This blog series will cover open source components that can be used on top of existing Kubernetes primitives to help scale Kubernetes clusters, as well as applications. We will explore:
Here is a breakdown of the blog posts in this series:
- Part 1 (this post) will cover basic KEDA concepts
- Part 2 will showcase KEDA auto-scaling in action with a practical example
- Part 3 will introduce Virtual Kubelet
- Part 4 will conclude the series with another example to demonstrate how KEDA and Virtual Kubelet can be combined to deliver scalability
In this post, you will get an overview of KEDA, its architecture, and how it works behind the scenes. This will serve as a good foundation for you to dive into the next post, where you will explore KEDA hands-on with a practical example

KEDA (Kubernetes-based Event-driven Autoscaling) is an open source component developed by Microsoft and Red Hat to allow any Kubernetes workload to benefit from the event-driven architecture model. It is an official CNCF project and currently a part of the CNCF Sandbox. KEDA works by horizontally scaling a Kubernetes Deployment or a Job. It is built on top of the Kubernetes Horizontal Pod Autoscaler and allows the user to leverage External Metrics in Kubernetes to define autoscaling criteria based on information from any event source, such as a Kafka topic lag, length of an Azure Queue, or metrics obtained from a Prometheus query.
You can choose from a list of pre-defined triggers (also known as Scalers), which act as a source of events and metrics for autoscaling a Deployment (or a Job). These can be thought of as adapters that contain the necessary logic to connect to the external source (e.g., Kafka, Redis, Azure Queue) and fetch the required metrics to drive autoscaling operations. KEDA uses the Kubernetes Operator model, which defines Custom Resource Definitions, such as ScaledObject, which you can use to configure autoscaling properties.
Pluggability is built into KEDA and it can be extended to support new triggers/scalers
At a high level, KEDA does two things to drive the autoscaling process:
- Provides a component to activate and deactivate a Deployment to scale to and from zero when there are no events
- Provides a Kubernetes Metrics Server to expose event data (e.g., queue length, topic lag)
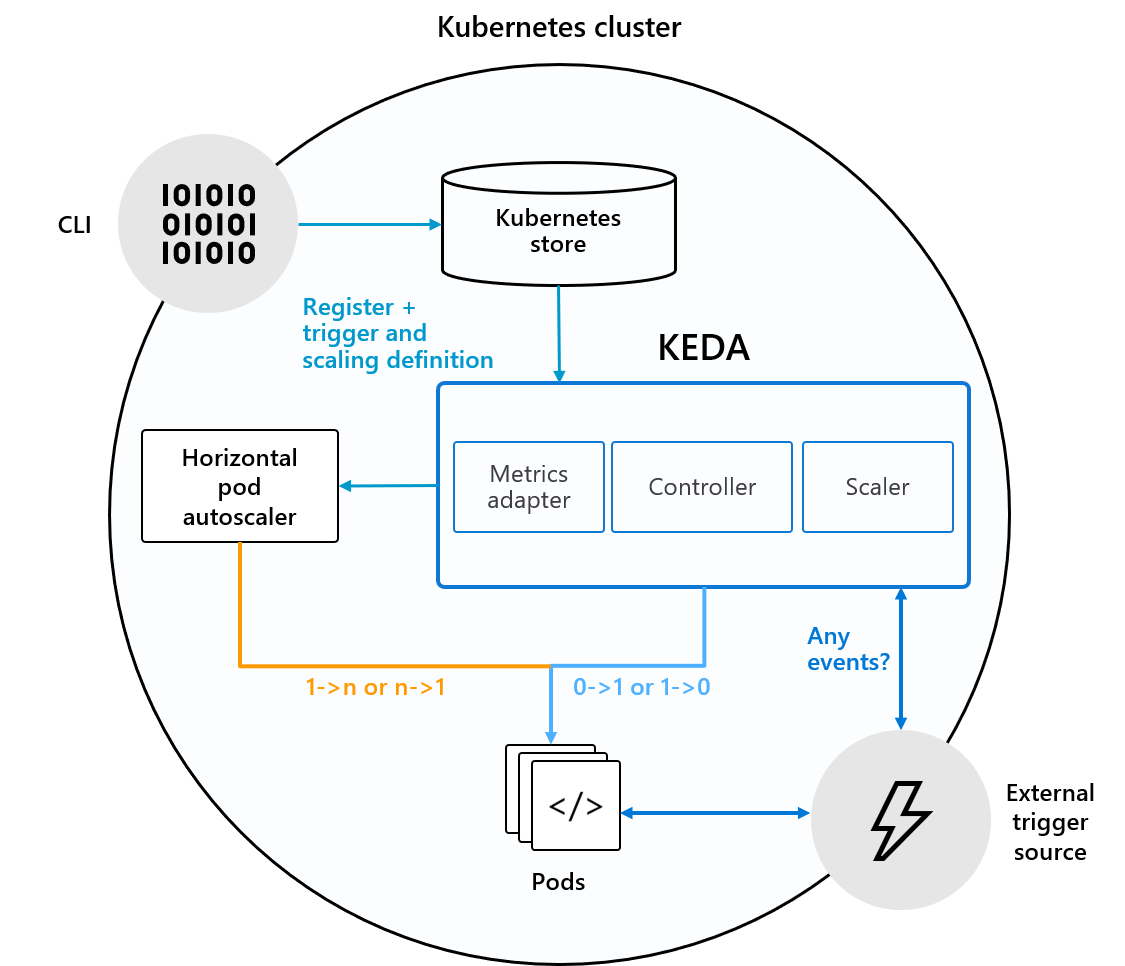
KEDA uses three components to fulfill its tasks:
Scaler: Connects to an external component (e.g., Kafka) and fetches metrics (e.g., topic lag)Operator(Agent): Responsible for “activating” a Deployment and creating a Horizontal Pod Autoscaler objectMetrics Adapter: Presents metrics from external sources to the Horizontal Pod Autoscaler
#architecture #kubernetes #open-source #docker #cloud