Bagging, or bootstrap aggregating, is a unique idea in machine learning. Without adding any new data or knowledge, the concept postulates, one can still increase the accuracy of the model simply by adding an element of randomness. The idea is to train an ensemble of models, where each one is trained on a subset of the data, and then to aggregate the predictions of each model.
Because each model is trained on a randomly selected majority subset of the data — usually, somewhere between 60 percent to 75 percent — there will obviously be significant overlap in data. With this simple idea, however, bagging models like Random Forest perform almost universally better than their non-bagging counterparts, in this case the Decision Tree. No data is being added, though — existing data is simply incorporated with randomness — so how could the simple concept of bagging cause such a rise in model performance?
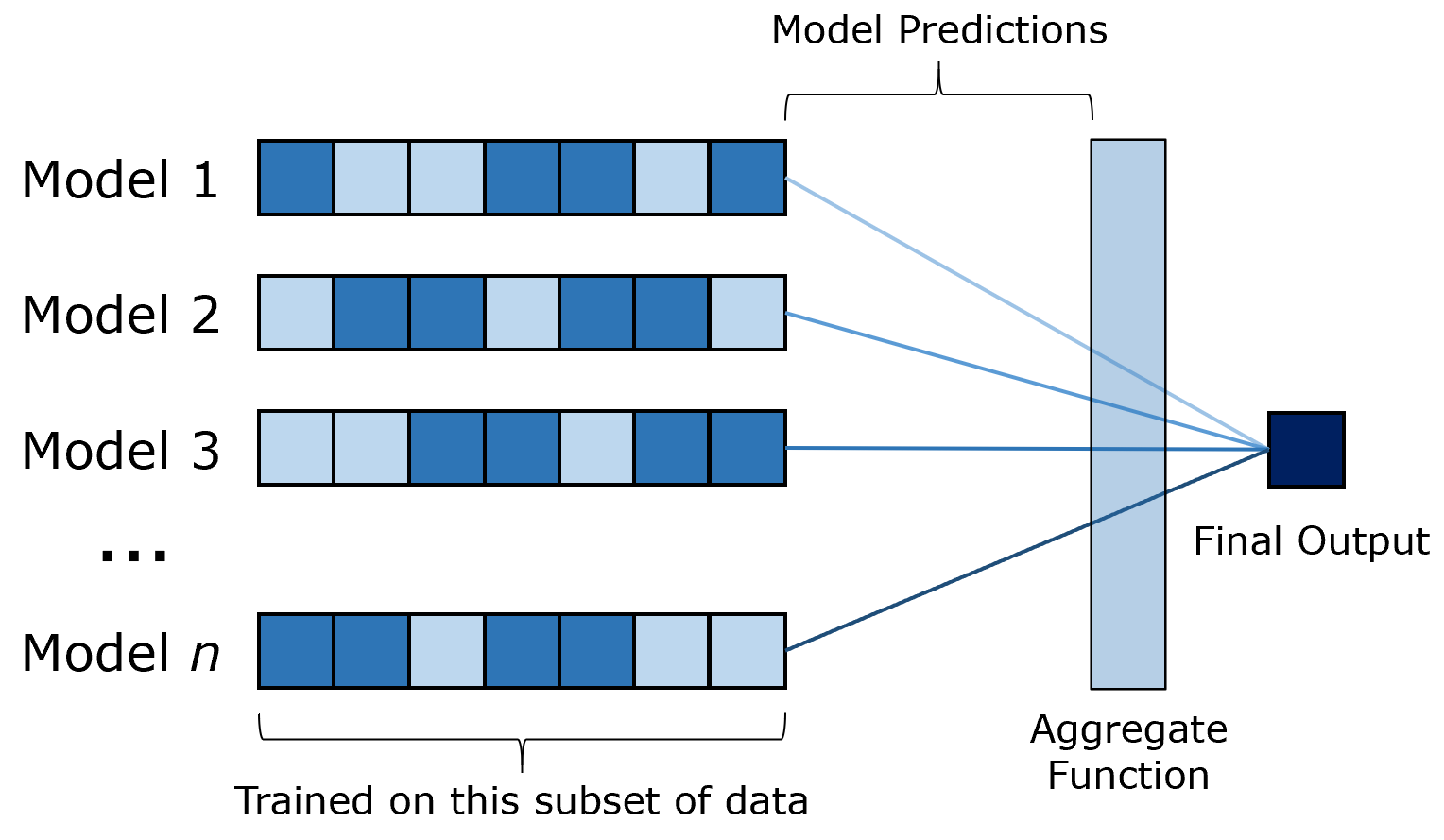
Image created by author.
To begin, it’s important to gain an intuitive understanding of the fact that bagging reduces variance. Although there are a few cases in which this would not be true, generally this statement is true. As an example, take a look at the sine wave from x-values 0 to 20, with random noise pulled from a normal distribution. Obviously, this is very noisy data, and a high-variance algorithm like Decision Tree may get caught up in the high level of randomness and hence generalize poorly.
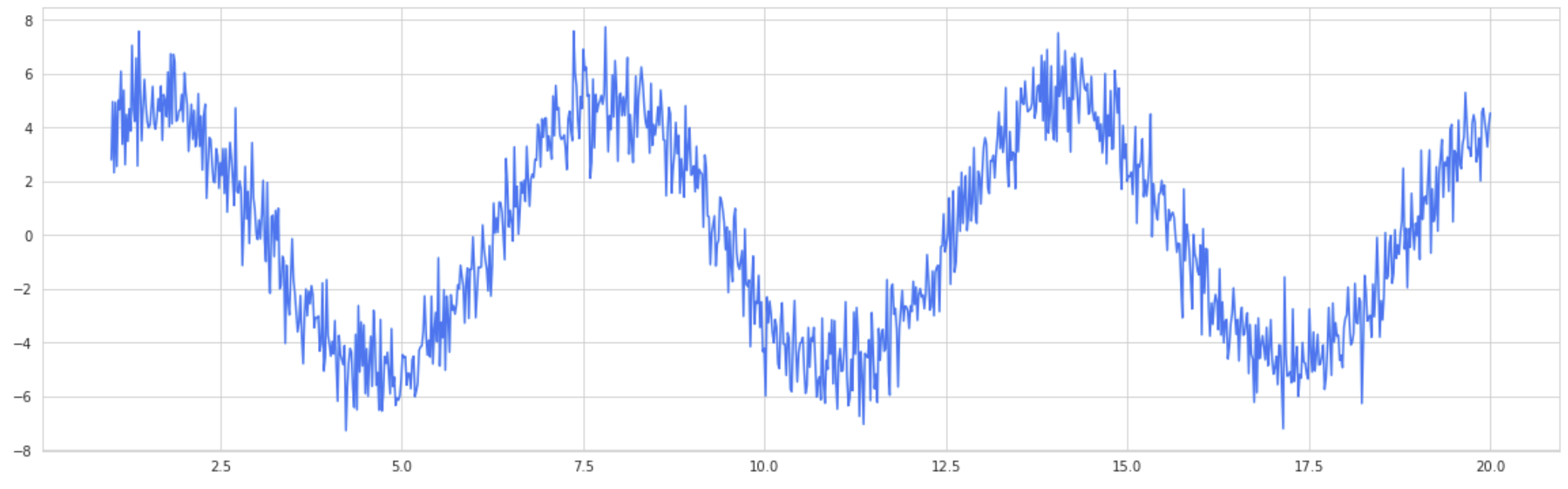
Image created by author.
Consider, on the other hand, a bagged model. To produce this visualization, ten separate curves were plotted, each containing a randomly selected twenty percent of the original data. The points were then averaged with respect to the values of the points around it to form a ‘bagged’ curve, which drastically reduces the variance and noise.
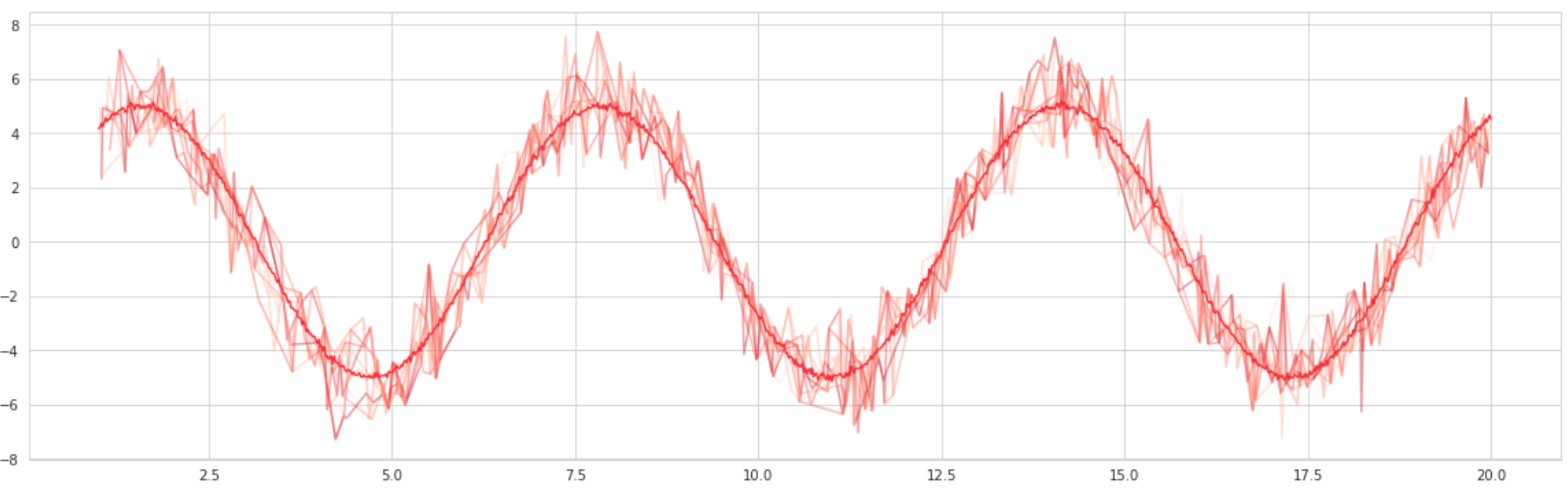
Image created by author.
It is immediately clear that bootstrapping artificially ‘smooths out’ heavy variance because of randomness. When randomness is added into the system, the positive randomness and the negative randomness cancel each other out. Through repeated overlap of data, the high variance is weeded out and a more clean relationship favored and revealed.
Since the mean squared error (MSE) of a model is equal to v + _b_², where v represents variance and b bias, naturally if the variance is lowered, the MSE will decrease. In some scenarios, when variance lowers, the bias will increase. Since the calculation of the MSE weights growth in the bias as a square whereas the variance simply as itself, in this scenario bagging actually decreases performance.
In most cases, however, it is possible to decrease variance without correspondingly increasing the bias. This can be illustrated with the example of the sine wave, in which variance was decreased, but the relationship only became more clear instead of becoming more biased.
Although the variance reduction explanation for the success of bagging is intuitive and widely believed, it has not been proven empirically to be necessarily as accurate as it could be. Another explanation for bootstrap aggregating’s success is that bagging equals influence. The central concept of this idea revolves around the idea of leverage, which is a measure of how much influence a point has over a model. A high-leverage point’s presence would hence influence the model significantly — for instance, the influence of an outlier on the coefficients of linear regression.
#machine-learning #statistics #ai #data-analysis #data-science #data analysis