The customer experience is the next competitive battleground. ~ Jerry Gregoire
Your most unhappy customers are your greatest source of learning. ~ Bill Gates
For any business, customer goodwill is a key driver for success. Running an efficient and effective IT Services Management System goes a long way towards achieving customer goodwill and gaining the competitive edge.
Let us explore how Natural Language Processing (NLP) can be applied to reduce the Mean Time To Repair (MTTR) for service requests or incidents in production environments.
Let us see a hypothetical case study.
_Take Off Successful _:
“ABC Fashion” had launched their membership rewards program with a rejuvenated version of the online portal for customers. Behind the scenes, the IT infrastructure had 3 new applications that contributed to 15 more integrations between upstream and downstream systems. A 10-member IT Services team, internally divided into 3 sub-teams each handling a specific area of integration, had been delivering top quality services until the new program went live and disrupted a few things:
“Houston — we have problems” ! !
> Volume of service requests went up 5 times — partly due to customer’s lack of understanding of the new system and partly due to known issues in the integration of systems. Team was unable to abide by the Service Level Agreement (SLA) with such high volumes.
> Requests from customers covered a wide range of issues described in free text format which were difficult to categorize manually during analysis phase. Often, customers did not select the right categories and subcategories in the “Contact Us” web-forms that led to incorrect categorization and IT Services team assignments. Reassignments of such requests contribute to the MTTR.
> Volume of production incidents increased due to more integration points in the system. Some of the incidents could however be fixed by simple steps.
> Requests didn’t get the appropriate priority until a team member had analyzed the issue. For example, portal login failures or application downtime should have be addressed with highest priority whatever the default priority was set during the request creation.
Do we have a solution ?
_Thankfully, YES. Further brainstorming revealed that these problems could be mitigated _if the service requests and incidents are properly categorized and labeled before reaching the IT support teams.
A Request Classification System will solve this problem if it is:
- Automated: Done with zero human intervention.
- Content Based: Done based on the scrutiny of the actual matter contained within the request rather than manual guesses based on wrongly selected categories during creation.
- Real Time: Done in real time at the point of creation of the request or incident instead of waiting until a team member categorizes manually.
Machine Learning to save the day
Natural Language Processing (NLP) is a subfield of artificial intelligence concerned with interactions between computers and human (natural) languages. It is used to apply machine learning algorithms to text and speech.
For example, we can use NLP to create systems like speech recognition, document summarization, machine translation, spam detection, named entity recognition, question answering, autocomplete, predictive typing and so on.
For the problem in discussion, NLP can be used to make the classification “Content Based” where a trained model is used to predict a category by analyzing the content of the request.
NLP based systems have the following prerequisites:
- Text data should be pre-processed before feeding into the system. It should discard “unwanted” and “noise” data.
- Text data should be standardized and “encoded” into a format understandable by the model algorithm; raw text data cannot be fed into models. Usually, words or letters in text are encoded into numbers which in some way or the other represent its meaning to the model. For interested readers, here is a good explanation of Text Encoding: https://towardsdatascience.com/text-encoding-a-review-7c929514cccf
- Availability of accurately labeled datasets is a key to building good models that predict effectively. This is true for “Supervised Learning” where a model will learn features and patterns from a labeled dataset so that it can predict outcomes for unseen or new input data. For example, a model can “learn” that words like points , redeem, reward, earned etc. appearing in a request description can mean that the request should belong to category “Reward Points”. If historical service requests or incidents can be pulled and labeled properly for training the model, the better are the chances of getting a more accurate classifier.
- The target categories should be clearly defined for classification to work well. Number of categories should not be too low (resets the whole cause of this exercise) or too high (classifier will not be efficient to understand the right one). The categories should be clear and non-overlapping to avoid confusion for the model.
With these in mind, here is what a basic NLP approach to building a Service Request classifier may look like:

Typical Flow of an NLP based application development
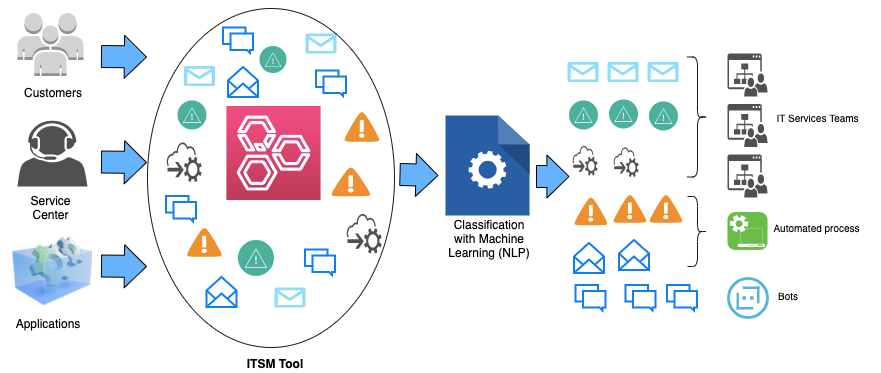
A 100 ft view of a basic solution
NLP is an ocean with tons and tons of text processing approaches and algorithms available to us, and it is continuously improving with each passing day as we try to get closer to the human expertise in understanding text.
However, simplicity pays off often when the problem at hand deserves so.
Let’s explore a very simple approach to solve the classification problem of ABC fashion store by following the development model mentioned above.
#incident-management #itsm #nlp #machine-learning #deep learning