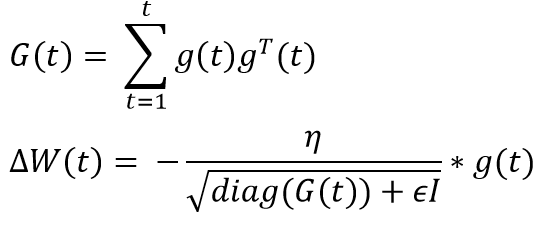In my earlier post Gradient Descent with Momentum, we saw how learning rate(η) affects the convergence. Setting the learning rate too high can cause oscillations around minima and setting it too low, slows the convergence. Learning Rate(η) in Gradient Descent and its variations like Momentum is a hyper-parameter which needs to be tuned manually for all the features.
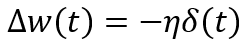
Image by author
When we use the above equation for updating weights in a neural net
- Learning rate is the same for all the features
- Learning rate is the same at all the places in the cost space
Impact of constant learning rate on the convergence
Suppose, we are trying to predict the success/rating of a movie. Let’s assume there are thousands of features and one of them being “is_director_nolan”. The feature “is_director_nolan” in our input space will be mostly 0 as Nolan has directed very few movies but his presence significantly impacts the success/rating of a movie. Essentially, this feature will be sparse but because of high information content, we cannot ignore it.
During the forward pass in a neural net, if the input(x)at iteration(t) is 0 then the output becomes the activation(φ**)** of bias(b) using the below equation.
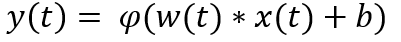
Image by author
Hence, the local gradient calculated during back prop w.r.t this constant bias will be 1 and the weight update will be very small for this feature (look at the first equation)
For a sparse input feature like “is_director_nolan”, a large weight update will happen only when the input changes from 0 to 1 or vice versa. Whereas a dense feature will receive more updates. Therefore, using a constant and same learning rate for all the features is not a good idea.
#learning-rate #adagrad #gradient-descent #adaptive-learning #machine-learning