boundaries that include only the populated areas. In this article, I will show you to create such a dataset in BigQuery and provide instructions on how to extract that data into a CSV file with GeoJSON or WKT to plot it in other packages.
BigQuery has a generous free tier (1 TB/month of querying) and each of the queries in this article processes 2 to 5 GB. They take 15 to 45 seconds to run and even without the free tier, would cost you about 1c each (cloud computing is cheap!). Given that, I suggest that you take these queries and adapt them for your needs rather than simply download my result.
Population Density Raster Data
Joining a vector dataset of county boundaries against a raster dataset of population density can be quite hard. Earlier, I have written about how you can efficiently query raster data in BigQuery by demonstrating on the global population density dataset published by Columbia University. Here, I am using that raster dataset (I’ve made it public) and joining it against US count-level data to trim the county boundaries in Washington State to just populated areas:
WITH populated_areas AS (
SELECT bounds
FROM `ai-analytics-solutions`.publicdata.popdensity_sedac_rectangles
WHERE
year = 2020 AND
tile = 'gpw_v4_population_density_rev11_2020_30_sec_1.asc' AND
population_density > 10 -- persons per square kilometer
)
SELECT
state_fips_code, county_fips_code,
ANY_VALUE(county_geom) AS tract_geom,
ST_UNION(ARRAY_AGG(bounds)) AS populated_tract_geom
FROM
`bigquery-public-data`.geo_us_boundaries.counties,
populated_areas
WHERE
state_fips_code = '53' AND
ST_CONTAINS(county_geom, bounds)
GROUP BY 1, 2
Notice that I am passing in a tile. You want to look at the tile boundaries for details, but tile 1 covers the Western US (west, approximately of Ohio) and tile 2 covers the Eastern US. To query the entire country or query states in the transition area, specify tile 1 (_sec_1.asc) and tile 2 (_sec_2.asc).
The resulting table looks like this:

The key things to notice:
- You get 39 results, one for each county in Washington
- While the original tract_geom is a POLYGON, the populated_tract_geom is a MULTI_POLYGON since there are multiple pixels in each county
The result, visualized in BigQuery GeoViz:

Let’s look at an individual county (Asotin county in the Southeast corner of the state). Here’s the original boundary:

And here’s the populated areas — if we are drawing Asotin County, these are the only pixels we’d color:

Full dataset (for whole US)
Let’s do this for the whole country, not just Washington, and send the output to a table for easy querying:
CREATE OR REPLACE TABLE publicdata.us_tracts AS
WITH populated_areas AS (
SELECT bounds
FROM `ai-analytics-solutions`.publicdata.popdensity_sedac_rectangles
WHERE
year = 2020 AND
(tile = 'gpw_v4_population_density_rev11_2020_30_sec_1.asc' OR
tile = 'gpw_v4_population_density_rev11_2020_30_sec_2.asc'
) AND
population_density > 10 -- persons per square kilometer
)
SELECT
state_fips_code, county_fips_code,
ANY_VALUE(county_geom) AS tract_geom,
ST_UNION(ARRAY_AGG(bounds)) AS populated_tract_geom
FROM
`bigquery-public-data`.geo_us_boundaries.counties,
populated_areas
WHERE
ST_CONTAINS(county_geom, bounds)
GROUP BY 1, 2
This creates a table with 3222 rows, one for each county.
I’ve made the dataset public. You can use it in BigQuery by directly querying or joining against this table:
ai-analytics-solutions.publicdata.us_tracts
For your convenience, that table also has the state code, county name, and population. This was the query I used:
CREATE OR REPLACE TABLE publicdata.us_tracts AS
WITH populated_areas AS (
SELECT
bounds, population_density
FROM `ai-analytics-solutions`.publicdata.popdensity_sedac_rectangles
WHERE
year = 2020 AND
(tile = 'gpw_v4_population_density_rev11_2020_30_sec_1.asc' OR
tile = 'gpw_v4_population_density_rev11_2020_30_sec_2.asc'
) AND
population_density > 10 -- persons per square kilometer
)
SELECT
state_fips_code, county_fips_code,
ANY_VALUE(state) AS state_code,
ANY_VALUE(county_name) AS county_name,
SUM(population_density) AS population,
ST_UNION(ARRAY_AGG(bounds)) AS populated_tract_geom,
ANY_VALUE(county_geom) AS tract_geom
FROM `bigquery-public-data`.geo_us_boundaries.counties
JOIN `bigquery-public-data`.geo_us_boundaries.states USING(state_fips_code)
CROSS JOIN populated_areas
WHERE
ST_CONTAINS(county_geom, bounds)
GROUP BY 1, 2
Query to create county boundaries where the boundaries of populated pixels within each county.
#bigquery #gis #population-density #visualization #mapping #visual studio code