Convolutional Neural Networks (CNNs) have achieved significant success in many computer vision tasks. In recent years, they have reduced DenseNet model parameters and feature map channel dimensions. In terms of the inherent redundancy of the number , its efficiency continues to improve. However, the feature maps generated by CNNs also have a lot of redundancy in the spatial dimension. Each location stores its own feature descriptor independently, ignoring the common information between adjacent locations that can be stored and processed together.
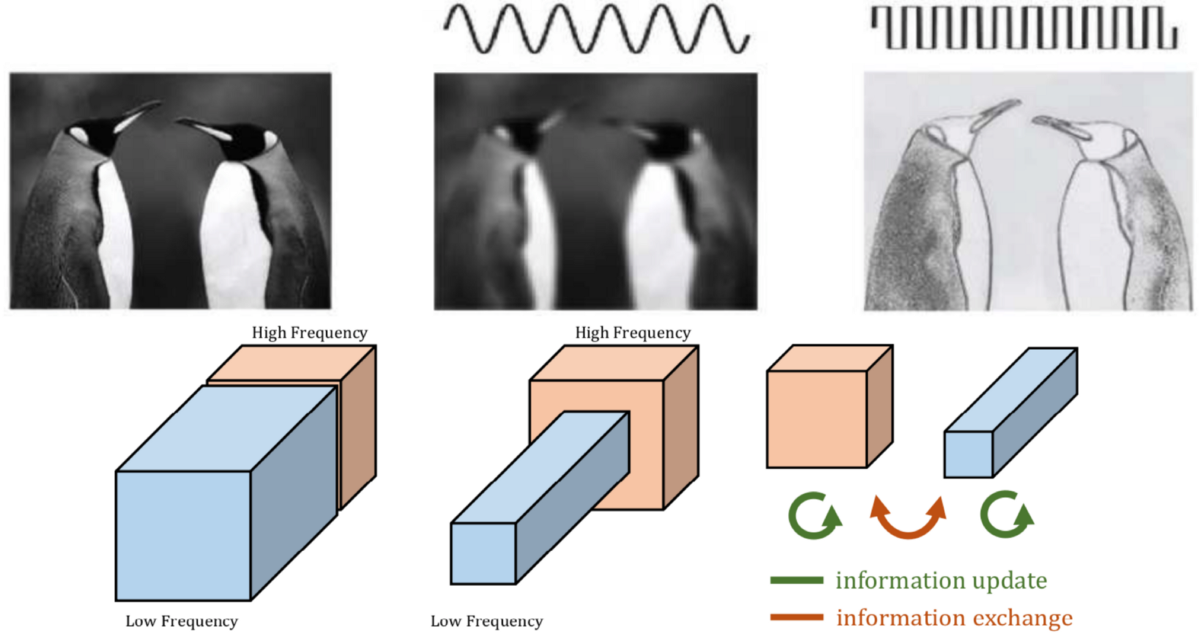
Natural images can be decomposed into low spatial frequency components that describe smoothly changing structures and high spatial frequency components that describe fast-changing fine details .
[1] believe that the output feature map of the convolutional layer can also be decomposed into features of different spatial frequencies, and propose a new multi-frequency feature representation method, which stores high-frequency and low-frequency feature maps into different group.
Therefore, through information sharing between adjacent locations, the spatial resolution of the low-frequency group can be safely reduced, and the spatial redundancy is reduced.
Jobs in AI
Octave Feature Representation
In order to reduce this spatial redundancy, [1] introduced the octave feature representation, which explicitly decomposes the feature map tensor into groups corresponding to low and high frequencies.
#cnn #convolutional-network #ai #image-processing #machine-learning
