Meet Mason. He’s an average American 40-year-old: 5 foot 10 inches tall and earning $47,000 per year before tax.
How often would you expect to meet someone who earns 10x as much as Mason?
And now, how often would you expect to meet someone who is 10x as tall as Mason?
Your answers to the two questions above are different, because the distribution of data is different. In some cases, 10x above average is common. While in others, it’s not common at all.
So what are normal distributions?
Today, we’re interested in normal distributions. They are represented by a bell curve shape, with a peak in the middle that tapers towards each edge. A lot of things follow this distribution, like your height, weight, and even IQ.
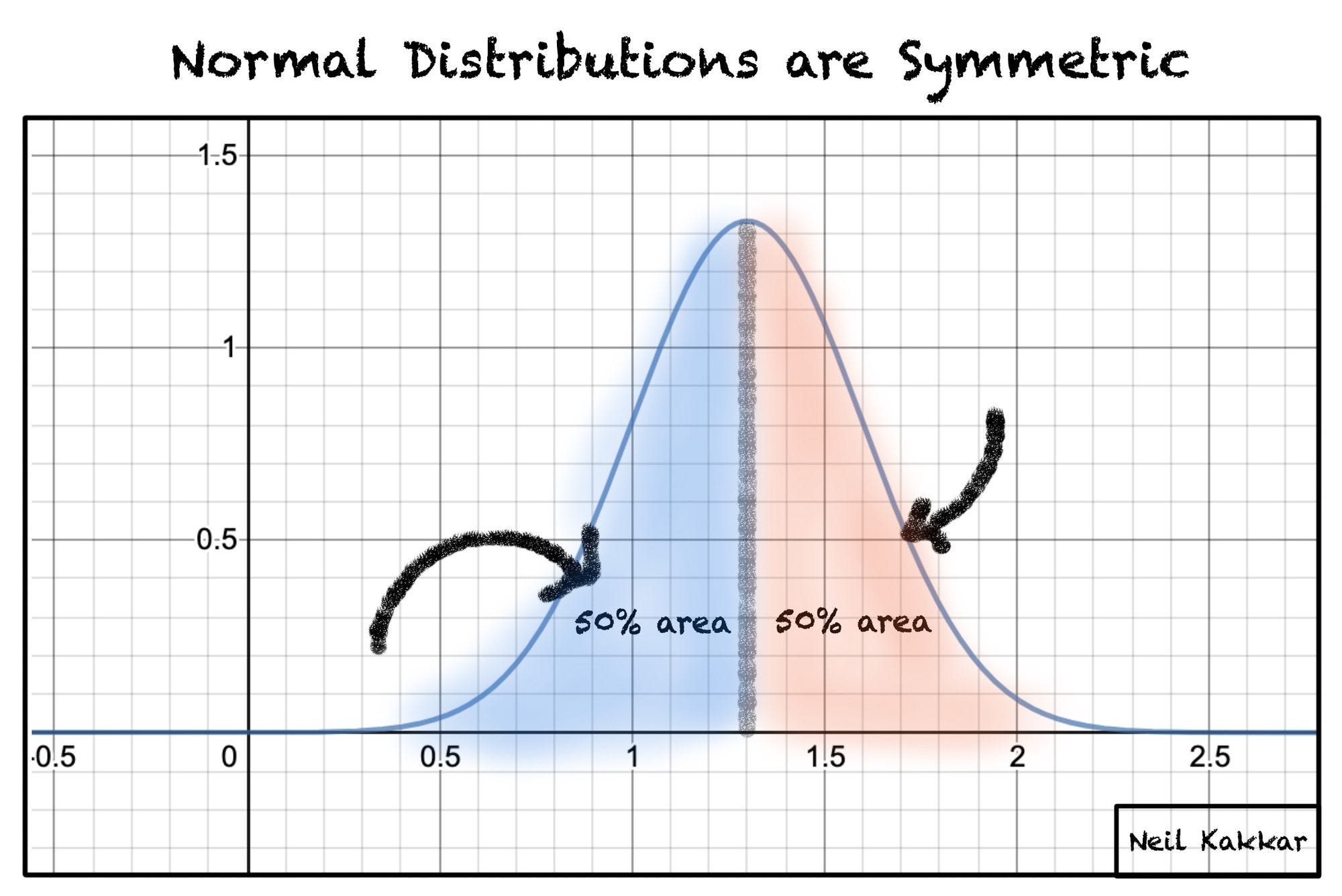
This distribution is exciting because it’s symmetric — which makes it easy to work with. You can reduce lots of complicated mathematics down to a few rules of thumb, because you don’t need to worry about weird edge cases.
For example, the peak always divides the distribution in half. There’s equal mass before and after the peak.
Another important property is that we don’t need a lot of information to describe a normal distribution.
Indeed, we only need two things:
- The mean. Most people just call this “the average.” It’s what you get if you add up the value of all your observations, then divide that number by the number of observations. For example, the average of these three numbers:
1, 2, 3 = (1 + 2 + 3) / 3 = 2 - The standard deviation. This tells you how rare an observation would be. Most observations fall within one standard deviation of the mean. Fewer observations are two standard deviations from the mean. And even fewer are three standard deviations away (or further).
Together, the mean and the standard deviation make up everything you need to know about a distribution.
#critical-thinking #science #statistics #math #data-science