Pandas is a data analysis and manipulation library for Python. SQL is a programming language that is used by most relational database management systems (RDBMS) to manage a database. What they have in common is that both Pandas and SQL operate on tabular data (i.e. tables consist of rows and columns).
Although having different syntax, similar operations or queries can be done using Pandas or SQL. One of the most common operations in a typical data analysis process is to compare categories based on numerical features. Both are highly efficient in performing such tasks.
In this post, we will do many examples to master how these operations are done with the groupby function of Pandas and the GROUP BY statement of SQL.
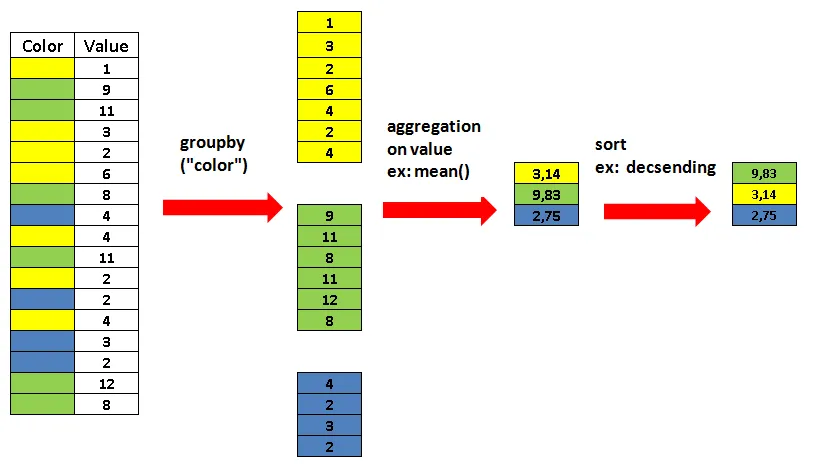
The following figure illustrates the logic behind a “groupby” operation.
Image for post
Groupby operation (image by author)
We will use the customer churn dataset that is available on Kaggle. For Pandas, the dataset is stored in the “churn” dataframe. For SQL, the data is in the “CHURN” table.
#data-science #artificial-intelligence #sql #machine-learning #data-analysis