Introduction
SQL Server 2016 provides a new feature Distributed Availability Group for disaster recovery purposes. It is a particular type of availability group that helps access the multiple failover clusters. In this article’s series, we configured a traditional Always On group. It has the following requirements.
- A failover cluster configuration
- Availability replicas should be part of the same failover configuration
- We should configure a SQL listener that always connects to the primary replica
This article explores the concept of the Distributed Availability Group and configures it for the demonstration purpose
SQL Server Distributed Availability Group
Suppose we have two independent failover clusters in your infrastructure. These clusters are configured with two separate SQL Server Always On availability groups. Suppose one of the clusters is in your primary site and the second cluster is in the disaster recovery site. SQL Server distributed availability group provides a solution to configure the availability groups between these clusters.
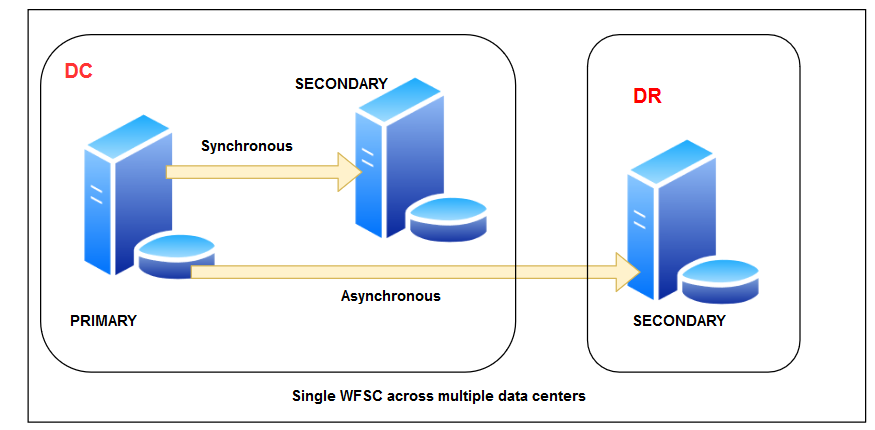
In a traditional SQL Server Always On Availability Groups, all replicas should be part of the failover cluster. We can implement a disaster recovery solution in a traditional AG, but you need to configure the DR server in the same failover cluster. You can configure an asynchronous data commit for the DR Availability group. It requires a geographically stretched failover cluster, as shown below. You need to do complex networking, firewall configurations. It also requires additional configurations such as CrossSubnetDelay, CrossSubnetThreshold using Windows PowerShell.
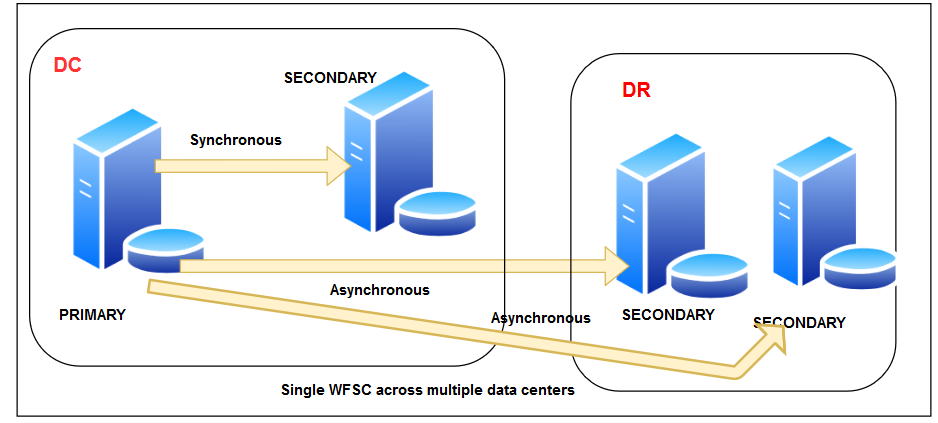
You can add multiple secondary replicas that receive the data from the primary SQL replica located in the leading site. In the below image, we see two DR nodes receiving asynchronous data from the primary replica. These four nodes are part of a single geographical cluster.
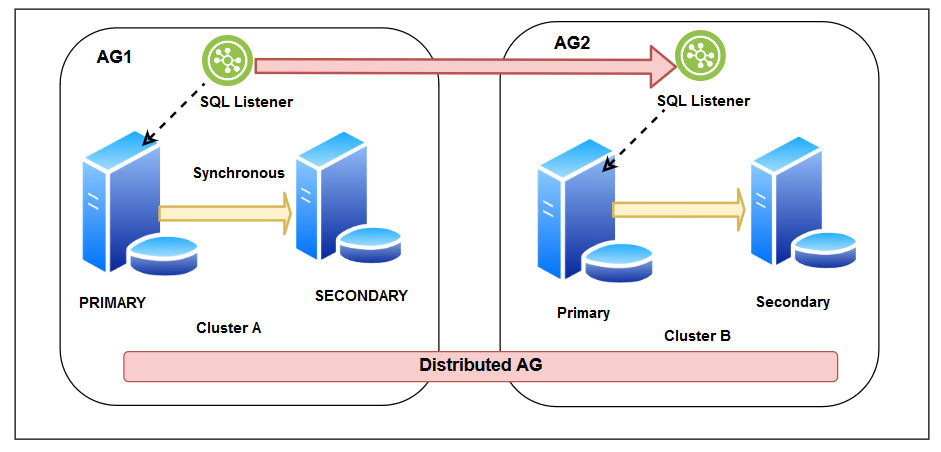
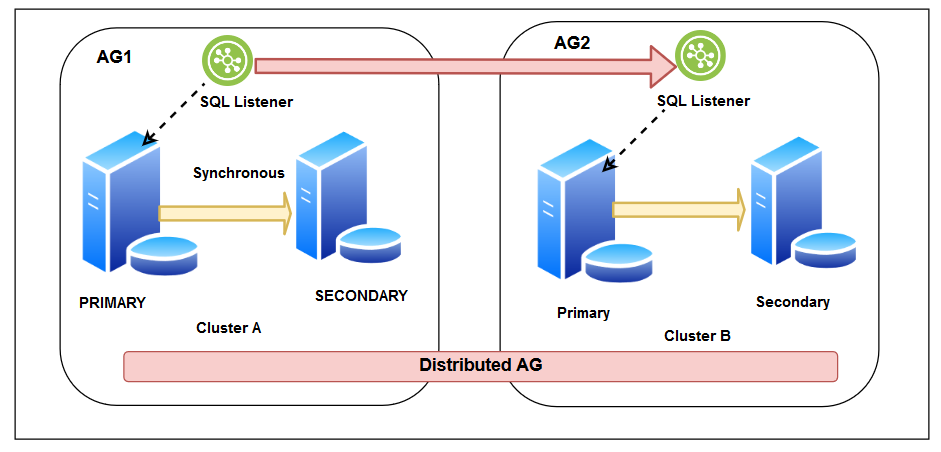
Now, suppose you have two separate sites, and you do not want to create a stretched cluster. Both clusters are independent of each other. You can configure the distributed availability group where the primary cluster is in the DC and secondary cluster in the DR.
As shown below, we create a distributed SQL Server Availability group with below configurations:
- You have a failover cluster in your primary site, and it has a synchronous replica between the two nodes. You configured a SQL listener to point applications to the primary replica
- You have another failover cluster in the DR site, and it also has synchronous data commit replica in its two nodes. You also configured another SQL listener in the DR cluster
- We created a distributed AG that connects the listener of both failover clusters hosted in the DC and DR site
- You can configure both synchronous or asynchronous data commit for a distributed availability group. In the synchronous data commit, primary replica waits for an acknowledgement from the secondary replica to commit the transaction. In case you prefer to configure the synchronous replica, you should consider the network bandwidth and transaction workload to avoid any impact on the application connecting to the primary replica in the DC site
#alwayson availability groups #installation #setup and configuration #sql