Python, Spark, and Kafka are vital frameworks in data scientists’ day to day activities. It is essential to enable them to integrate these frameworks.
Introduction
Frequently, Data scientists prefer to use Python (in some cases, R) to develop machine learning models. Here, they have a valid justification since data-driven solutions arrive with many experiments. Numerous interactions with the language we use to develop the models are required to perform experiments, and the libraries and platforms available in python to develop machine-learning models are tremendous. This is a valid argument; however, we confront issues when these models are applied to production.
We still have the Python micro-service library such as Flask to deploy machine-learning models and publish it as API. Nevertheless, the question is, ‘can this cater for real-time analytics where you need to process millions of events in a millisecond of time?’ The answer is ‘no.’ This situation is my motivation to write this article.
To overcome all the above problems, I have identified a set of dots that could be appropriately connected. In this article, I attempt to connect these dots, which are Python, Apache Spark, and Apache Kafka.
The article is structured in the following order;
- Discuss the steps to perform to setup Apache Spark in a Linux environment.
- Starting Kafka (for more details, please refer to this article).
- Creating a PySpark app for consume and process the events and write back to Kafka.
- Steps to produce and consume events using Kafka-Python.
Installing Spark
The latest version of Apache Spark is available at http://spark.apache.org/downloads.html
Spark-2.3.2 was the latest version by the time I wrote this article.
Step 1: Download spark-2.3.2 to the local machine using the following command
wget http://www-us.apache.org/dist/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
Step 2: Unpack.
tar -xvf spark-2.1.1-bin-hadoop2.7.tgz
Step 3: Create soft links (optional).
This step is optional, but preferred; it facilitates upgrading spark versions in the future.
ln -s /home/xxx/spark-2.3.2-bin-hadoop2.7/ /home/xxx/spark
Step 4: Add SPARK_HOME entry to bashrc
#set spark related environment varibales
SPARK_HOME="/home/xxx/spark"
export PATH=$SPARK_HOME/bin:$PATH
export PATH=$SPARK_HOME/sbin:$PATH
Step 5: Verify the installation
pyspark
The following output would be visible on the console if everything were accurate:
Step 6: Start the master in this machine
start-master.sh
Spark Master Web GUI (the flowing screen) is accessible from the following URL: http://abc.def.com:8080/
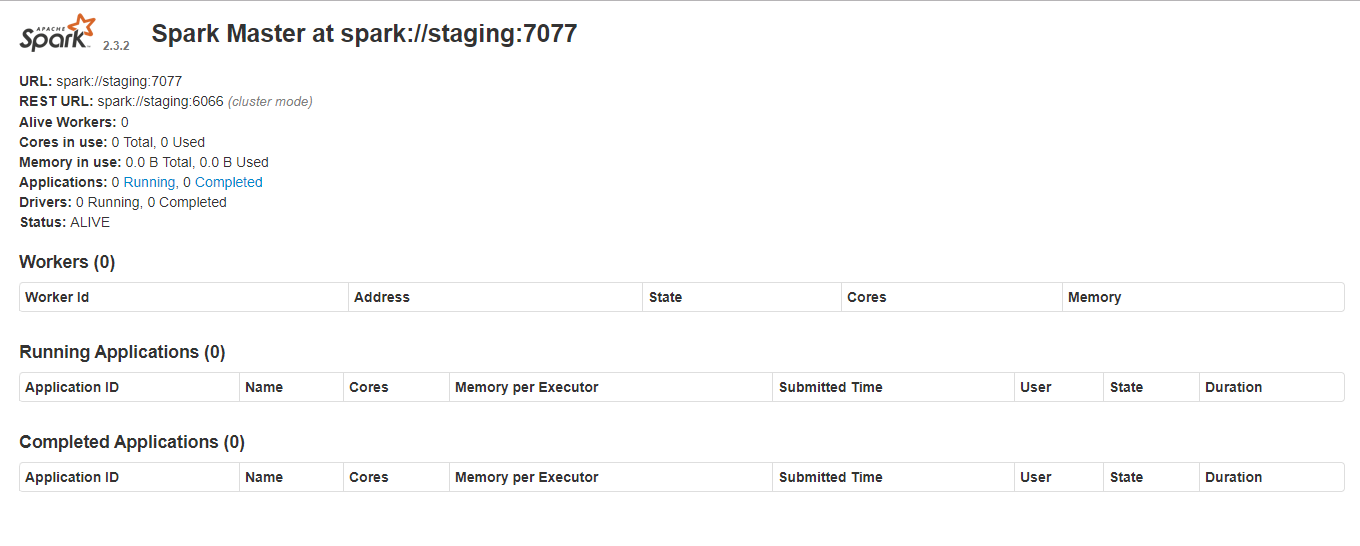
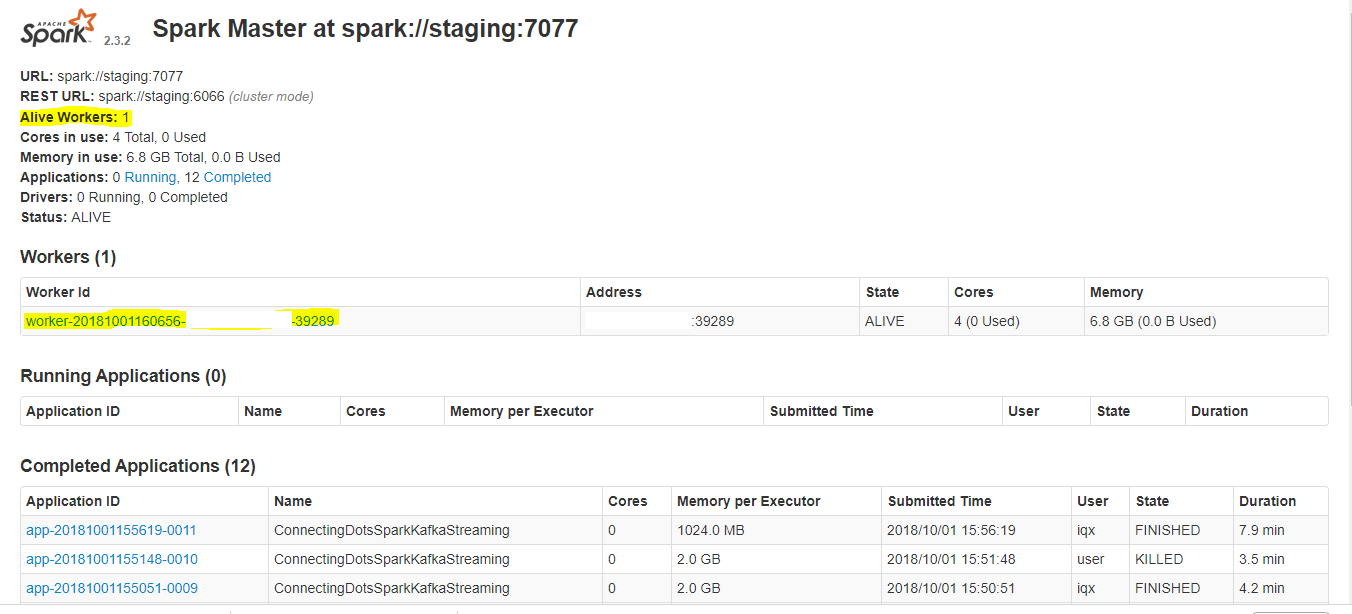
Step 7: Starting Worker
start-slave.sh spark://abc.def.ghi.jkl:7077
If everything were accurate, the entry for Workers would appear on the same screen.
#pyspark #apache-spark #spark #kafka #developer
