Today, memory and disk space are cheap, yet many applications are still paying a price for using poor quality word vector representations. Why are non-English language models particularly susceptible to being handicapped with poor quality word embeddings?

Before word embeddings, dictionary citations and concordances provided contextual hints. (Image by author)
The SpaCy NLP library offers models in English and many other languages, namely: German, French, Spanish, Portuguese, Italian, Dutch, Greek, Norwegian Bokmål, Lithuanian. However, there is a big discrepancy among the offerings. The English model is available in sizes small, medium and large — each growing in file size and memory demands. Each model has a fixed vocabulary, and a major component of the model’s file size is the word embeddings vector dimensions. One way to cut down on the file size is to use the hashing trick.
The Hashing Trick:
In machine learning, feature hashing, also known as the hashing trick (by analogy to the kernel trick), is a fast and space-efficient way of vectorizing features, i.e. turning arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values as indices directly, rather than looking the indices up in an associative array. [1]
In some situations, there’s nothing wrong with feature hashing, but when the resulting space is too restricted, collisions increase and performance decreases. Employing the hashing trick can create smaller word vector models (think 200,000 keywords mapping to just 20,000 floating point vectors). It appears the SpaCy medium-sized models built their word vector representations using a hashing trick with a lot of collisions, or perhaps they simply reused slots randomly— the medium-sized model vocabulary is fixed, so it’s hard to tell, but the effect is the same. Currently, there is only one SpaCy large model that uses full-sized embeddings — English. Meanwhile, all the non-English languages and medium-sized models save disk and memory space by reusing embedding slots. The tip-off is indicated in each medium-sized model specification, here’s the one for German:
Vectors 276k keys, 20k unique vectors (300 dimensions)
Yes, that’s 86.2% reuse! In practice this is a lot of hash collisions.
How do Hashed Word Embeddings perform compared to Full-Sized Embeddings?
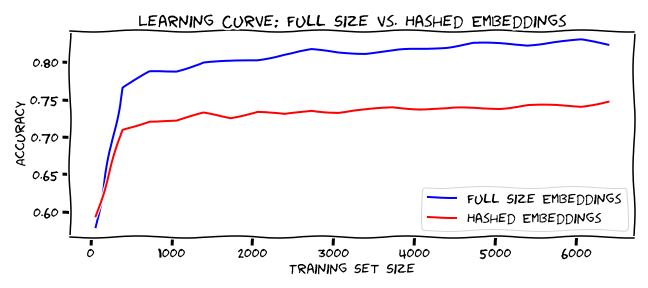
Sadly there’s nothing funny about word representations that consistently underperform. (Image by author)
Even with only 7,108 items of labeled data, using hashed word vectors resulted in 73% accuracy, instead of the 84% accuracy when using the full-sized embeddings (three classes for separation with a majority class baseline of 43%)[2]. The learning curve plot above shows how a machine learning model performs differently as it is trained on progressive amounts of data.
#spacy #word-embeddings #nlp #machine-learning #fasttext #deep learning