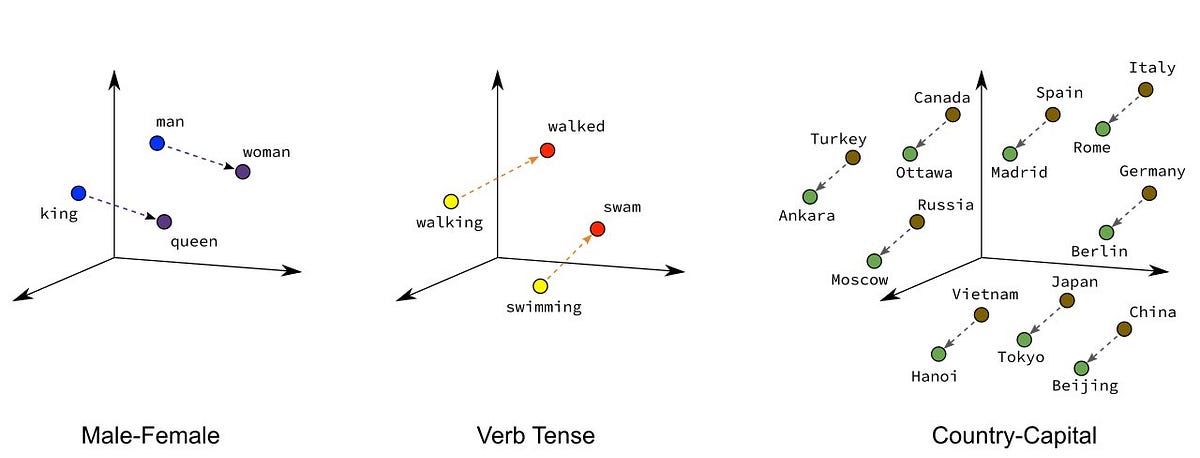
A fundamental issue with LegalTech is that words — the basic currency of all legal documentation — are a form of unstructured data that cannot be intuitively understood by machines. Therefore, in order to process textual documents, words have to be represented by vectors of real numbers.
Traditionally, methods like bag-of-words (BoW) map word tokens/n-grams to term frequency vectors, which represent the number of times a word has appeared in the document. Using one-hot encoding, each word token/n-gram is represented by a vector element and marked 0, 1, 2 etc depending on whether or the number of times that a word is present in the document. This means that if a word is absent in the corpus vocabulary, the element will be marked 0, and if it is present once, the element will be marked 1 etc.
#legaltech #legal-ai-software-market #word-embeddings #legal-ai #nlp