As a reminder, this end-to-end project aims to solve a classification problem in Data Science, particularly in finance industry and is divided into 3 parts:
- Explanatory Data Analysis (EDA) & Feature Engineering
- Feature Scaling and Selection (Bonus: Imbalanced Data Handling)
- Machine Learning Modelling (Classification)
If you have missed the 1st part, feel free to check it out here before going through the 2nd part that follows here for a better context understanding.
A. Feature Scaling
What is feature scaling and why do we need it prior to modelling?
According to Wikipedia,
Feature scaling is a method used to normalize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step.
If you recall from the 1st part, we have completed engineering all of our features on both datasets (A & B) as below:
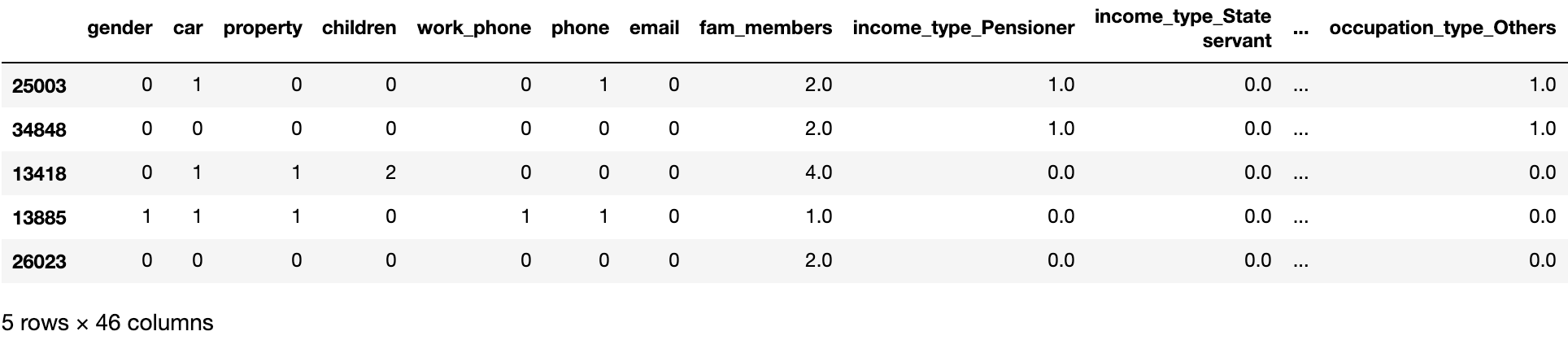
Dataset A (encoded without target)

Dataset B (encoded with target)
As seen above, data range and distribution among all features are relatively different from one another, not to mention some variables bearing with outliers. That being said, it is highly recommended that we apply feature scaling to the entire dataset consistently for the purpose of making it more digestible to machine learning algorithms.
In fact, there are a number of different methods in the market, but I will only focus on the three which I believe are relatively distinctive: StandardScaler, MinMaxScaler and RobustScaler. In brief,
- StandardScaler: this method removes the mean and scales the data to unit variance (mean = 0 and standard deviation = 1). However, it is highly influenced by outliers, especially those marginally extreme ones which can spread the scaled data range to further than 1 standard deviation.
- MinMaxScaler: this method subtracts the minimum value in the feature and divides it by the range (which is the difference between the original maximum and minimum value). Essentially, it rescales the dataset to the range of 0 and 1. However, this method is relatively limited as it compress all data points to a narrow range and it doesn’t help much in the presence of outliers.
- RobustScaler: this method is based on percentiles, which subtracts the median and divides by the interquartile range (75% — 25%). It is generally more preferable than other two scalers since it is not greatly influenced by large marginal outliers if any.
Let’s see how the three scalers differ in our dataset:
from sklearn.preprocessing import StandardScaler, RobustScaler, MinMaxScaler
#StandardScaler
x_a_train_ss = pd.DataFrame(StandardScaler().fit_transform(x_a_train), columns=x_a_train.columns)
#MinMaxScaler
x_a_train_mm = pd.DataFrame(MinMaxScaler().fit_transform(x_a_train), columns=x_a_train.columns)
#RobustScaler
x_a_train_rs = pd.DataFrame(RobustScaler().fit_transform(x_a_train), columns=x_a_train.columns)
#machine-learning #imbalanced-data #feature-selection #data-science #data analysis
