Thousands of songs are released every year around the world. Some are very successful in the music industry; others less so. It is a fact that being successful in this industry remains a difficult task. Investing in the production of a song requires a variety of activities and can consume a lot of resources. There are very few music labels that fund studies to find out to what extent the song they are about to release could be a musical hit.
My curiosity about music prompted me to devote some time to studying the subject. For many people, Drake’s secret to making his hits in recent years is his style as an artist; for others, it is mainly to his notoriety that he owes it. Generally speaking, opinions don’t just go one way when it comes to explaining why a song is a hit but another one isn’t; or what an artist should prioritize while producing a song if he wants it to be a hit.
This bipartite article is a snapshot of the project I have been working on over the past few weeks. I used data science techniques to understand what characterizes a popular song, and more precisely how it would be possible to predict the popularity of a song based solely on its audio characteristics and the profile of the song artist. I built a machine learning model that can classify a song as a hit or not.
While social factors like the context in which the song was broadcast, the demographics of its listeners, and the effectiveness of its marketing campaign may just as well play an important role in its virality, I hypothesized that the characteristics inherent of a song, such as the profile of the artist who performs it, its duration, its audio characteristics can be correlated and also revealing of its virality.
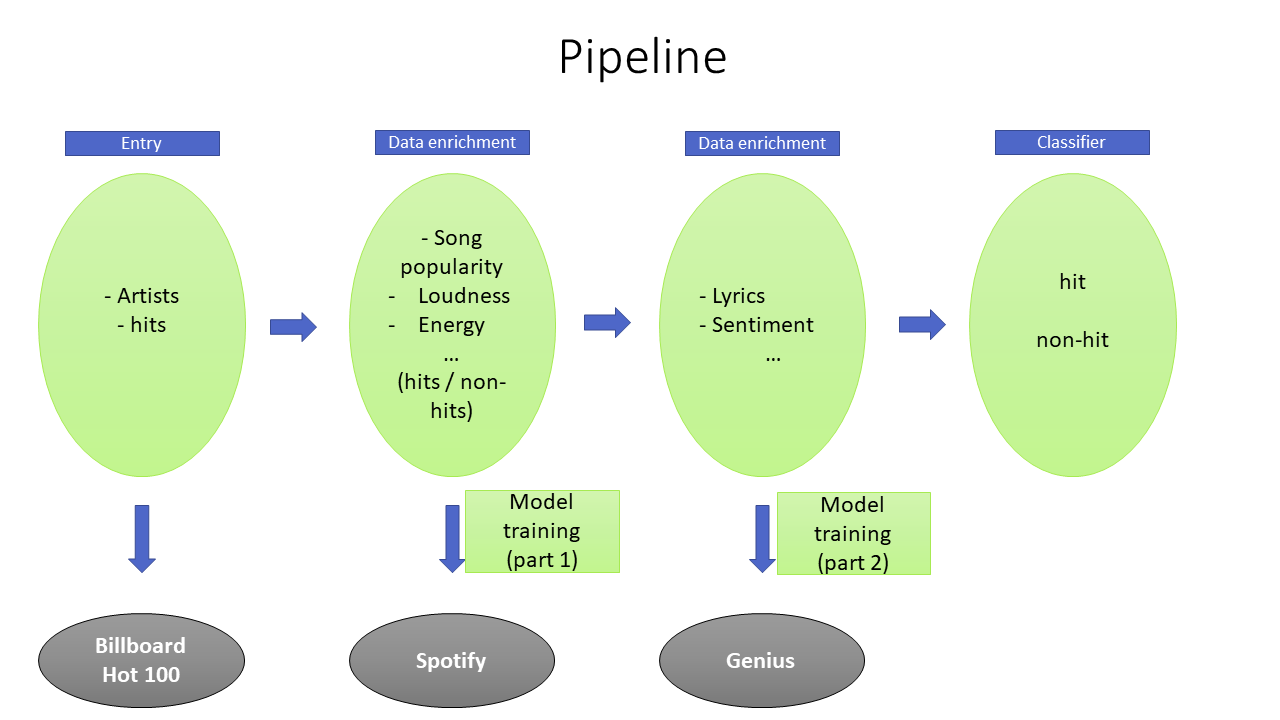
Image by author
My data
I
couldn’t have a data set from a single source that contained all the variables. To overcome this problem, I have resorted to data enrichment techniques with the following three data sources: Billboard, Spotify and Genius.
First, using Beautiful Soup, I collected a list of Billboard Year-End Hot 100 songs from 2010 to 2019, at the rate of 100 songs per year. Then, the Spotipy package was used for the recovery of data related to the songs audio characteristics such as danceability, instrumentalness, liveness, etc., on one hand; and, on the other hand, those related to the artist’s profile such as number of followers, popularity, etc. for both previously recovered hit and other non-hit songs from the same period.
And finally, Genius will be used mainly for retrieving the lyrics for all the songs that have been collected.
A song in our data set is considered a hit if it made it to the Billboard Year-End Hot 100 chart at least once during any of the years in the reporting period. In other words, our model was tasked with predicting whether a song would make it to Billboard’s 100 most popular song list or not.
Tools used :
- The spotipy package to access data from the Spotify music platform
- seaborn and matplotlib for data visualization
- pandas and numpy for data analysis
- LightGBM and the scikit-learn library for building and evaluating the model
#data-science #data-visualization #music #spotify #machine-learning
