🔒Limitations of Bagging Models
In Case of Random Forest each individual tree is independent and hence it does not focus on the errors or predictions that are made by the previous tree which can actually be helpful to the upcoming tree for focusing on certain aspects of the data in-order to improve the overall performance.
For example, if there is a particular data point that is incorrectly predicted by the first tree then there is a good chance that second tree might also predict incorrectly and the same is valid for all the other trees in random forest. So, this means that the trees have no relation with each other and are working parallelly on different subsets of data. Since each of these individual trees do not learn from other tress.
Now is there any way that we can take the learning from previous tree in-order to improve the overall performance. Well that is not possible in case of random forest because the trees in random forest are built parallelly. So, we look at another technique Boosting. In case of boosting the models are dependent on each other and each of the upcoming the model tries to reduce the overall error by working on the incorrect predictions of the previous model. Hence these models are built sequentially.
💥Boosting:
Definition: The term ‘Boosting’ refers to a family of algorithms which converts weak learner to strong learners.
Before we go further, here’s another question for you: If a data point is incorrectly predicted by the first model, and then the next (probably all models), will combining the predictions provide better results? Such situations are taken care of by boosting.
Boosting is a sequential process, where each subsequent model attempts to correct the errors of the previous model. The succeeding models are dependent on the previous model. Let’s understand the way boosting works in the below steps.
1.A subset is created from the original data set.
2.Initially, all data points are given equal weights.
3.A base model is created on this subset.
4.This model is used to make predictions on the whole data set.
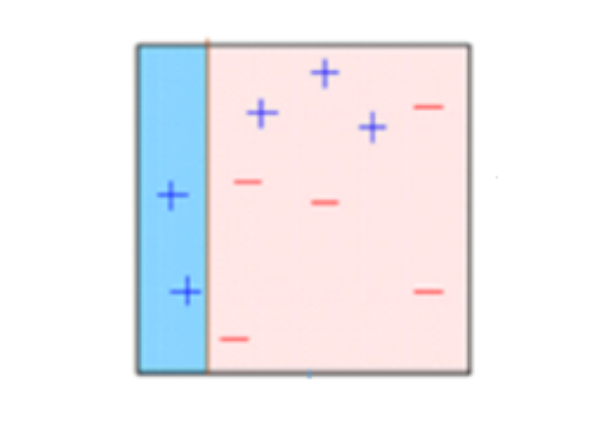
5.Errors are calculated using the actual values and predicted values.
6.The observations which are incorrectly predicted, are given higher weights.
(Here, the three mis-classified blue-plus points will be given higher weights)
7.Another model is created and predictions are made on the data set.
(This model tries to correct the errors from the previous model).
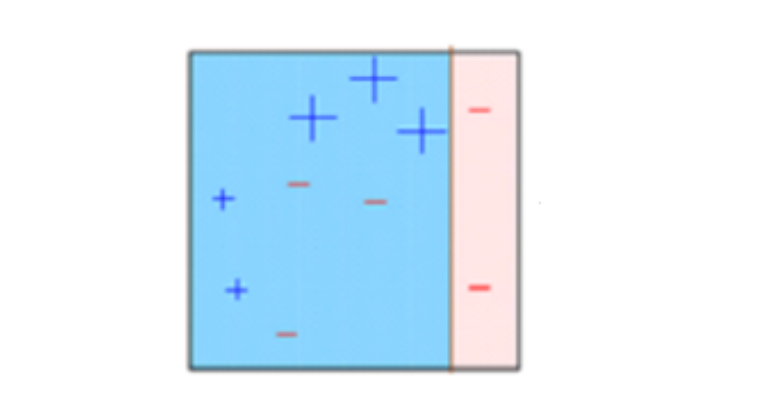
8.Similarly, multiple models are created, each correcting the errors of the previous model.
9.The final model (strong learner) is the weighted mean of all the models (weak learners).
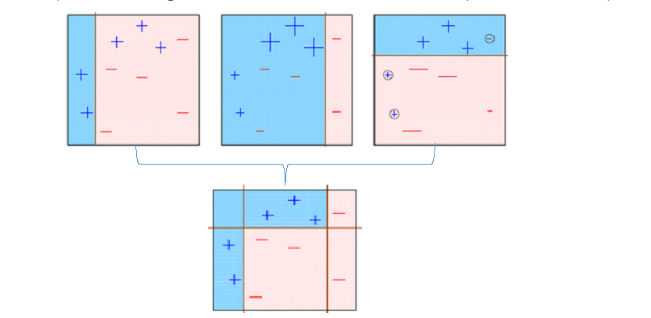
10.Thus, the boosting algorithm combines a number of weak learners to form a strong learner. The individual models would not perform well on the entire data set, but they work well for some part of the data set. Thus, each model actually boosts the performance of the ensemble.

🚩 Boosting algorithms:
Ada Boost
GBM
XGBM
Light GBM
CatBoost
💥 AdaBoost:
Adaptive boosting or AdaBoost is one of the simplest boosting algorithms. Usually, decision trees are used for modelling. Multiple sequential models are created, each correcting the errors from the last model. AdaBoost assigns higher weights to the observations which are incorrectly predicted and the subsequent model works to predict these values correctly.
💢Three Concepts behind AdaBoost:
#data-visualization #data-science #deep-learning #data analysis
