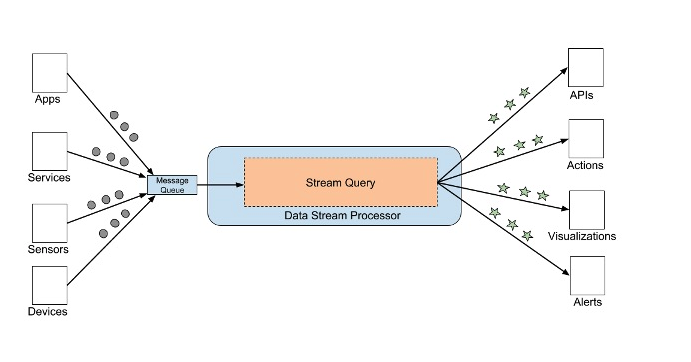
The term ‘Big Data’ contains more than just its reference to quantity and volume. Living in the era of readily available information and instantaneous communication, it is not surprising that data architectures have been shifting to be stream-oriented. Real value for companies doesn’t just come from sitting on a gargantuan amount of collected data points, but also from their ability to extract actionable insights as quickly as possible (even in real-time). Processing data at faster rates allows a company to react to changing business conditions in real-time.
It goes without saying that over the last decade, there has been a constant growth for applications (aka message-broker software) capable of capturing, retain and process this overwhelmingly rapid flow of information. As of 2020, Apache Kafka is one of the most widely adopted message-broker software (used by the likes of Netflix, Uber, Airbnb and LinkedIn) to accomplish these tasks. This blog will give a very brief overview of the concept of stream-processing, streaming data architecture and why Apache Kafka has gained so much momentum.
What is stream-processing?
Stream-processing is best visualised as a river. In the same way that water flows through a river, so do packages of information in the endless flow of stream-processing.
According to AWS, the general definition of streaming data would be “data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes)”.
Data streaming works particularly well in time-series in order to find underlying patterns over time. It also really shines in the IoT space where different data signals can be constantly collected. Other common uses are found on web interactions, e-commerce, transaction logs, geolocation points and much much more.
There is a subtle difference between real-time processing and stream-processing:
- Real-time processing implies a hard deadline in terms of data processing. In other words, event time is very relevant and latencies in the order of a second are unacceptable.
- Stream-processing refers more to a method of computation in a continuous flow of data. An application printing out of all the Facebook posts created in the last day doesn’t really have constraints in terms of time. However, the long term output rate should be faster (or at least equal) to the long term input rate otherwise system storage requirements would have to be indefinitely large.
#kafka-streams #data-science #apache