Previous Works
There have been numerous articles and online webinars dealing with the benefits of using Alluxio as an intermediate storage layer between the S3 data storage and the data processing system used for ingestion or retrieval of data (i.e. Spark, Presto), as depicted in the picture below:
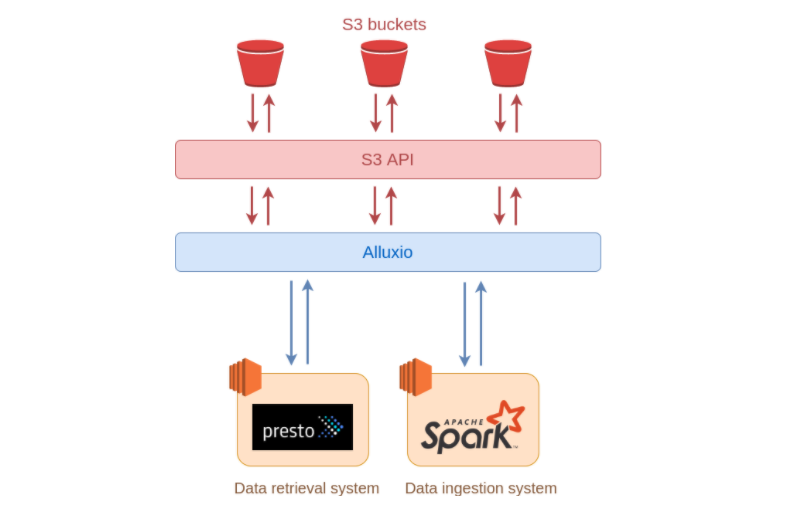
To name a few use cases:
- Alluxio-Presto use cases:
- Ryte
- ING
- Alluxio-Spark use cases:
- Bazaarvoice
The main conclusion from these use cases is that using Alluxio as a data orchestration layer has the following benefits:
- **lower latency **in data processing pipelines:
- Co-locating data and computation reduces network traffic
- **horizontal scalability **for usage concurrency:
- S3 API has limitations on the request rate for a given prefix
All these benefits are critical when deciding a production-grade data processing architecture, however one important benefit has so far not been sufficiently highlighted when choosing such architecture – cost reduction on the usage of the S3 API. This will be the focus of this article.
datasapiens
datasapiens is an international startup, based in Prague, that focuses primarily on helping companies to transform their business through data. We offer 3 key products:
#hadoop #apache spark #cloud storage #alluxio #benchmark #data engineering #aws s3 #apache hive #presto #data orchestration
