In this blog post, we demonstrate how to use Algorithmia Insights to monitor for model drift—then turn these insights into action for more effective model governance.
Preventing model drift with continuous monitoring and deployment using Github Actions and Algorithmia Insights
Machine learning governance is an essential component of an organization’s overall ML framework, especially when machine learning models get to production. Once companies get to this stage, rules and processes around model management, immutability, and observability become even more important. One component of effective model governance is ensuring that models perform accurately over time. That’s why it’s essential that organizations not only deploy models to production through automated and traceable processes, but that they also monitor and act on model drift in production.
Advocating for these best practices, our recent blog post demonstrated how you can continuously train and deploy your machine learning models from your Jupyter notebook to Algorithmia with our automated workflows on Github Actions.
With the recent release of Algorithmia Insights, you can now funnel algorithm metrics to a Kafka topic and monitor that insights stream using a preferred monitoring application.
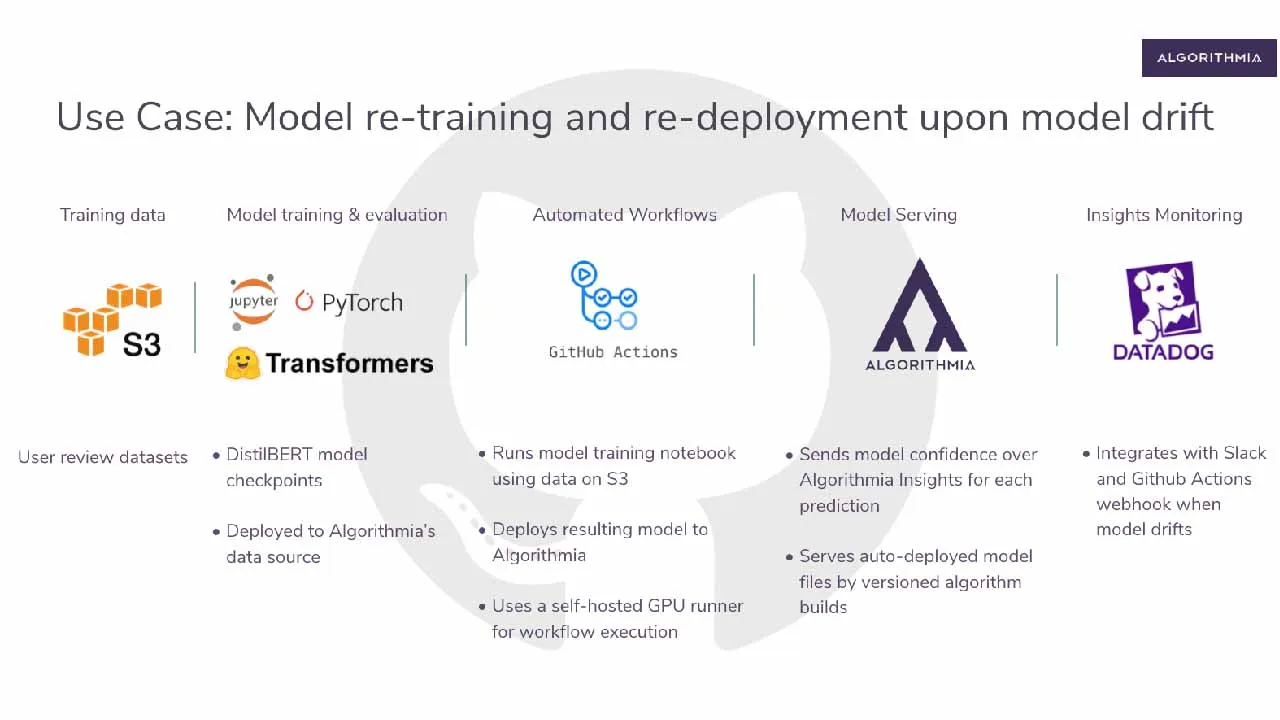
In this blog post, we will take things one step further and demonstrate how you can turn these insights into actionable items. We will talk about how you can trigger your machine learning model’s re-training and re-deployment using Github Actions when your model’s monitored metrics deteriorate. With this integration in place, you’ll see how you can build a new version of your algorithm with Algorithmia by using a rule-based automation process that fixes your model metrics in production by re-deploying your improved model.
As usual, let’s walk through an example use case to demonstrate each part of this integration.
#demos #github