Static code analysis refers to the technique of approximating the runtime behavior of a program. In other words, it is the process of predicting the output of a program without actually executing it.
Lately, however, the term “Static Code Analysis” is more commonly used to refer to one of the applications of this technique rather than the technique itself — program comprehension — understanding the program and detecting issues in it (anything from syntax errors to type mismatches, performance hogs likely bugs, security loopholes, etc.). This is the usage we’d be referring to throughout this post.
“The refinement of techniques for the prompt discovery of error serves as well as any other as a hallmark of what we mean by science.”
- J. Robert Oppenheimer
Outline
We cover a lot of ground in this post. The aim is to build an understanding of static code analysis and to equip you with the basic theory, and the right tools so that you can write analyzers on your own.
We start our journey with laying down the essential parts of the pipeline which a compiler follows to understand what a piece of code does. We learn where to tap points in this pipeline to plug in our analyzers and extract meaningful information. In the latter half, we get our feet wet, and write four such static analyzers, completely from scratch, in Python.
Note that although the ideas here are discussed in light of Python, static code analyzers across all programming languages are carved out along similar lines. We chose Python because of the availability of an easy to use ast module, and wide adoption of the language itself.
How does it all work?
Before a computer can finally “understand” and execute a piece of code, it goes through a series of complicated transformations:
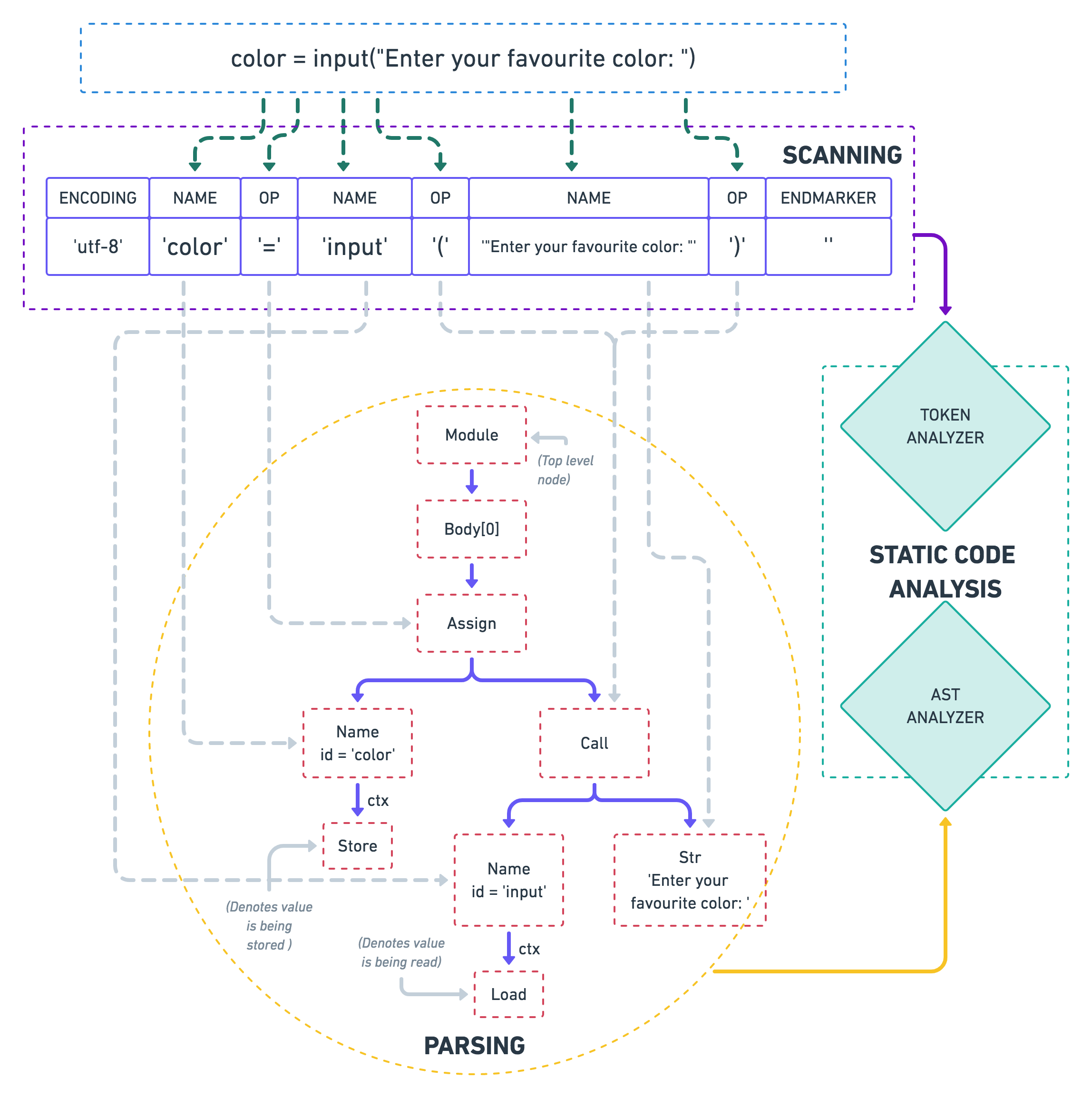
As you can see in the diagram (go ahead, zoom it!), the static analyzers feed on the output of these stages. To be able to better understand the static analysis techniques, let’s look at each of these steps in some more detail:
Scanning
The first thing that a compiler does when trying to understand a piece of code is to break it down into smaller chunks, also known as tokens. Tokens are akin to what words are in a language.
A token might consist of either a single character, like (, or literals (like integers, strings, e.g., 7, Bob, etc.), or reserved keywords of that language (e.g, def in Python). Characters which do not contribute towards the semantics of a program, like trailing whitespace, comments, etc. are often discarded by the scanner.
Python provides the tokenize module in its standard library to let you play around with tokens:
Python
1
import io
2
import tokenize
3
4
code = b"color = input('Enter your favourite color: ')"
5
6
for token in tokenize.tokenize(io.BytesIO(code).readline):
7
print(token)
Python
1
TokenInfo(type=62 (ENCODING), string='utf-8')
2
TokenInfo(type=1 (NAME), string='color')
3
TokenInfo(type=54 (OP), string='=')
4
TokenInfo(type=1 (NAME), string='input')
5
TokenInfo(type=54 (OP), string='(')
6
TokenInfo(type=3 (STRING), string="'Enter your favourite color: '")
7
TokenInfo(type=54 (OP), string=')')
8
TokenInfo(type=4 (NEWLINE), string='')
9
TokenInfo(type=0 (ENDMARKER), string='')
(Note that for the sake of readability, I’ve omitted a few columns from the result above — metadata like starting index, ending index, a copy of the line on which a token occurs, etc.)
#code quality #code review #static analysis #static code analysis #code analysis #static analysis tools #code review tips #static code analyzer #static code analysis tool #static analyzer
