Looks cool, right? But it begs the question: why learn data engineering in the first place?
Typically, data science teams are comprised of data analysts, data scientists, and data engineers. In a previous post, we’ve talked about the differences between these roles, but here let’s dive deeper into some of the advantages of being a data engineer.
Data engineers are the people who connect all the pieces of the data ecosystem within a company or institution. They accomplish this by doing things like:
- Accessing, collecting, auditing, and cleaning data from applications and systems into a usable state
- Creating and maintaining efficient databases
- Building data pipelines
- Monitoring and managing all the data systems (scalability, security, etc)
- Implementing data scientists’ output in a scalable manner
Doing everything listed above primarily requires one particular skill: programming. Data engineers are software engineers who specialize in data and data technologies.
That makes them quite different from data scientists, who certainly have programming skills, but who typically aren’t engineers. It’s not uncommon for data scientists to hand over their work (e.g., a recommendation system) to data engineers for actual implementation.
And while it’s data analysts and data scientists who are doing the analysis, it’s typically data engineers who are building the data pipelines and other systems necessary to make sure that everyone has easy access to the data they need (and that no one has access to the data who shouldn’t).
A strong foundation in software engineering and programming equips data engineers to build the tools data teams and their companies need to succeed. Or, as Jeff Magnusson put it: “I like to think of it in terms of Lego blocks. Engineers design new Lego blocks that data scientists assemble in creative ways to create new data science.”
This brings us to the first reason why you might want to become a data engineer:
1. Why Learn Data Engineering? It’s the Backbone of Data Science
Data engineers are on the front lines of data strategy so that others don’t need to be. They are the first people to tackle the influx of structured and unstructured data that enters a company’s systems. They are the foundation of any data strategy. Without Lego blocks, after all, you can’t build a Lego castle.
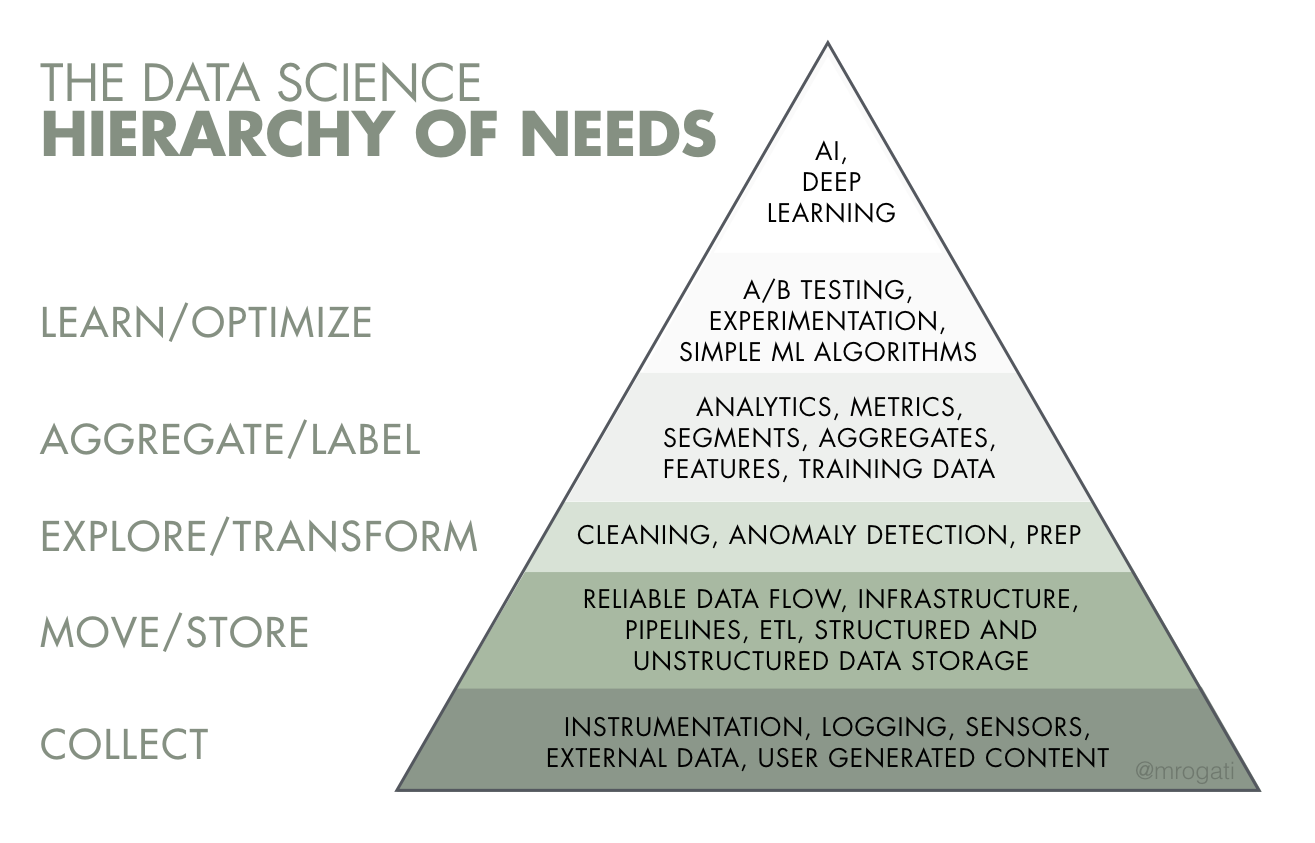
In the above Data Science Hierarchy of Needs (proposed by Monica Rogati), data engineers are completely responsible for the two bottom rows, and share responsibility with data analysts and data scientists for the third row from the bottom.
To gain a better understanding of how critical data engineering is, imagine the pyramid pictured above is used as a funnel and flipped upside down. Data is poured into the top of that funnel, and the first people to touch it are data engineers. The more efficient they are at filtering, cleaning, and directing that data, the more efficient everything else can be as the data flows further down the funnel and towards other team members.
Conversely, if the data engineers are not efficient, they can serve as a block in the funnel that harms the work of everyone downstream. If, for example, a poorly-built data pipeline ends up feeding the data science team incomplete data, any analysis they perform on that data may be useless.
In this way, data engineers act as multipliers of the outcomes of a data strategy. They are the giants on whose shoulders data analysts and data scientists stand.
This is evidenced in the way companies with good data strategies structure their teams. According to Jesse Anderson a data engineer and managing director of the Big Data Institute:
“A common starting point is 2-3 data engineers for every data scientist. For some organizations with more complex data engineering requirements, this can be 4-5 data engineers per data scientist.”
2. It’s Technically Challenging
One of the Python functions data analysts and scientists use the most is read_csv — from the pandas library. This function reads tabular data stored in a text file into Python, so that it can be explored and manipulated.
If you’ve worked with data in Python before, you’re probably very used to typing something like this:
import pandas as pd df = pd.read_csv("a_text_file.csv")
Easy and convenient, right? The read_csv function is a great example of the essence of software engineering: creating abstract, broad, efficient, and scalable solutions.
What does that mean and how does it relate to learning data engineering? Let’s take a deeper look.
- Abstract. When reading a file in a computer, a very complex process occurs under the hood. However, our use of the function is very simple, what goes on in the background is abstracted away from the usage. You don’t need to understand what
read_csvis doing “under the hood” to use it effectively. - Broad. This function also allows us to explicitly choose what delimiter is being used in the text’s file tabular data (e.g. commas, semicolons, tabs, and so on). This makes it easy to use with a variety of CSV styles, and that’s music to data scientists’ ears. And there are many other options that allow data practitioners to focus on their goals instead of having to worry about programming details.
- Efficient.
read_csvworks quickly and efficiently, and it’s also efficient to read in code. - Scalable. Another option included with this function allows us to read files by chunks, so that if a file is too large to read into the computer’s RAM, it can be read chunk by chunk, allowing users to process files as large as they come.
#learning and motivation #data engineer #data engineering #study #why #why learn
