We should define path to the mallet binary to pass in LdaMallet wrapper:
mallet_path = ‘/content/mallet-2.0.8/bin/mallet’
There is just one thing left to build our model. We should specify the number of topics in advance. Although there isn’t an exact method to decide the number of topics, in the last section we will compare models that have different number of topics based on their coherence scores.
For now, build the model for 10 topics (this may take some time based on your corpus):
ldamallet = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=10, id2word=id2word)
Let’s display the 10 topics formed by the model. For each topic, we will print (use pretty print for a better view) 10 terms and their relative weights next to it in descending order.
from pprint import pprint
# display topics
pprint(ldamallet.show_topics(formatted=False))

Note that, the model returns only clustered terms not the labels for those clusters. We are required to label topics.
We can calculate the coherence score of the model to compare it with others.
# Compute Coherence Score
coherence_model_ldamallet = CoherenceModel(model=ldamallet, texts=data_ready, dictionary=id2word, coherence='c_v')
coherence_ldamallet = coherence_model_ldamallet.get_coherence()
print('Coherence Score: ', coherence_ldamallet)
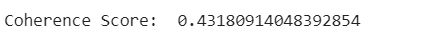
It’s a good practice to pickle our model for later use.
import pickle
pickle.dump(ldamallet, open("drive/My Drive/ldamallet.pkl", "wb"))
You can load the pickle file as below:
ldamallet = pickle.load(open("drive/My Drive/ldamallet.pkl", "rb"))
We can get the topic modeling results (distribution of topics for each document) if we pass in the corpus to the model. You can also pass in a specific document; for example, ldamallet[corpus[0]] returns topic distributions for the first document. For the whole documents, we write:
tm_results = ldamallet[corpus]
We can get the most dominant topic of each document as below:
corpus_topics = [sorted(topics, key=lambda record: -record[1])[0] for topics in tm_results]
To get most probable words for the given topicid, we can use show_topic() method. It returns sequence of probable words, as a list of (word, word_probability) for specific topic. You can get top 20 significant terms and their probabilities for each topic as below:
topics = [[(term, round(wt, 3)) for term, wt in ldamallet.show_topic(n, topn=20)] for n in range(0, ldamallet.num_topics)]
#mallet #lda #pandas #topic-modeling #python
