Do you still hold on to the parent/child design, or would like to try something new, like SQL Server hierarchyID? Well, it is really new because hierarchyID has been a part of SQL Server since 2008. Of course, the novelty itself is not a persuasive argument. But note that Microsoft added this feature to represent one-to-many relationships with multiple levels in a better way.
You may wonder what difference it makes and which benefits you get from using hierarchyID instead of the usual parent/child relationships. If you never explored this option, it might be surprising for you.
The truth is, I didn’t explore this option since it was released. However, when I finally did it, I found it a great innovation. It is a better-looking code, but it has much more in it. In this article, we are going to find out about all those excellent opportunities.
However, before we dive into the peculiarities of using SQL Server hierarchyID, let’s clarify its meaning and scope.
What is SQL Server HierarchyID?
SQL Server hierarchyID is a built-in data type designed to represent trees, which are the most common type of hierarchical data. Each item in a tree is called a node. In a table format, it is a row with a column of hierarchyID data type.
Usually, we demonstrate hierarchies using a table design. An ID column represents a node, and another column stands for the parent. With the SQL Server HierarchyID, we only need one column with a data type of hierarchyID.
When you query a table with a hierarchyID column, you see hexadecimal values. It is one of the visual images of a node. Another way is a string:
‘/’ stands for the root node;
‘/1/’, ‘/2/’, ‘/3/’ or ‘/n/’ stand for the children – direct descendants 1 to n;
‘/1/1/’ or ‘/1/2/’ are the “children of children – “grandchildren.” The string like ‘/1/2/’ means that the first child from the root has two children, which are, in their turn, two grandchildren of the root.
Here’s a sample of what it looks like:
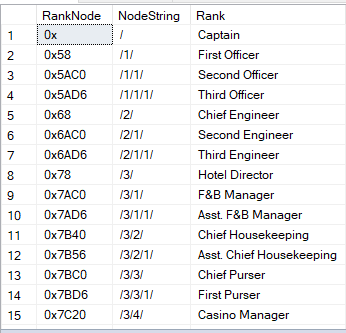 Figure 1: A sample output showing nodes (1st column) and node strings (2nd column)
Figure 1: A sample output showing nodes (1st column) and node strings (2nd column)
Unlike other data types, hierarchyID columns can take advantage of built-in methods. For example, if you have a hierarchyID column named RankNode, you can have the following syntax:
RankNode..
SQL Server HierarchyID Methods
One of the available methods is IsDescendantOf. It returns 1 if the current node is a descendant of a hierarchyID value.
You can write code with this method similar to the one below:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1
Other methods used with hierarchyID are the following:
- GetRoot – the static method that returns the root of the tree.
- GetDescendant – returns a child node of a parent.
- GetAncestor – returns a hierarchyID representing the nth ancestor of a given node.
- GetLevel – returns an integer that represents the depth of the node.
- ToString – returns the string with the logical representation of a node. ToString is called implicitly when the conversion from hierarchyID to the string type occurs.
- GetReparentedValue – moves a node from the old parent to the new parent.
- Parse – acts as the opposite of ToString. It converts the string view of a hierarchyID value to hexadecimal.
SQL Server HierarchyID Indexing Strategies
To ensure that queries for tables using hierarchyID run as fast as possible, you need to index the column. There are two indexing strategies:
DEPTH-FIRST
In a depth-first index, the subtree rows are closer to each other. It suits queries like finding a department, its subunits, and employees. Another example is a manager and its employees stored closer together.
In a table, you can implement a depth-first index by creating a clustered index for the nodes. Further, we perform one of our examples, just like that.
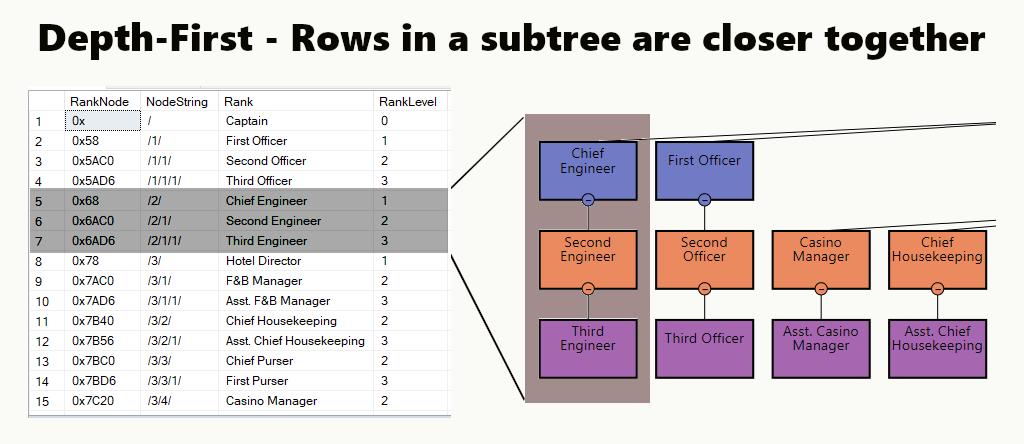 Figure 2: Depth-first indexing strategy. The Chief Engineer subtree is highlighted in the org. chart and the result set. The list is sorted based on each subtree.
Figure 2: Depth-first indexing strategy. The Chief Engineer subtree is highlighted in the org. chart and the result set. The list is sorted based on each subtree.
BREADTH-FIRST
In a breadth-first index, the same level’s rows are closer together. It suits queries like finding all the manager’s directly reporting employees. If most of the queries are similar to this, create a clustered index based on (1) level and (2) node.
![]() Figure 3: _Breadth-first indexing strategy. A portion of the second rank level is highlighted in the org. chart and the result set. The list is sorted based on the scale. _
Figure 3: _Breadth-first indexing strategy. A portion of the second rank level is highlighted in the org. chart and the result set. The list is sorted based on the scale. _
It depends on your requirements if you need a depth-first index, a breadth-first, or both. You need to balance between the importance of the queries type and the DML statements you execute on the table.
SQL Server HierarchyID Limitations
Unfortunately, using hierarchyID can’t resolve all issues:
- SQL Server can’t guess what the child of a parent is. You have to define the tree in the table.
- If you don’t use a unique constraint, the generated hierarchyID value won’t be unique. Handling this problem is the developer’s responsibility.
- Relationships of a parent and child nodes are not enforced like a foreign key relationship. Hence, before deleting a node, query for any descendants existing.
Visualizing Hierarchies
Before we proceed, consider one more question. Looking at the result set with node strings, do you find the hierarchy visualizing hard for your eyes?
For me, it’s a big yes because I am not getting younger.
For this reason, we are going to use Power BI and Hierarchy Chart from Akvelon along with our database tables. They will help to display the hierarchy in an organizational chart. I hope it will make the job easier.
Now, let’s get down to business.
Uses of SQL Server HierarchyID
You can use HierarchyID with the following business scenarios:
- Organizational structure
- Folders, subfolders, and files
- Tasks and subtasks in a project
- Pages and subpages of a website
- Geographical data with countries, regions, and cities
Even if your business scenario is similar to the above, and you rarely query across the hierarchy sections, you don’t need hierarchyID.
For example, your organization processes payrolls for employees. Do you need to access the subtree to process someone’s payroll? Not at all. However, if you process commissions of people in a multi-level marketing system, it can be different.
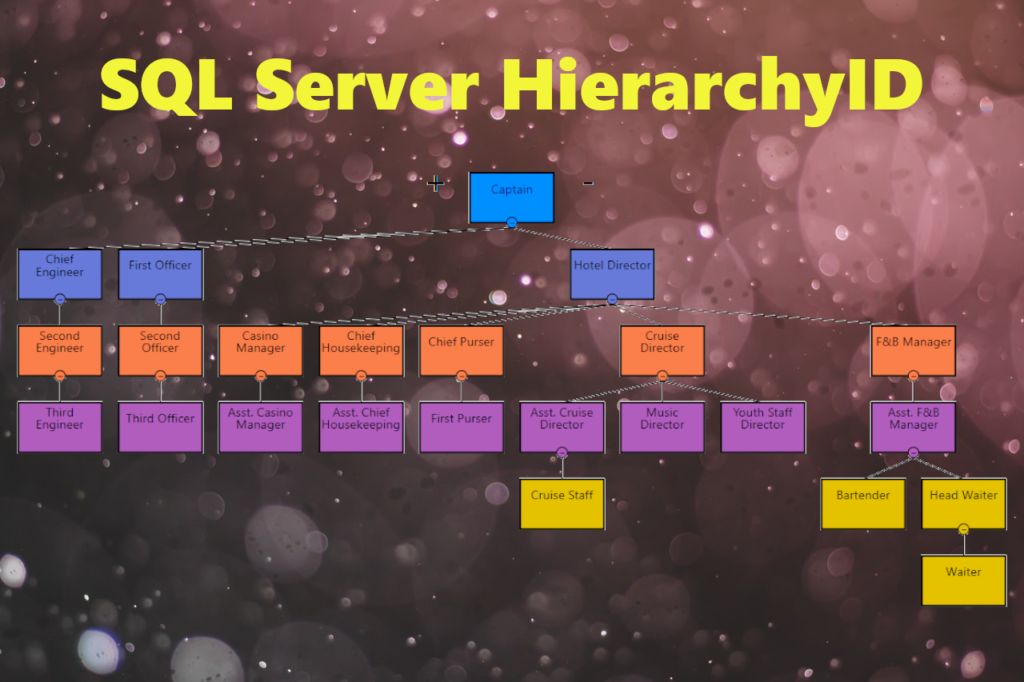
In this post, we use the portion of the organizational structure and the chain of command on a cruise ship. The structure was adapted from the organizational chart from here. Take a look at it in Figure 4 below:
 Figure 4: Organizational structure of a typical cruise ship rendered using Power BI, Hierarchy Chart by Akvelon, and SQL Server. Names are made-up and do not relate to actual people and cruise ships.
Figure 4: Organizational structure of a typical cruise ship rendered using Power BI, Hierarchy Chart by Akvelon, and SQL Server. Names are made-up and do not relate to actual people and cruise ships.
Now you can visualize the hierarchy in question. We use the below tables throughout this post:
- Vessels – is the table standing for the cruise ships’ list.
- Ranks – is the table of crew ranks. There we establish hierarchies using the hierarchyID.
- Crew – is the list of the crew of each vessel and their ranks.
The table structure of each case is as follows:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GO
#programming #sql server #how to #sql server #sql server hierarchyid #sql