Most business users are adept at analyzing facts on spreadsheets. Give them a ton of data points in an Excel sheet or Google Spreadsheet, they will be able to formulate Pivot tables, VLOOKUP functions and generate fancy visualizations to make the data palatable and ready for interpretation. Most startups depend on a folder of such spreadsheets to draw their weekly/monthly metrics before moving on to sophisticated Analytics tools.
But, the source of that data is mostly residing in some form of RDBMS or NoSQL database. We depend on various Data Warehousing solutions to import this data and run analysis reports on top of them. What if we could import that data seamlessly to spreadsheets on a continuous basis and remove the manual error-prone human intervention there?
This blog post walks through a Lambda function that given the source, pulls the data in JSON format and dumps it in a Google Spreadsheet. The function can be scheduled to poll every hour or as needed to ensure the data is as latest as demanded by business. The source does not always have to be a database system, anything that we can interface over wire and get the response in JSON will work.
Technology Choices
- We will be writing the serverless function in Node.js since the core of the functionality is JSON wrangling
- The standard googleapis npm package to interface with Google Spreadsheets
- In this example, we will use Postgres as the source of truth, but the setup should literally work for any database and with some tweaking any source of JSON. The node-postgres package will serve us well to talk to PostgreSQL.
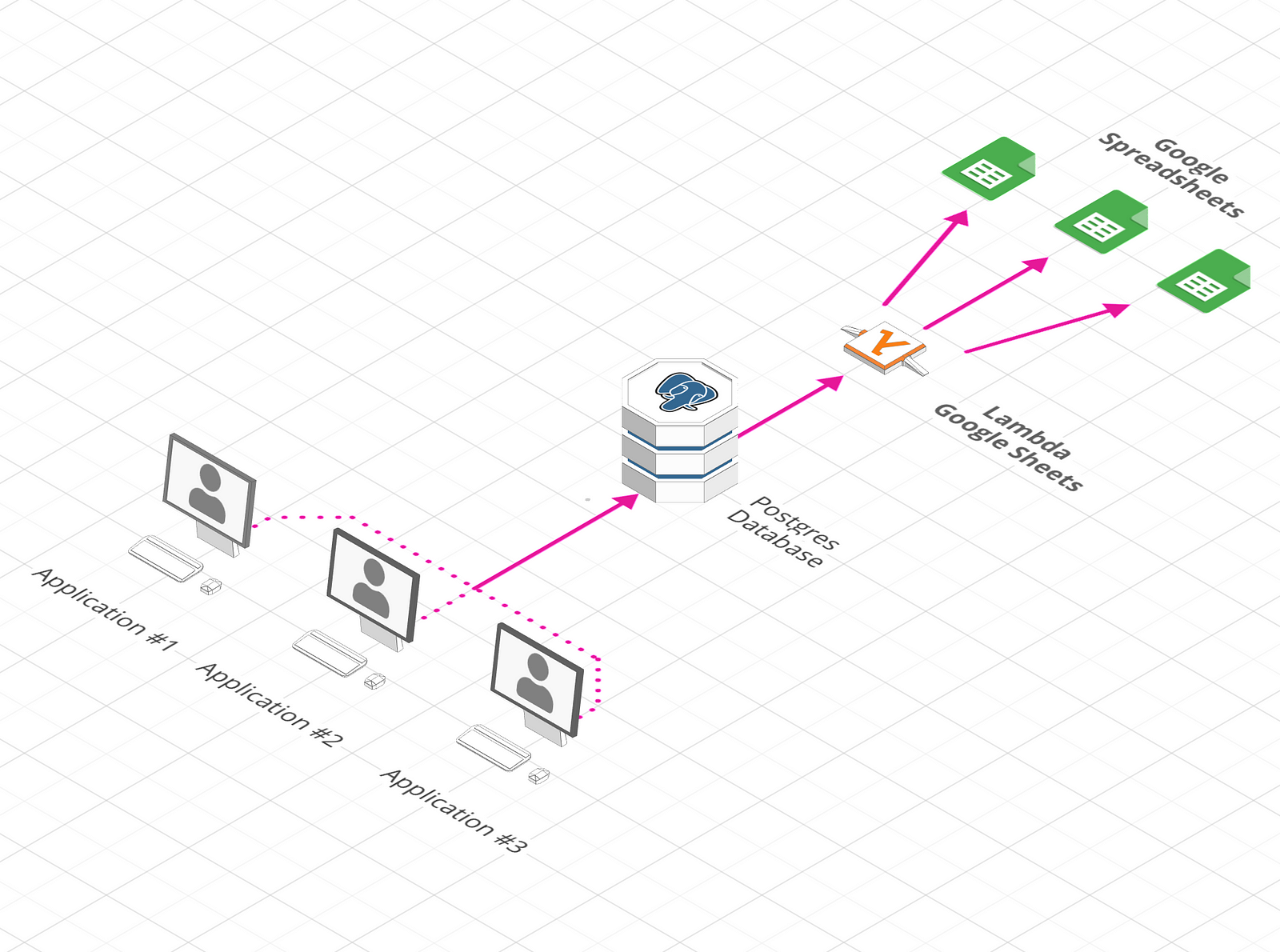
The final setup will look as captured in the diagram below:
Bootstrapping the project
I have setup a starter kit that you can clone and use as baseline for kick-starting the project. Clone the repo and set it up using the following commands:
$ git clone git@github.com:rcdexta/lambda-google-sheets.git
$ cd lambda-google-sheets
$ npm install
Note: Make sure you have already Node.js 8.10 or higher to support all the constructs in the code### Setting up the Google Sheets API
We must setup the Google OAuth token to let our script write to Google Spreadsheets. When you are logged into a google account, navigate to the Google Sheets API Console page and click on the Enable the Google Sheets API button. This will open up a modal where you can choose a new project name. The next screen will let you download a file called credentials.json. Download and save it in the lambda-google-sheets folder.

To test if the sheets api works fine, open a new google sheet under the same account that you used to create the token and copy the spreadsheetId from the URL. So if the URL is of the following form, everything after /d/ before next slash is the spreadsheet identifier.
Note: Make sure you have already Node.js 8.10 or higher to support all the constructs in the code
Refer and replace thespreadsheetUrlandspreadsheetIdinconfig.jsonfile in the codebase. Note, that the first sheet name in the workbook is assumed asSheet1
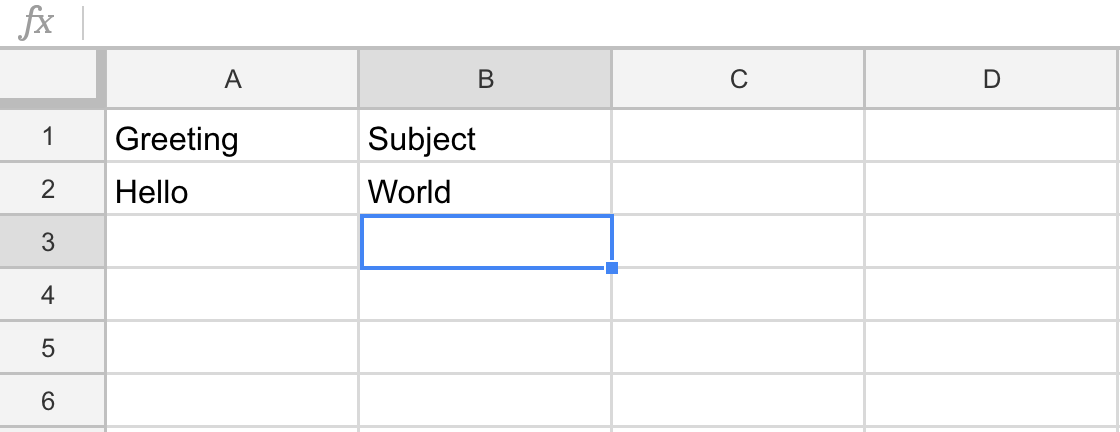
Now, run node googleapi.js and you will be asked to a copy a URL and open it on the browser. Do it and you will download a file called token.json at the end of OAuth confirmation and if you check the spreadsheet you will see the following contents on the file:
Connecting to Database
Checkout the contents of pgClient.js file. You can either pass the database connection params as environment variables (which is needed when deploying to AWS lambda) and fallback to literals for testing in local database.
pgClient.js
const { Client } = require('pg')
const pg = {
init: async function() {
const client = new Client({
user: process.env['DB_USER'] || 'postgres',
host: process.env['DB_HOST'] || 'localhost',
database: process.env['DB_NAME'] || 'customers',
password: process.env['DB_PASSWORD'] || '',
port: 5432
})
await client.connect();
return client;
}
}
module.exports = pg
The script assumes that you have a Postgres server running on port 5432 on your local machine and has a database called customers
Let’s check the configuration in config.json
config.json
{
"name": "Customers",
"description": "All customer related details sync",
"spreadsheetUrl": "https://docs.google.com/spreadsheets/d/1d4QXXx8qFRhcajpVcEbwVM8TlEXAvrclWpLGmqvw-Pc/edit#gid=0",
"spreadsheetId": "1d4QXXx8qFRhcajpVcEbwVM8TlEXAvrclWpLGmqvw-Pc",
"tables": [
{
"tableName": "customer_details",
"sheetName": "Sheet1"
}
]
}
As discussed before, we have already copied the Spreadsheet URL to the config, Notice, the tables array. You can specify the tables that you would like to import and the corresponding sheet name.
Testing the lambda function
We can invoke the lambda function locally to make sure everything is working fine. Run the following command
$ SLS_DEBUG=* serverless invoke local --function lambda_sheets
The SLS_DEBUG param will print additional debugging information to the console in case something goes wrong. If all is good, you see something like this below where the script prints the number of rows imported.
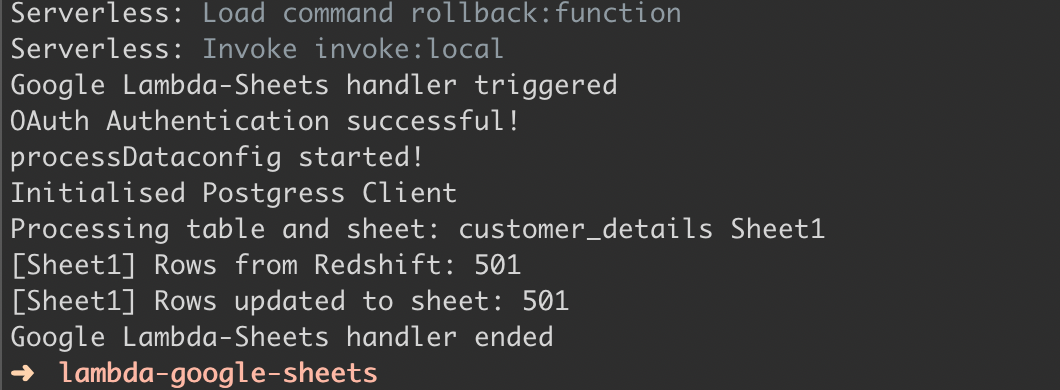
Now, go check the spreadsheet and you should see all the data from the customer_details table in Sheet1 So, this means every time the lambda function is invoked, it will clear the contents of the sheet and replace it with the data from the table in the Postgres database.
Deploying the Lambda function
The Serverless config shared with you assumes that you are deploying this function to AWS Lambda. Let’s walk-through the steps to deploy the function to production.
Before we deploy, the function let’s discuss additional parameters in serverless.yml file that are relevant. Other parts of the yml file have been skipped for brevity.
serverless.yml
functions:
lambda_sheets:
handler: handler.runs
description: Lambda function to pull data from Postgres and dump to Google Spreadsheet
timeout: 900
events:
- schedule:
rate: rate(1 hour)
enabled: true
The timeout param (in milliseconds) is the maximum execution time and the scheduler will ensure this function is called every 1 hour.
To deploy the function to AWS, make sure aws_access_key_id, aws_secret_access_key and region are passed as environment vars to deploy command or configured in ~/.aws/config
$ serverless deploy
The above command will create a new AWS Lambda function and invoke it every 1 hour. Make sure the database config is populated as environment variables as needed from lambda console.
The complete source code is available here for your reference. Thanks for reading, and please feel free to comment and ask me anything! Cheers 👍
Learn more
☞ Ultimate SQL and DataBase Concepts
☞ The Complete Database Design Fundamentals Toolkit
☞ The Complete Database Design & Modeling Beginners Tutorial
☞ Introduction to Oracle Database Backup and Security
☞ Java Database Connection: JDBC and MySQL
#database #serverless
