· GETTING STARTED WITH AIRFLOW
· RUN AIRFLOW SERVER AND SCHEDULER
· AIRFLOW PIPELINE — DAG DEFINITION FILE
· ADDING DAG AND TASKS DOCUMENTATION
· CHECKING METADATA THROUGH COMMAND LINE
For cloud solution for Airflow, refer Google Cloud Composer, and a cloud alternative as Amazon Glue.
WHAT IS DATA PIPELINE
A Data Pipeline describes and encode a series of sequential data processing steps. Depending on the data requirements for each step, some steps may occur in parallel. Schedules are the most common mechanism for triggering an execution of a data pipeline, external triggers and events can also be used to execute data pipelines. ETL or ELT are the common patterns found in data pipelines, but not strictly required. Some data pipelines perform only a subset of ETL or ELT.
Data Validation_ is the process of ensuring that data is present, correct & meaningful. Ensuring the quality of your data through automated validation checks is a critical step in building data pipelines at any organization. Validation can and should become part of your pipeline definitions._
Data pipelines are well-expressed as Directed acyclic graphs (DAGs).
WHAT IS APACHE AIRFLOW?
Apache Airflow_ is a workflow orchestration tool — platform to programmatically author, schedule, and monitor workflows._
Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies.
Airbnb_ open-sourced Airflow in 2015 with the goal of creating a DAG-based, schedulable, data-pipeline tool that could run in mission-critical environments._
Airflow’s source code is available at [**_github.com/apache/airflow_**](https://github.com/apache/airflow), and can be installed by installing [**_apache-airflow_**](https://airflow.apache.org/docs/stable/installation.html) package using _pip_. One can setup Airflow using Airflow Quick Start Guide.
AWS cloud specific serverless version of Airflow is available as Amazon Glue. If you are using AWS, then still it makes sense to use Airflow to handle the data pipeline for all things outside of AWS (e.g. pulling in records from an API and storing in S3).
Refer Airflow Documentation for details, but first you might like to go through Airflow Concepts such as DAGs, Operators, Operator Relationships, Tasks, Task Instance, Schedules, Hooks, Connections, etc.
For configuring Airflow for production-guide environment, check How-to Guides.
HOW AIRFLOW WORKS?
Airflow is partner for data-frameworks, but not a replacement:
Airflow itself is not a data processing framework, in Airflow you don’t pass data in memory between steps in your DAG. Instead, you’re going to use Airflow to coordinate the movement of data between other data storage and data processing tools.
So, we are not going to pass data between step sand task and we will not typically run heavy processing workloads on Airflow. Reason for this is that Airflow workers often have less memory and processing power individually and some data-frameworks offer an aggregate. Tools like Spark are able to expose the computing power of many machines all at once. Whereas in Airflow you will always be limited to processing power of a single machine (the machine on which an individual worker is running). This is why Airflow developers prefer to use Airflow to trigger heavy processing steps in analytics warehouses like Redshift or data-framework works like Spark, instead within Airflow itself. Airflow can be thought of as a partner to those data-frameworks but not as a replacement.
For example,
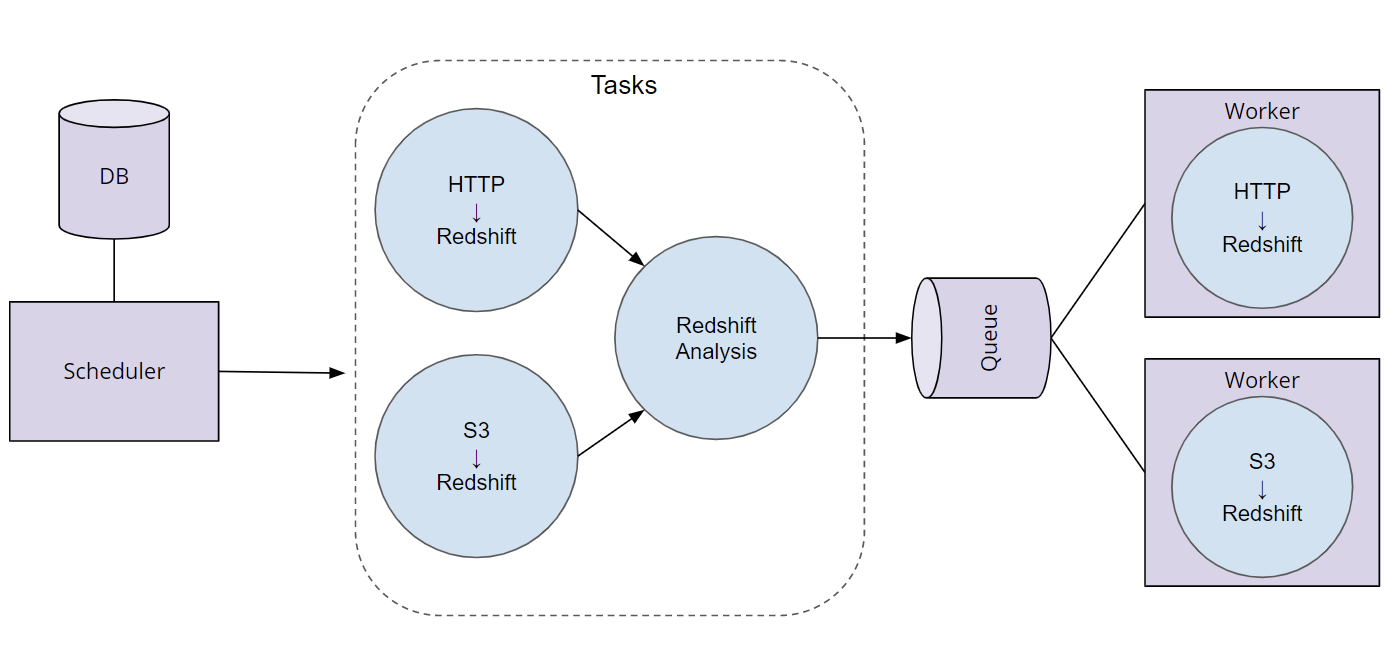
Airflow is designed to codify the definition and execution of data pipelines.
Airflow Components:

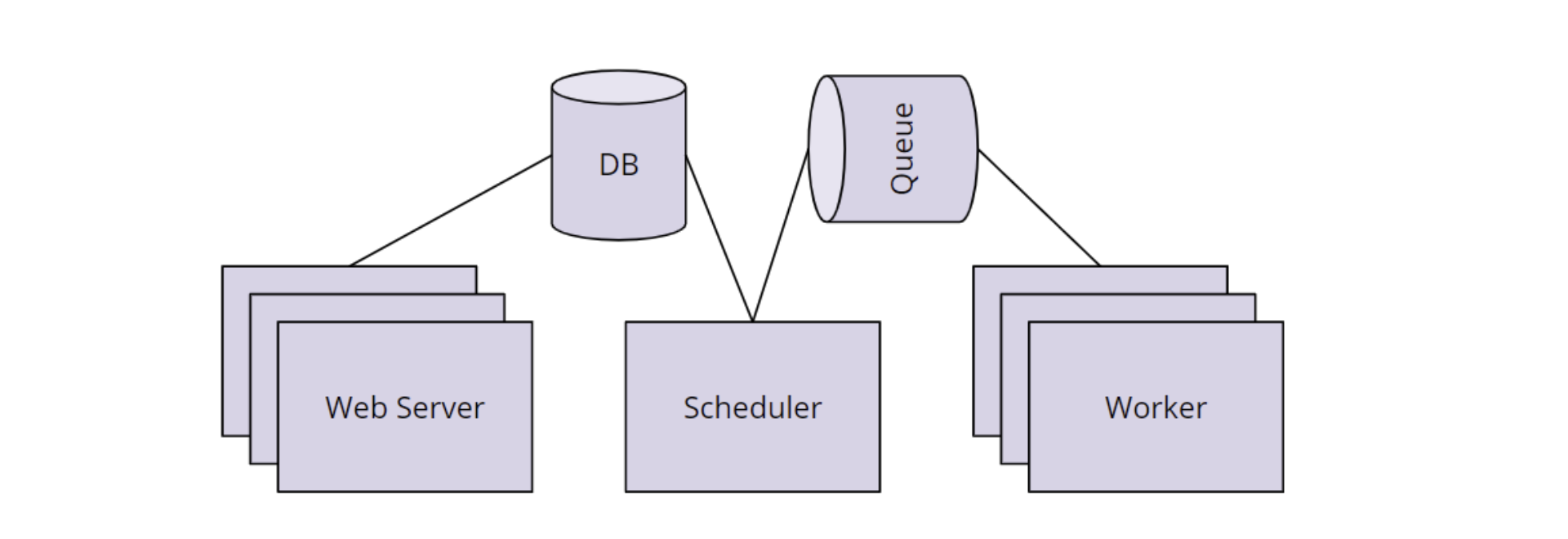
Here are the main components of Airflow:
- Scheduler Orchestrates the execution of jobs on a trigger or schedule. The Scheduler chooses how to prioritize the running and execution of tasks within the system.
- Worker Queue is used by scheduler in most Airflow installations to deliver tasks that need to be run to the Workers.
- Worker processes execute the operations defined in each DAG. In most Airflow installations, workers pull from work queue when it is ready to process a task. When the worker completes the execution of the task, it will attempt to process more work from the work queue until there is no further work remaining. When work in the queue arrives, the worker will begin to process it. In multi-node airflow architecture, daemon processes are distributed across all worker nodes. The web server and scheduler are installed at master node, and workers would be installed at each different worker nodes. To this mode of architecture, Airflow has to be configured with CeleryExecutor.
- Database saves credentials, connections, history, and configuration. The database, often referred to as the metadata database, also stores the state of all task in the system. Airflow components interact with the database with the Python ORM, SQLAlchemy.
- Web Interface provides a control dashboard for users and maintainers. The web interface is built using the Flask web-development micro-framework.
Data Partitioning:
Pipeline data partitioning is the process of isolating data to be analyzed by one or more attributes, such as time, logical type, or data size.
Data partitioning often leads to faster and more reliable pipelines.
Pipelines designed to work with partitioned data fail more gracefully. Smaller datasets, smaller time periods, and related concepts are easier to debug than big datasets, large time periods, and unrelated concepts. Partitioning makes debugging and re-running failed tasks much simpler. It also enables easier redos of work, reducing cost and time.
Another great thing about Airflow is that if your data is partitioned appropriately, your tasks will naturally have fewer dependencies on each other. Because of this, Airflow will be able to parallelize execution of your DAGs to produce your results even faster.
Data Lineage:
The data lineage of a dataset describes the discrete steps involved in the creation, movement, and calculation of that dataset.
Being able to describe the data lineage of a given data will build confidence in the consumers of that data that our data pipeline is creating a meaningful results using the correct data sets. Describing and servicing data lineage is one of the key ways we can ensure that everyone in the organization has access to and understands where data originates and how it is calculated.
The Airflow UI parses our DAGs and surfaces a visualization of the graph. Airflow keeps track of all runs of a particular DAG as tasks instances.
Airflow also shows us the rendered code for each task. One thing to keep in min: Airflow keeps a record of historical DAGs and task execution but it does not store the data from those historical runs. Whatever the latest code is in your DAG definition, is what Airflow will render for you in the browser. So, be careful in making assumptions about what was run historically.
GETTING STARTED WITH AIRFLOW
Check [**_stocks_**](http://0.0.0.0:8000/programs/stocks) project for example on basic setup.
Airflow keeps its configuration files in _AIRFLOW_HOME_, by default which is set to _~/airflow_.
Airflow requires a database to be initiated before you can run tasks. If you’re just experimenting and learning Airflow, you can stick with the default _SQLite_ option (but _SQLite_ works with _SequentialExecutor_ and hence runs in sequences).
#data-science #data-engineering #data #airflow #data-pipeline #data analysis
