Why convolutional networks work? What’s the _magic _behind them that allows us to succeed in a broad range of applications such as image classification, object detection, face recognition, and others?
It turns out that all of this is possible thanks to two astonishingly simple, yet powerful concepts: **convolution **and pooling.
In this post, I will try to explain them in a really **intuitive **and **visual **way, leaving the math behind. I have found a lot of documentation in the internet with a strong mathematical foundation, but I think the core ideas are sometimes watered down through all the formulas and calculations.
All the examples that we will cover in this post can be found in this notebook.
Convolutions: it’s all about filters
The first key concept that we need to understand is the **convolution **operation. This is simple: we will apply a **filter **to an image to get a resulting image.
As an example, let’s suppose we have an input image and a filter:
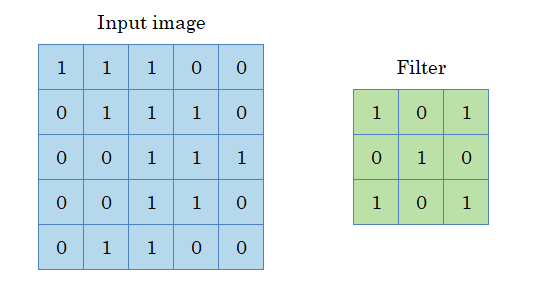
Source: own elaboration
Remember that any image can be represented as a matrix of pixels, with each pixel representing a color intensity:

What the convolution does is the following:
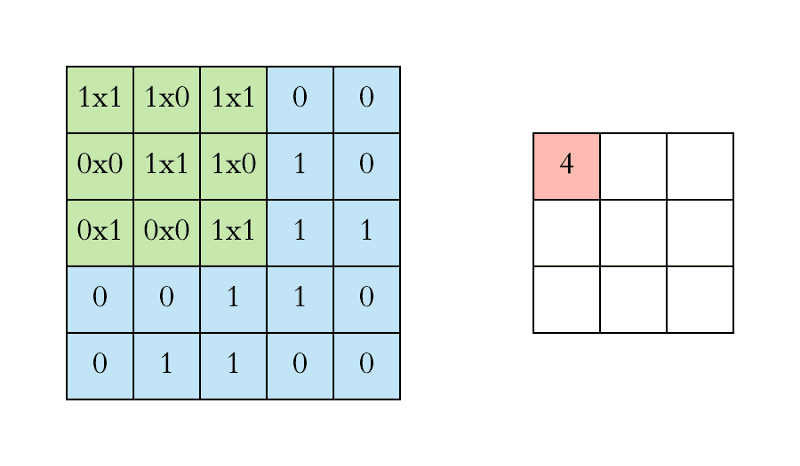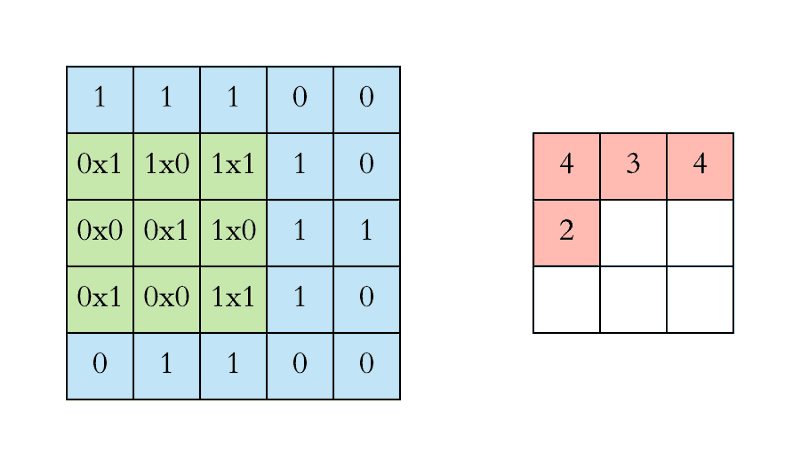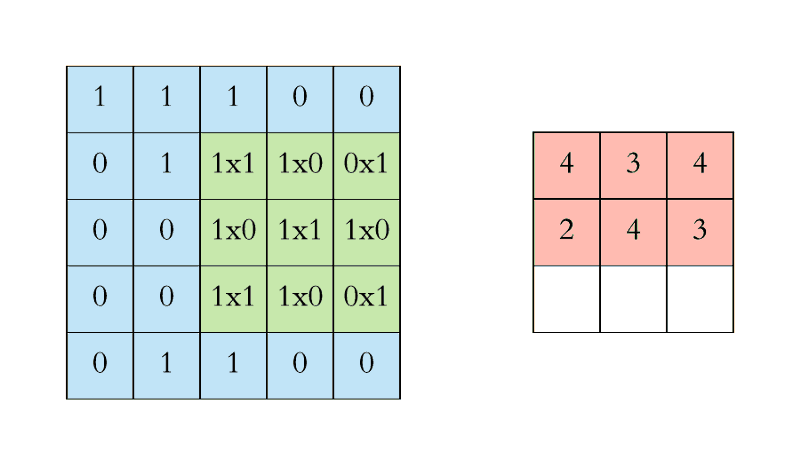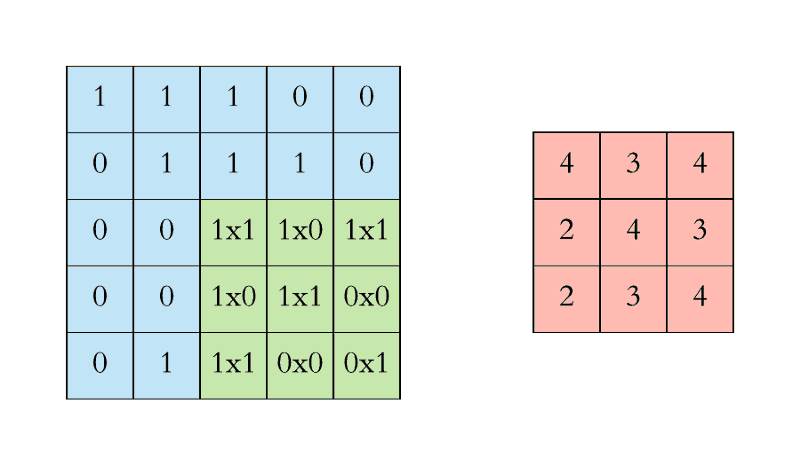
This is, we are building another image by applying the filter to our input image. Note that depending on the filter we apply (its shape and values), we will get a different image.
But, why would we want to do this? Seems that it doesn’t make much sense!
The truth is that it does makes a lot of sense. To understand why, let’s get a simple image of a black and white grid.

(Please note that this is no longer a matrix. It is in fact an image)
And apply some filters to it:
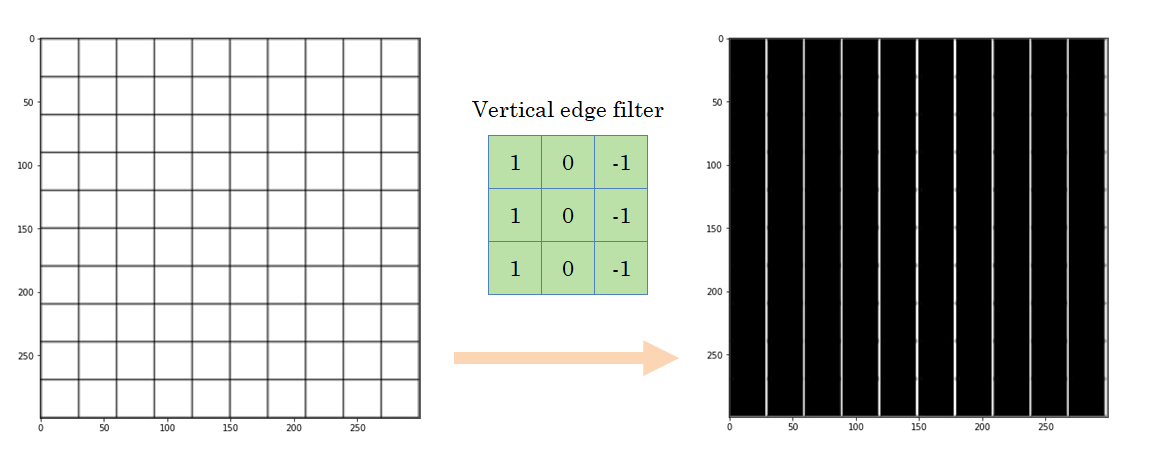
We can see that with that particular filter, the output image only contains the vertical edges. Let’s try some more:
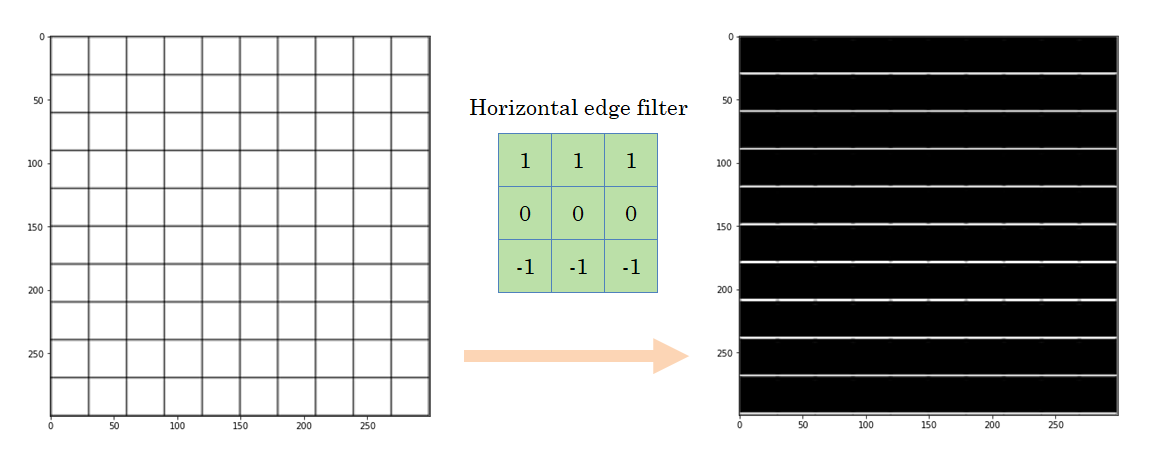
In this case, we only get the horizontal lines in the output image. Another different filter allows us to emphasize the edges, regardless of the orientation:
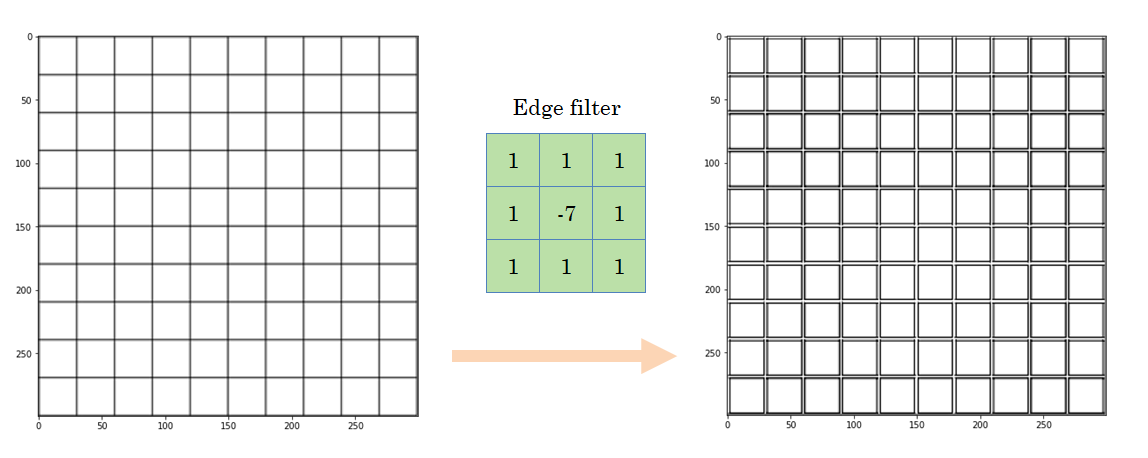
And, obviously, we can apply a filter that leaves the input image the same:
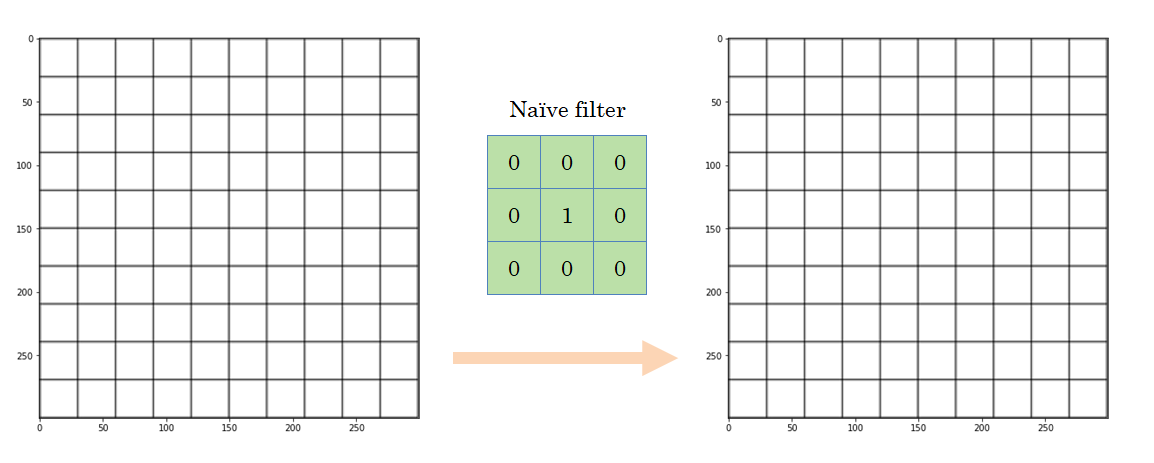
This is the idea behind the filters, and now you may better understand why they are called like that: they allow us to **retain **some kind of information from a picture, and **ignore **the rest. And this is possible because of how the convolution operation works.
#computer-vision #deep learning
