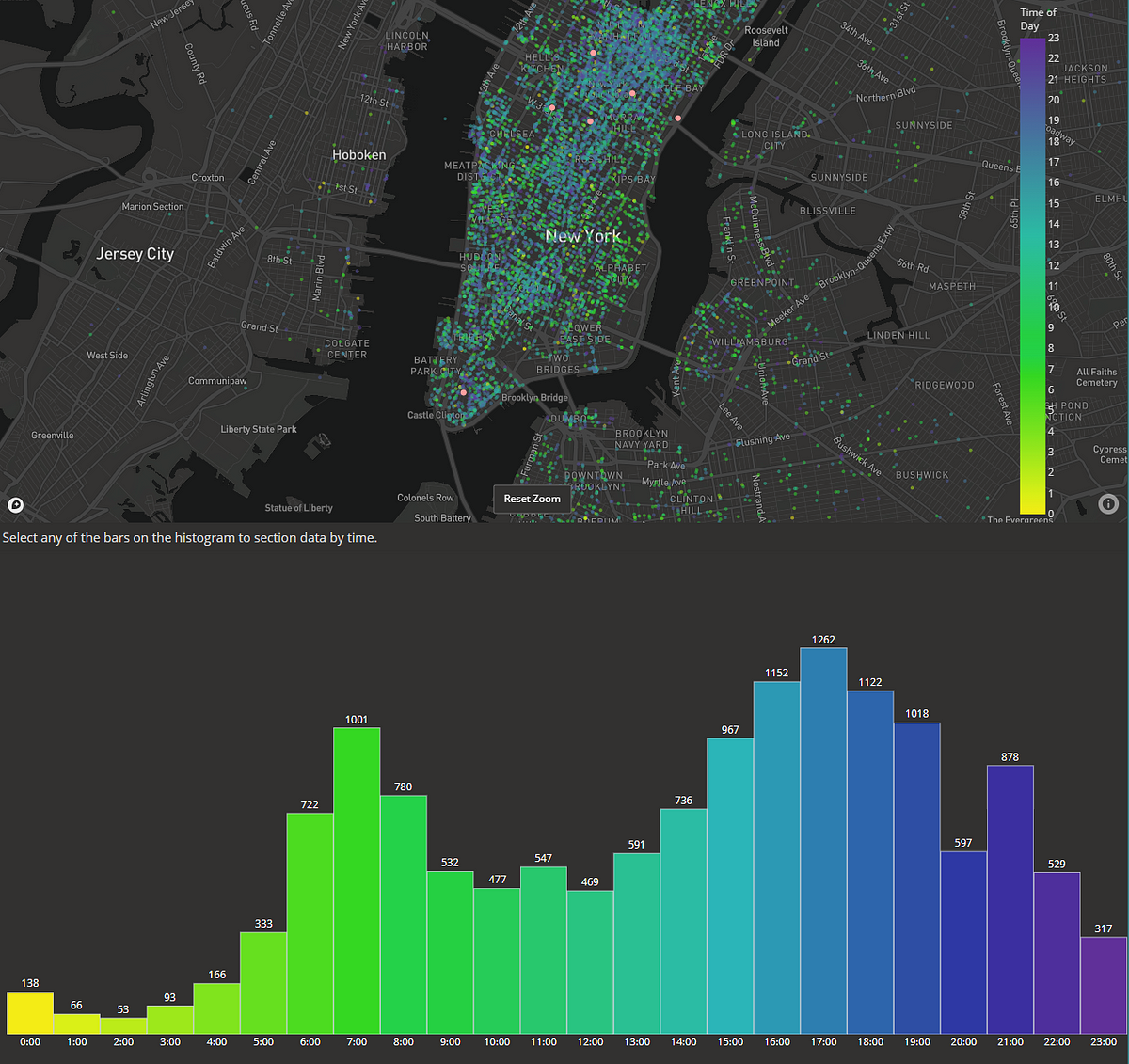
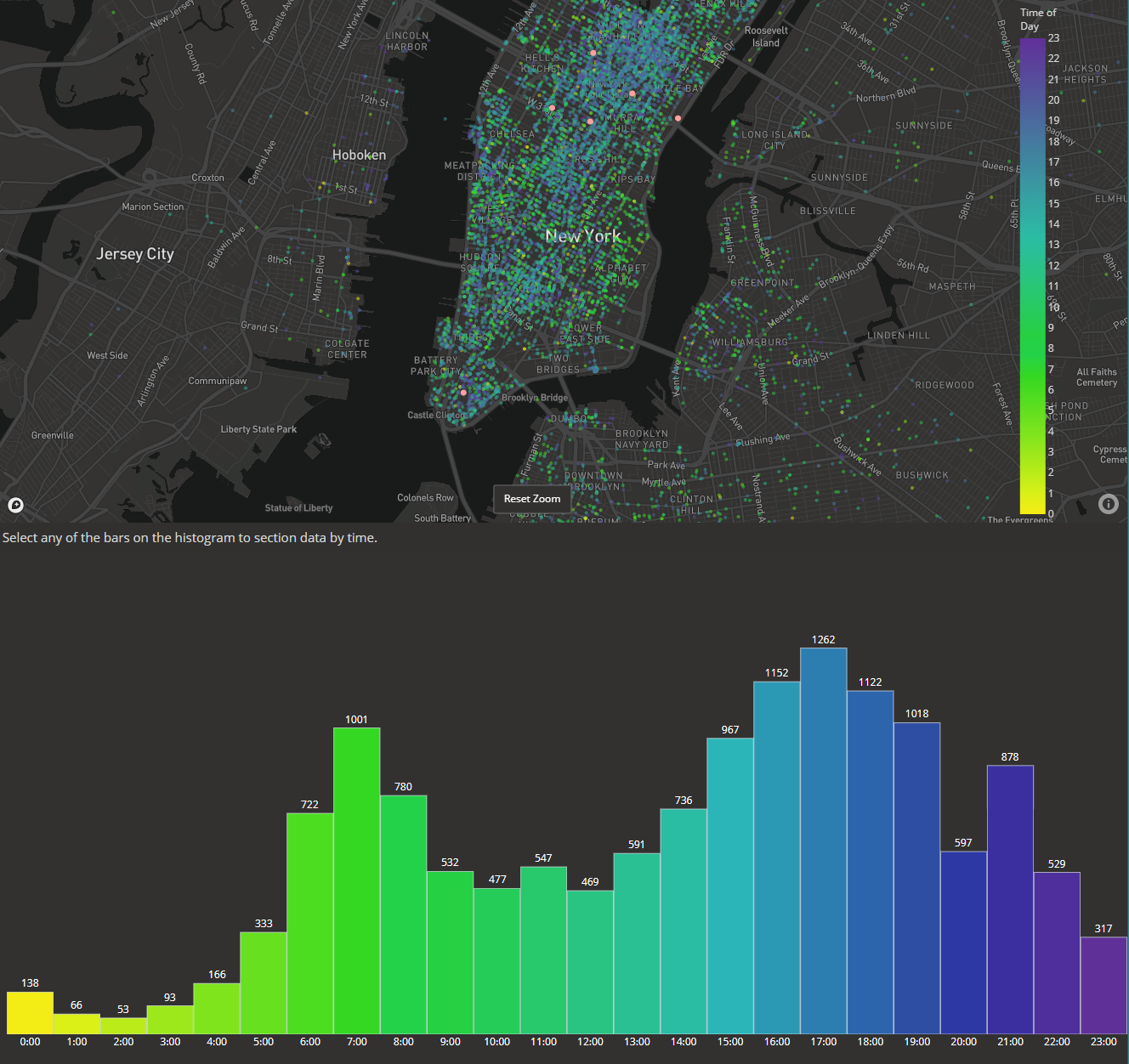
As you know, Zillow houses (no pun intended ;)) some of the most comprehensive data in and around home sales that exists today. Arguably more data than competitor sites like Redfin or Realtor.com. However, accessing this data is quite difficult. You either need to be in the right place at the right time when the quarterly option to get a database license rolls around, and even then you’ll have to work for a government agency or education institution, work for the company in a technical role, use historic data from their research tools or scrape it. The topic of this article follows the latter option.
Program Overview
- Libraries
- Request Headers
- Request Session
- Getting Urls into Soup Objects
- Parse Data from Urls by Looping Through Pages
- Importing Parsed Data into DataFrames
- Create and Append DataFrames
- Format DataFrames (Fun With Formatting)
- More Iterating Through links to Parse out HTML
- Modifying the Zestimate DataFrame
- Create a
best_dealColumn & do Simple Math - Show Me The Money (Print It)
- One Plot to Rule Them All
Libraries
If you see a library you don’t have installed, you’ll need to install it. You could throw them all in a requirements.txt file and run pip install requirements.txt.
import os
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import sys
import numpy as np
import pandas as pd
import regex as re
import requests
import lxml
from lxml.html.soupparser import fromstring
import prettify
import numbers
import htmltext
Request Headers
Zillow likes to throw Captchas so when you try and run a request.get(url) type of function, zillow will start returning captcha pages. One way to get around this is by adding headers to the request function. Like such:
req_headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.8',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
with requests.Session() as s:
city = 'seattle/' #*****change this city to what you want*****
url = 'https://www.zillow.com/homes/for_sale/'+city
r = s.get(url, headers=req_headers)
Getting Urls into Soup Objects
There are plenty of ways to loop through urls and create variables out of them. I went a more manual route, and just created 10 soup variables and titled them as unique variables. After all, I only planned on going into 10 zillow pages. Didn’t seem overly necessary to create these variables programatically. I did the same thing with URLs and Request objects. If you’re like me and can’t wait to finish the article before you get your hands on the code, here’s the source.
#pandas #data-analytics #python #beautifulsoup #data-science #data analysis