The exploration of data has always fascinated me. The kind of insights and information that can be hidden in raw data is invigorating to discover and communicate. In this post, I chose to explore the bank marketing data from the UCI Machine Learning Repository too uncover insights that suggest whether a client will subscribe for a term deposit or not. So, yes! You guessed right! It is a classification problem. The data were already cleaned, at least to some extent, with no missing values so there wasn’t too much data cleaning required, hence my focus will be on Exploratory Data Analysis (EDA).
I outlined the steps I plan to follow below:
1. EDA
a. Univariate Analysis
b. Bivariate Analysis
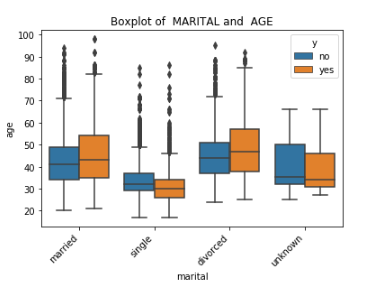
c. Insights Exploration
2. Preprocessing
a. Data Transformation
b. Feature Engineering
3. Modelling
a. Model Development
b. Model Evaluation
c. Model Comparison
Step 1: Exploratory Data Analysis (EDA)
Data was sourced from the UCI Machine Learning repository. The data represents the results of marketing campaigns (phone calls) of a Portuguese banking institution which comprises of 41188 observations (rows) and 21 features (columns), which includes client’s data like age, job, education etc., economic and social attributes like employment variation rate, number of employees etc. The dependent variable (target) is represented with “y” which states the outcome of the marketing campaign whether the respondent subscribed for a deposit “yes” or “no”. A detailed description of the features can be found here
Let begin with the exploration — first load all libraries that will be used
## Ignore warnings
import warnings
warnings.filterwarnings('ignore')
## Handle table-like data and matrices
import numpy as np
import pandas as pd
## Modelling Algorithms
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.neural_network import MLPClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
## Modelling Helpers
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
## Visualisation
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
## read in the data
df = pd.read_csv('data/bank-additional-full.csv', sep=';')
df.head()
Let’s look at the description of the data using the describe method from pandas library.
#data-exploration #machine-learning #data-preprocessing #predictive-analytics #modeling