Hello everyone,
Hoping that everyone is safe and doing well. In this blog, we will look into some concepts of CNN’s for image classification that are often missed or misunderstood by beginners (including me till some time back). This blog requires the reader to have some basic idea of how CNN’s work. However, we will cover the important aspects of CNN’s before getting deeper into advanced topics.
After this, we will look at a machine learning technique called Transfer learning and how it is useful in training a model with less data on a deep learning framework. We will train an image classification model on top of Resnet34 architecture using the data that contains digitally recorded heartbeats of human beings in the form of audio (.wav) files. In the process, we will convert each of these audio files into an image by converting them to spectrograms using a popular python audio library called Librosa. In the end, we will examine the model with popular error metrics and check its performance.
CNN’s for image classification:
Neural networks with more than 1 convolution operations are called convolutional neural networks (CNN). Input of a CNN contains images with numerical values in each pixel arranged spatially along the width, height and depth (channels). The goal of the total architecture is to get a probability score of an image belonging to a certain class by learning from these numerical values arranged spatially. In the process, we perform operations like pooling and convolutions on these numerical values to squeeze and stretch them along the depth.
An image typically contains three layers namely RGB (Red, Green, Blue).
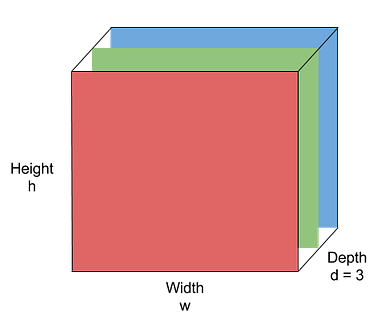
Image by Purit Punyawiwat, Source : Datawow
Main operations in CNN’s
Convolution operation
Convolution operation is (w.x+b) applied to all the different spatial localities in the input volume. Using more number of convolution operations helps to learn a particular shape even if its location in the image is changed.
Example: Generally clouds are present on the top of a landscape image. If an inverted image is fed into a CNN, more number of convolutional operations makes sure that the model identifies the cloud portion even if it is inverted.
Mathematical Expression: x_new = w.x + b where w is the filter/kernel, b is the bias and x is part of a hidden layer output. Both w and _b _are different for every convolution operation applied on different hidden layers.
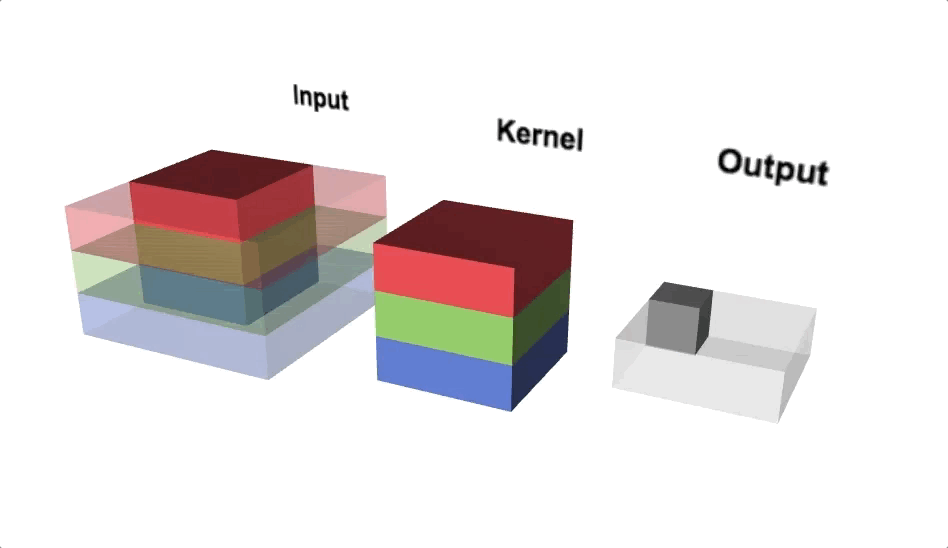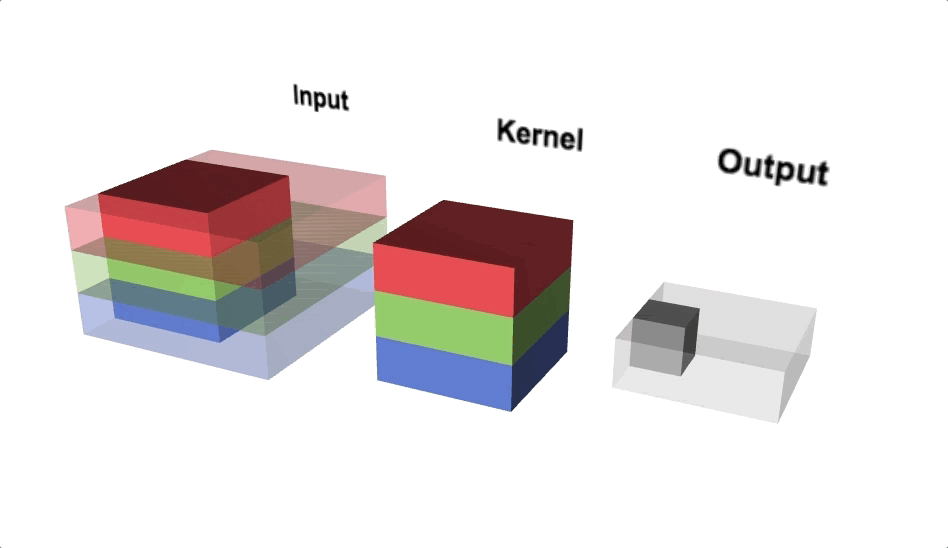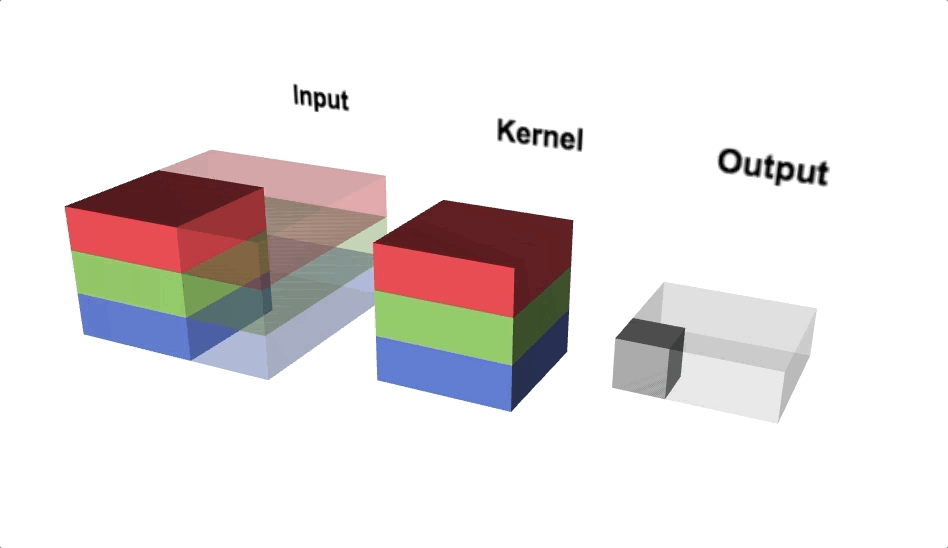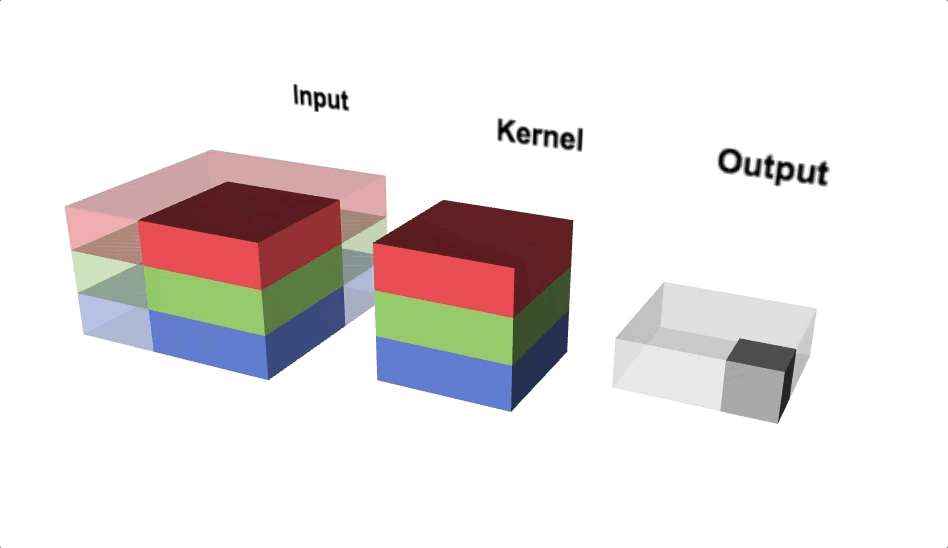
Convolution Operations(Source: Lecture 22-EECS251, inst.eecs.berkley.edu)
Pooling
Pooling reduces the spatial dimensions of each activation map (output after convolution operation) while aggregating the localised spatial information. Pooling helps to squeeze the output from hidden layers along height and width. If we consider maximum value within the non-overlapping sub-regions then it is called Max-pooling. Max-pooling also adds non-linearity to the model.
#pytorch #deep-learning #transfer-learning #audio-classification #convolutional-network #neural networks
