The Apache Spark UI, the open source monitoring tool shipped with Apache® Spark is the main interface Spark developers use to understand their application performance. And yet, it generates a LOT of frustrations. We keep hearing it over and over, from Apache Spark beginners and experts alike:
- “It’s hard to understand what’s going on”
- “Even if there’s a critical information, it’s buried behind a lot of noisy information that only experts know how to navigate”
- “There’s a lot of tribal knowledge involved”
- “The Spark history server is a pain to setup”
At Data Mechanics we have the crazy ambition of replacing the Spark UI and Spark History Server with something delightful, let’s call it the Spark Delight.
We plan to make it work on top of any Apache Spark platform, entirely free of charge. We have a working prototype. Before we move to production, we’d like to get feedback and sense the interest from the community. If you find this project interesting, share this article and sign up with your email so we notify you when Spark Delight is released!
What’s wrong with the current Spark UI?
The familiar Spark UI (jobs page)
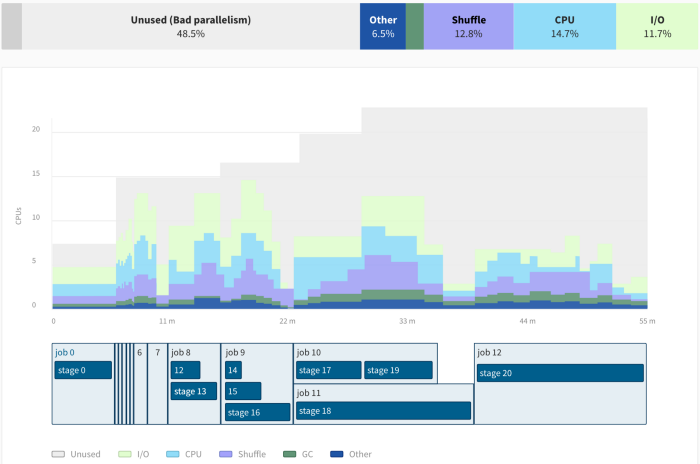
It’s hard to get the bird’s eye view of what is going on.
- Which jobs/stages took most of the time? How do they match with my code?
- Is there a stability or performance issue that matters?
- What is the bottleneck of my app (I/O bound, CPU bound, Memory bound)?
The Spark UI lacks essential node metrics (CPU, Memory and I/O usage).
- You can go without them, but you’ll be walking in the dark. Changing an instance type will be a leap of faith.
- Or you’ll need to setup a separate metrics monitoring system: Ganglia, Prometheus + Grafana, StackDriver (GCP), or CloudWatch (AWS).
- You’ll need to jump back and forth between this monitoring system and the Spark UI trying to match the timestamps between the two (usually jumping between UTC and your local timezone, to increase the fun).
The Spark History Server (rendering the Spark UI after an application is finished) is hard to setup.
- You need to persist Spark event logs to long-term storage and often run it yourself, incurring costs and maintenance burden.
- It takes a long time to load, and it sometimes crashes.
#spark #apache-spark #apache