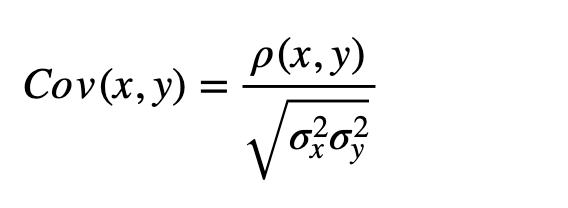Hi, everybody, my name is Andrea Grianti in Milan, Italy. I wrote this to share my thoughts after many books and papers read on the subject. This is not a textbook but a starting point for further understanding of the topic. As the math/algebra behind is rather tough I divided it into four parts:
- PCA Intuition
- Math/Algebra (easy)
- Math/Algebra (difficult)
- Python snippets
1. PCA Intuition
If you have a large data sets with thousands/millions of observations (rows) and hundreds of different variables (columns) one of the first objectives is verifying if it’s possible simplifying and reducing the dataset in order to facilitate the analysis work on a much smaller subset of the original data.
Direct elimination of variables is the obvious way but it has clearly impact on the information content of your data set. Too much or a wrong eliminations and your data set becomes useless, too less and the data set remains large and difficult to analyse.
The term ‘information’ is quite a generic subject and it’s difficult to define it. It depends on the data set. A data set could contain information for me and nothing to others and vice versa.
We could try to define the quantity of information in a data set using concepts like “Information Content” which is a concept bound to the probability that a specific value, among all those possible in the context of a variable of a data set, happens.
Following this concept, as much variety of possible outcomes a variable x has, lower is the probability to predict its value and therefore higher the information content is.
_This is our __first assumption _to keep in mind: higher variance => higher information content even if only the context and data can tell if this assumption is good or not.
As in our data set there are many variables, correlations will likely exist and if they are** linear **they can be considered a form of “background noise” and redundancy. As for the first assumption only the specific context can tell if linearity exists in the correlations. If the assumption holds we can then say that we should find a way to eliminate the background noise from our data.
W
hy these two assumptions are important ? Because to reduce the dimensionality of a data set we should evaluate the contribution of each variable to the overall variance(=information) of the dataset in order to choose those with the greatest contribution and discard those with lowest contribution.
The battlefield for this operation is the Covariance Matrix (or the Correlation Matrix which is closely linked by the relation below, but I don’t consider that here as it is not relevant in relation to the understanding the math principles behind)
#unsupervised-learning #python #analytics #mathematics #machine-learning