Exactly a year back, before I started writing this article, I watched Andrej Karapathy, the director of AI at Tesla delivering a talk where he showed the world a glimpse of how a Tesla car perceives depth using the cameras hooked to the car in-order to reconstruct its surroundings in 3D and take decisions in real-time, everything(except the front radar for safety) was being computed just with vision. And that presentation blew my mind!
Of course, I knew 3-D reconstruction of an environment is possible through cameras, but I was in a mindset that why would anyone risk using a normal camera when we’ve got such highly accurate sensors like LiDAR, Radar, etc. that could give us an accurate presentation of the environment in 3-D with far less computation? And I started studying(trying to understand) papers related to this topic of Depth Perception and 3-D Reconstruction from Vision and came to the conclusion that we humans have never had rays coming out of our heads to perceive depth and environment around us, we are intelligent and aware of our surroundings just with the two eyes we’ve got, from driving our car or bike from office to work, or driving a formula 1 at 230 mph in the world’s most dangerous tracks, we never required lasers to make decisions in microseconds. The world around us was constructed by us for us, beings with vision and so as Elon said, ‘these costly sensors would become pointless once we solve vision’.
There’s huge research going on in this field of depth perception with vision, especially with the advancements in Machine Learning and Deep Learning we are now able to compute depth just from vision at high accuracy. So before we start learning the concepts and implementing these techniques, let us look at what stage this technology is currently in and what are the applications of it.
Robot Vision:
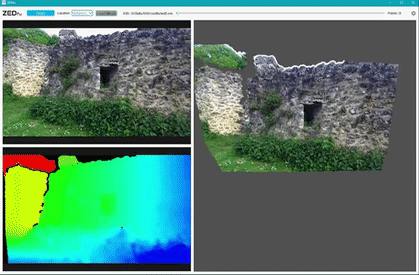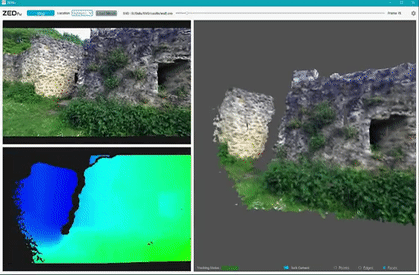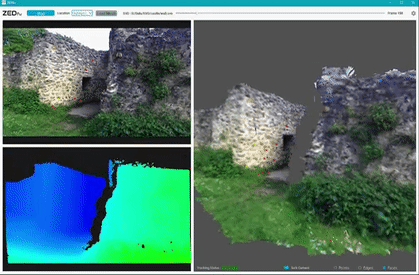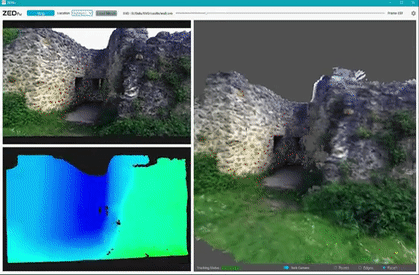
Environment Perception with ZED camera
Creating HD Maps for autonomous driving:

Depth Perception with Deep Learning
SfM(Structure from Motion) and SLAM(Simultaneous Localisation and Mapping) are one of the major techniques that make use of the concepts that I am going to introduce you to in this tutorial.

Demonstration of an LSD-SLAM
Now that we’ve got enough inspiration to learn, I’ll start the tutorial. So first I’m going to teach you the basic concepts required to understand what’s happening behind the hood, and then apply them using the OpenCV library in C++. The question you might ask is why am I implementing these concepts in C++ while doing it in python would be far easier, and there’s reason behind it. The first reason is that python is not fast enough for these concepts to implement in real-time, and the second reason is that unlike python, using C++ would mandate our understanding of the concept without which one can’t implement.
In this tutorial we are going to write two programs, one is to get a depth map of a scene and another is to obtain a point cloud of the scene, both using stereo vision.
Before we dive right into the coding part, it is important for us to understand the concepts of camera geometry, which I am going to teach you now.
The Camera Model
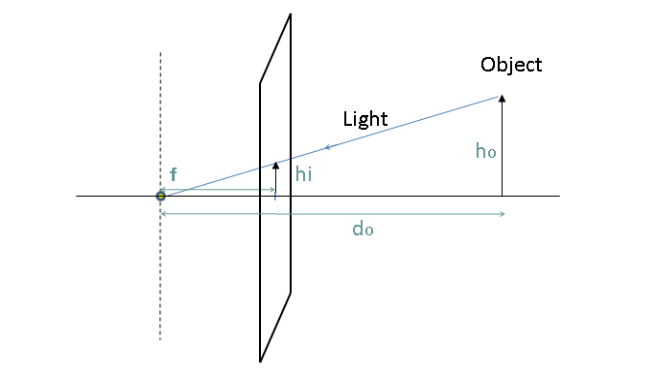
The process used to produce images has not changed since the beginning of photography. The light coming from an observed scene is captured by a camera through a frontal aperture(a lens) that shoots the light onto an image plane located at the back of the camera lens. The process is illustrated in the figure below:


From the above figure, do is the distance from the lens to the observed object, di is the distance between the lens and image plane. And f will hence become the focal length of the lens. These described quantities have a relation between them from the so-called “Thin Lens Equation” shown below:
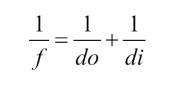
Now let us look into the process of how an object from the real-world that is 3-Dimensional, is projected onto a 2-Dimensional plane(a photograph). The best way for us to understand this is by taking a look into how a camera works.
A camera can be seen as the function that maps 3-D world to a 2-D image. Let us take the simplest model of a camera, that is the Pinhole Camera Model, the older photography mechanisms in human history. Below is a working diagram of a pinhole camera :
From this diagram we can derive :
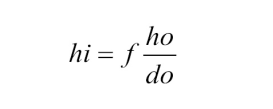
Here it’s natural that the size hi of the image formed from the object will be inversely proportional to the distance do of the object from camera. And also that a 3-D scene point located at position (X, Y, Z) will be projected onto the image plane at (x,y) where (x,y) = (fX/Z, fY/Z). Where the Z coordinate refers to the depth of the point, which was done in the previous image. This entire camera configuration and notation can be described with a simple matrix using the homogeneous coordinate system.
When cameras generate a projected image of the world, projective geometry is used as an algebraic representation of the geometry of objects, rotations and transformations in the real world.
Homogeneous coordinates are a system of coordinates used in projective geometry. Even though we can represent the positions of objects(or any point in 3-D space) in real-world in Euclidean Space, any transformation or rotation that has to be performed must be performed in homogeneous coordinate space and then brought back. Let us look at the advantages of using Homogeneous coordinates:
- Formulas involving Homogeneous Coordinates are often simpler than in the Cartesian world.
- Points at infinity can be represented using finite coordinates.
- A single matrix can represent all the possible protective transformations that can occur between a camera and the world.
In homogeneous coordinate space, 2-D points are represented by 3 vectors, and 3-D points are represented by 4 vectors.
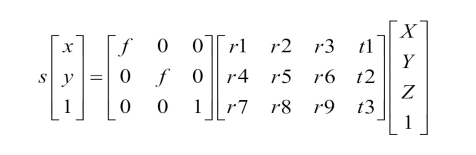
In the above equations, the first matrix with the f notation is called the intrinsic parameter matrix(or commonly known as the intrinsic matrix). Here the intrinsic matrix contains just the focal length(f) right now, we’ll look into more parameters of this matrix ahead of this tutorial.
The second matrix with the r and t notations is called the extrinsic parameter matrix(or commonly known as the Extrinsic Matrix). The elements within this matrix represent the rotation and translation parameters of the camera(that is where and how the camera is placed in real world).
Thus these intrinsic and extrinsic matrices together can give us a relation between the (x,y) point in image and (X, Y, Z) point in real world. This is how a 3-D scene point is projected onto a 2-D plane depending on the given camera’s intrinsic and extrinsic parameters.
#depth-perception #stereo #stereo-vision #deep-learning #computer-vision #deep learning
