Learn how to Extract Tables in PDF using Camelot Library in Python
In this tutorial, you will learn how you can extract tables in PDF using camelot library in Python. Camelot is a Python library and a command-line tool that makes it easy for anyone to extract data tables trapped inside PDF files, check their official documentation and Github repository. Let’s dive in !
First, you need to install required dependencies for this library to work properly, and then you can install the library using the command line:
pip3 install camelot-py[cv]
Note that you need to make sure that you have Tkinter and ghostscript (which are the required dependencies) installed properly in your computer
Now that you have installed all requirements for this tutorial, open up a new Python file and follow along:
import camelot
# PDF file to extract tables from
file = "foo.pdf"
I have a PDF file in the current directory called “foo.pdf” which is a normal page that contains one table shown in the following image:
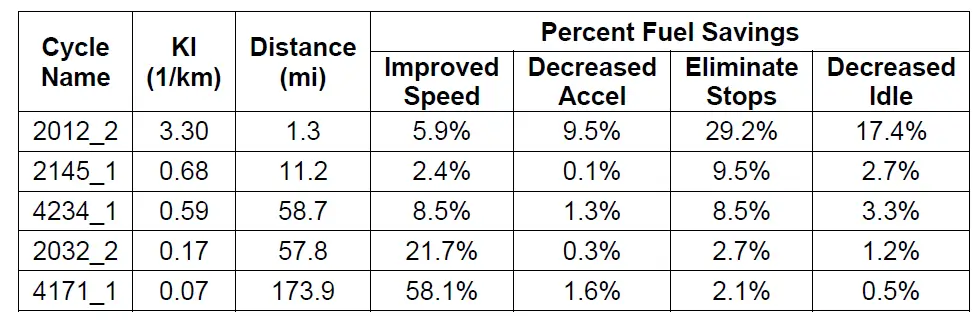
Just a random table, let’s extract it in Python:
# extract all the tables in the PDF file
tables = camelot.read_pdf(file)
read_pdf() function extracts all tables in a PDF file, let’s print number of tables extracted:
# number of tables extracted
print("Total tables extracted:", tables.n)
This outputs:
Total tables extracted: 1
Sure enough, it contains only one table, printing this table as a Pandas DataFrame:
# print the first table as Pandas DataFrame
print(tables[0].df)
Output:
0 1 2 3 4 5 6
0 Cycle \nName KI \n(1/km) Distance \n(mi) Percent Fuel Savings
1 Improved \nSpeed Decreased \nAccel Eliminate \nStops Decreased \nIdle
2 2012_2 3.30 1.3 5.9% 9.5% 29.2% 17.4%
3 2145_1 0.68 11.2 2.4% 0.1% 9.5% 2.7%
4 4234_1 0.59 58.7 8.5% 1.3% 8.5% 3.3%
5 2032_2 0.17 57.8 21.7% 0.3% 2.7% 1.2%
6 4171_1 0.07 173.9 58.1% 1.6% 2.1% 0.5%
That’s precise, let’s export the table to a CSV file:
# export individually
tables[0].to_csv("foo.csv")
Or if you want to export all tables in one go:
# or export all in a zip
tables.export("foo.csv", f="csv", compress=True)
f parameter indicates the file format, in this case “csv”. By setting compress parameter equals to True, this will create a ZIP file that contains all the tables in CSV format.
You can also export the tables to HTML format:
# export to HTML
tables.export("foo.html", f="html")
You can also export to other formats such as JSON and Excel.
It is worth to note that Camelot only works with text-based PDFs and not scanned documents. If you can click and drag to select text in your table in a PDF viewer, then it is a text-based PDF, so this will work on papers, books, documents and much more!
So this won’t convert image characters to digital text, if you wish so, I have a tutorial that uses OCR techniques to convert image optical characters to actual text that can be manipulated in Python.
Alright, this is it for this tutorial, check their official documentation for a more information.
GitHub: https://github.com/camelot-dev/camelot
#python #pdf
