Nowadays, every data scientist should know how to integrate their models within a cloud platform so that they can enhance their work and become more valuable as a data scientist. Unfortunately integration concept is a bit hard when you are beginner but luckily this story is therefore for you if you want to build your first machine learning pipeline on the cloud and more precisely on Amazon Web Services (AWS).
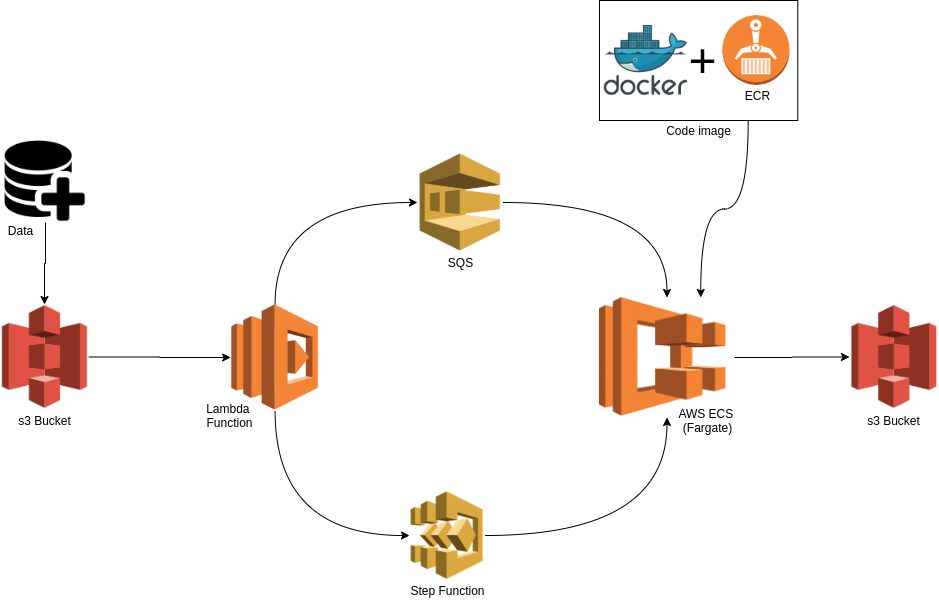
Pipeline architecture
As you can see on the schema, the pipeline’s input is a S3 upload of some data and the pipeline’s output is the data preprocessed written on S3. Everything in the pipeline is automated.
The AWS’s services I will use for this pipeline are the following :
- S3 (Simple Storage Service): Service that provides object storage through a web service interface.
- Lambda : It lets you run code without provisioning or managing servers.
- SQS (Simple Queue Service) : A fully managed message queuing service that enables you to decouple and scale micro services, distributed systems, and serverless applications.
- ECS ( Elastic Container Service) : A fully managed container orchestration service. You can choose to run your ECS clusters using AWS Fargate, which is serverless compute for containers. Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design.
- ECR (Elastic Container Registry) : A fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images.
- Step-function : It lets you coordinate multiple AWS services into serverless workflows so you can build and update apps quickly.
If you already are introduce with some AWS services and just interested in some part of the tutorial, I write this table of contents so you can go directly through the part you are interested in.
- Create a S3 bucket.
- Create a queue SQS.
- Code your lambda function triggered on S3 event to send a message to queue.
- Create your scripts for preprocessing your data.
- Build a Docker Image to run your scripts.
- Push your Docker Image to ECR.
- Create Fargate Task and Cluster.
- Orchestrate your pipeline with Step-function.
This tutorial require to have an AWS account configured on the AWS CLI (or IAM user with permissions) and Docker installed locally on your computer.
Create a S3 bucket
The first step is to create a S3 bucket which will allow you to upload documents like data (json, csv, xlsx, …).
Go to the AWS console, in S3 service and click on “Create Bucket”. It will ask you for a bucket’s name that must be **unique **and for a location for your bucket to be hosted. You location must be the same for every service in a same project. Then you can just click ‘next’ until the creation of your bucket.
Create a queue SQS
Now go to the SQS service on the aws console, create a new queue, give it the name you want and select ‘standard queue’. Then click on ‘Quick-Create queue’.
Code your lambda function triggered on S3 event to send a message to queue
Now that you got a S3 bucket and a SQS queue, the goal is to send a message in queue to SQS service when a file is uploaded in S3. The fargate task will ask SQS queue what it have to do.
Go to Lambda service and create a new function. Indicate the function name and the programming language you want to run. (I will use Python:3.8.0)
Then in the ‘execution role’ section, you have to indicate a role with ‘S3 full access policy’ and ‘step-function full access policy’. If you have not one, go to create one in the IAM console.
It is now time to code. As I said before this tutorial will be exclusively coded with Python but feel free to use the language you want.
With Python the library that is useful for interact with AWS services is Boto3.
The code you put in the lambda function should look like that :
import boto3
s3 = boto3.resource('s3')
sqs = boto3.client('sqs')
queue_url = 'your_queue_url'
def lambda_handler(s3_event, context):
# Get the s3 event
for record in s3_event.get("Records"):
bucket = record.get("s3").get("bucket").get("name")
key = record.get("s3").get("object").get("key")
# Send message to SQS queue
response = sqs.send_message(
QueueUrl=queue_url,
DelaySeconds=1,
MessageAttributes={
'key': {
'DataType': 'String',
'StringValue': key
}
},
MessageBody=(bucket)
)
In this code you get the bucket and the file key from the s3 event and you send these 2 informations to the queue.
Once the function coded, you have to trigger it with the s3 event. In the ‘Designer’ section click on ‘add trigger’, choose S3, and indicate the bucket you want your lambda function to be triggered when something is uploaded on it. The prefix and suffix are useful to filter which files must trigger the function. If you want to trigger only when a csv file is upload in a directory called data, just indicate in suffix .csv and in prefix /data . Then click ‘add’ and your trigger is now ready.
Note that if you write in the same bucket you trigger you must create directories and indicate prefix otherwise the trigger will be infinite
#lambda #aws #s3 #machine-learning #fargate #deep learning