Apache Spark is an open-sourced distributed computing framework, but it doesn’t manage the cluster of machines it runs on. You need a cluster manager (also called a scheduler) for that. The most commonly used one is Apache Hadoop YARN. Support for running Spark on Kubernetes was added with version 2.3, and Spark-on-k8s adoption has been accelerating ever since.
If you’re curious about the core notions of Spark-on-Kubernetes, the differences with Yarn as well as the benefits and drawbacks, read our previous article: The Pros And Cons of Running Spark on Kubernetes. For a deeper dive, you can also watch our session at Spark Summit 2020: Running Apache Spark on Kubernetes: Best Practices and Pitfalls.
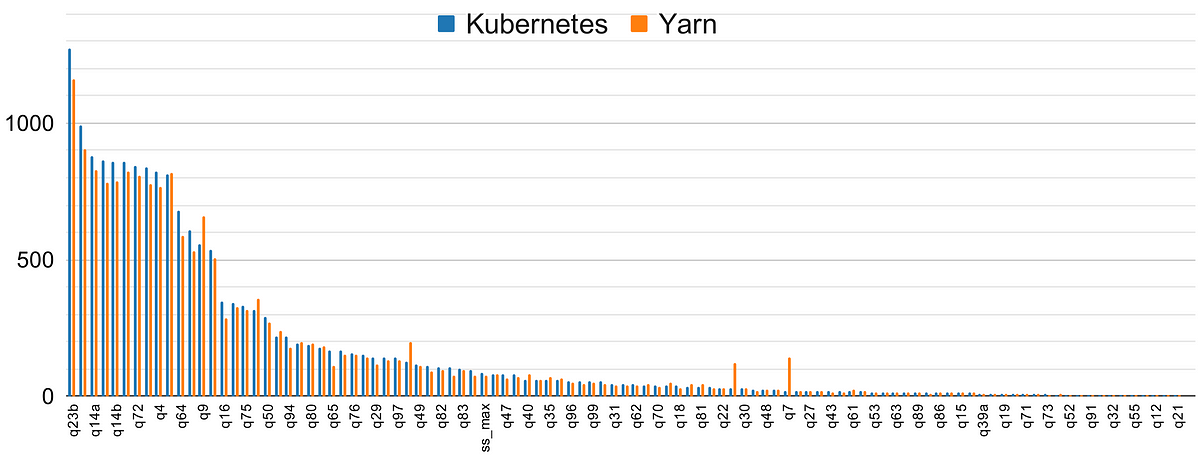
In this article, we present benchmarks comparing the performance of deploying Spark on Kubernetes versus Yarn. Our results indicate that Kubernetes has caught up with Yarn — there are no significant performance differences between the two anymore. In particular, we will compare the performance of shuffle between YARN and Kubernetes, and give you critical tips to make shuffle performant when running Spark on Kubernetes.
Benchmark protocol
The TPC-DS benchmark
We used the famous TPC-DS benchmark to compare Yarn and Kubernetes, as this is one of the most standard benchmark for Apache Spark and distributed computing in general. The TPC-DS benchmark consists of two things: data and queries.
- The data is synthetic and can be generated at different scales. It is skewed — meaning that some partitions are much larger than others — so as to represent real-word situations (ex: many more sales in July than in January). For this benchmark, we use a 1TB dataset.
- There are around 100 SQL queries, designed to cover most use cases of the average retail company (the TPC-DS tables are about stores, sales, catalogs, etc). As a result, the queries have different resource requirements: some have high CPU load, while others are IO-intensive.
What do we optimize for?
The performance of a distributed computing framework is multi-dimensional: cost and duration should be taken into account. For example, what is best between a query that lasts 10 hours and costs $10 and a 1-hour $200 query? This depends on the needs of your company.
In this benchmark, we gave a fixed amount of resources to Yarn and Kubernetes. As a result, the cost of a query is directly proportional to its duration. This allows us to compare the two schedulers on a single dimension: duration.
Setup
This benchmark compares Spark running Data Mechanics (deployed on Google Kubernetes Engine), and Spark running on Dataproc (GCP’s managed Hadoop offering).
Driver: n2-standard-4 instance
- 4 vCPUs
- 16GB RAM
5 executors on n2-highmem-4 instances
- 4 vCPUs
- 32GB RAM
- 375GB local SSD
We ran each query 5 times and reported the median duration.
We used the recently released 3.0 version of Spark in this benchmark. It brings substantial performance improvements over Spark 2.4, we’ll show these in a future blog post.
#data-science #data-engineering #kubernetes #apache-spark #big-data #data analysis