The out-of-order data landing problem
Applying window functions over data is non-trivial if data arrives out-of-order (with respect to the dimension the window function is applied across). For clarity, lets take timeseries data for this example as our window dimension. If timeseries data arrives from Tuesday through Thursday of a week, then at a later time data from Monday of that week arrives, the data has arrived out-of-order.
As a window function output is sensitive to its surroundings in timespace, the results of the window function would be altered by the new out-of-order data that landed. All affected data needs to be reprocessed.
You could reprocess all the data when data arrives out-of-order. But, when data quantities are large, reprocessing the entire dataset becomes impractical. This article discusses an efficient approach, using the approach building an AWS Glue predicate pushdown described in my previous article. This approach only reprocesses the data affected by the out-of-order data that has landed.
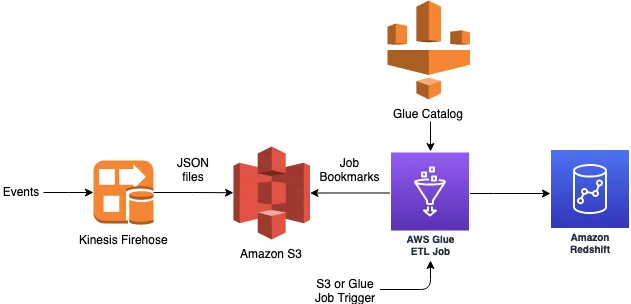
Solution
Glue ETL Job environment setup
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
### @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
#spark #data-science #data-engineering #python