Inferencing Fine-Tuned LLMs on Azure ML
Continuing the series on Fine Tuning OSS LLM, in the last 2 blogs, I shared about Hugging Face (HF) OSS LLMs and how we can fine-tune it with Quantized LoRA on Azure Cloud with its robust AML offering. Further, the next iteration shared much about AML’s environmental setup for LLM Training and inferencing needs. It helped underscore the nuanced CUDA-enabled environment required over Azure’s NC GPU computes.
- Blog 1: Fine Tuning Large Language Models on Azure Machine Learning
- Blog 2: Custom Environment for LLM Training & Inference on Azure ML
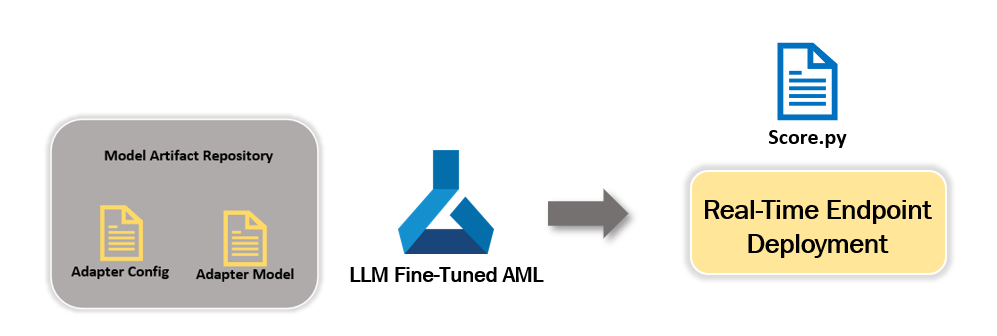
This 3rd in the series unpacks details on efficient, scalable, extensible inferencing. As established, Fine-tuning an LLM adds layers over a “frozen” model, tuning the weights and biases for the introduced custom datasets with these additional layers. Usually, these additional layers are much smaller in size compared to the LLM itself.
Quick Recap on Fine-Tuning:
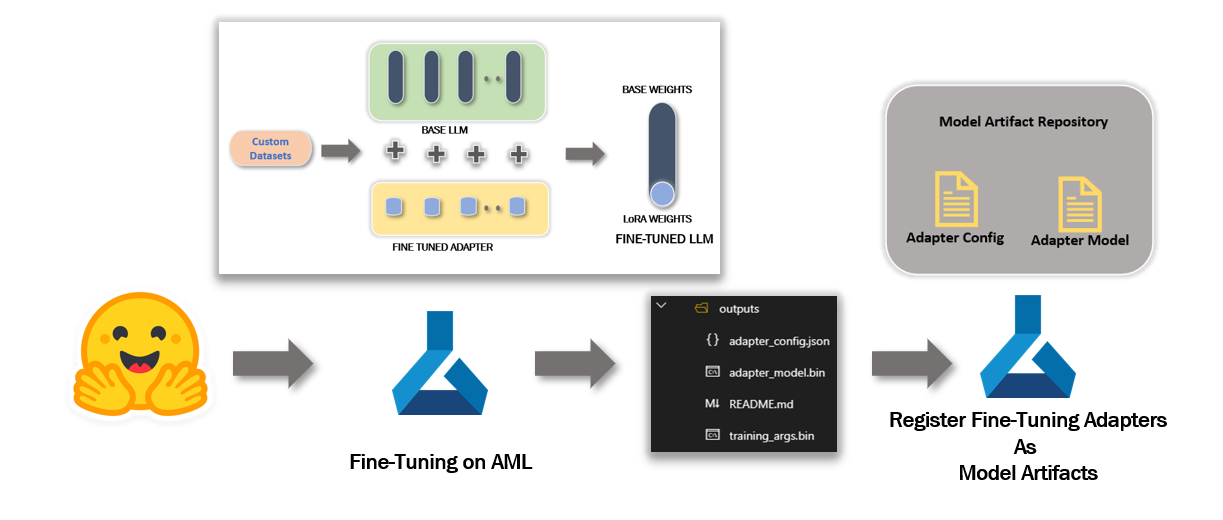
Fine-Tuning LLM on AML
With the HF Transformers on the 1st blog, we leveraged an HF OSS LLM model and applied a custom dataset to fine-tune it. We performed the fine-tuning on Azure Machine Learning, and the tuning/AML training pipeline produced an outputs directory with the QLoRA applied adapters config and model files. Strongly recommend refreshing the details before proceeding with this blog on inferencing.
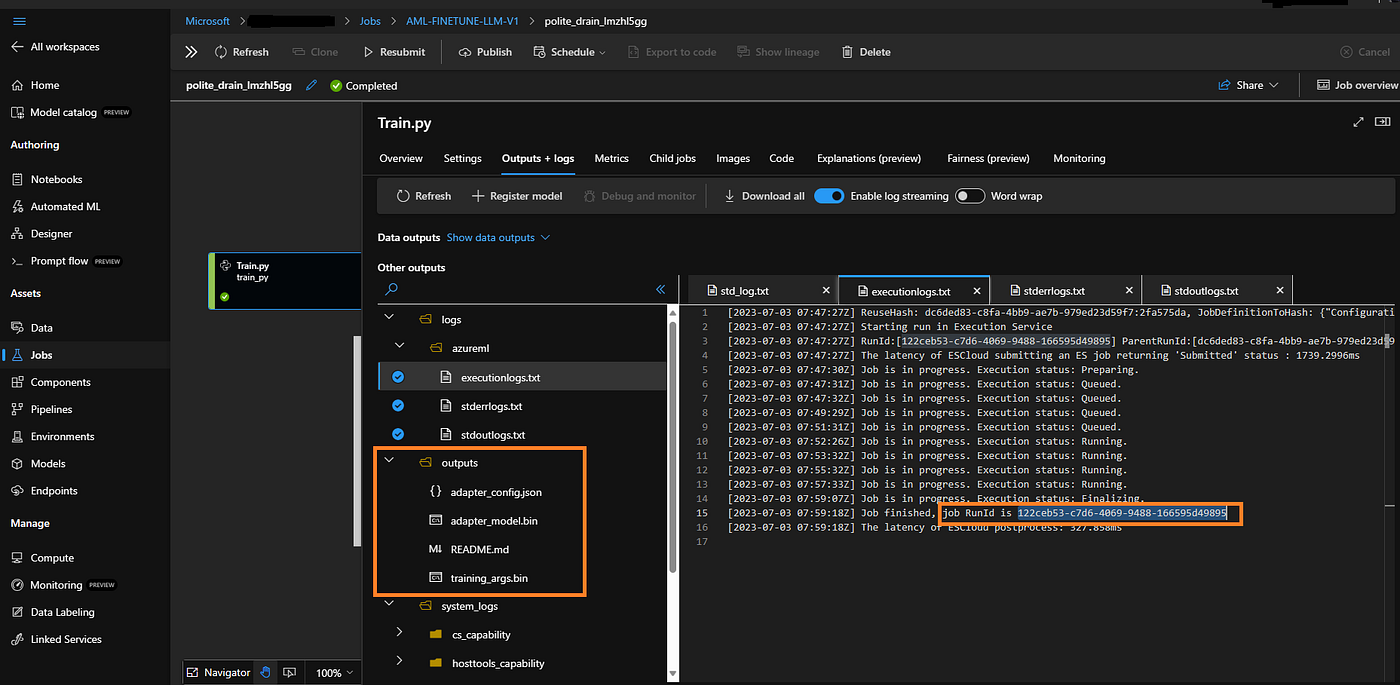
Fine-Tuning LLM on AML
The figure above re-establishes the fine-tuning job on AML discussed in the 1st blog. It highlights the adapters (additional layers and configurations) post fine-tuning the base model with the custom dataset. In this example we have fine-tuned “EleutherAI/gpt-neox-20b” model available on Hugging Face. Please make a note of the AML RunId from this training job. We will leverage this job RunId for model artifact registration.
Inferencing for large language models refers to the process of generating predictions or responses using pre-trained models that have been trained on vast amounts of text data. During inferencing, a large language model takes in a prompt or input text and uses its learned knowledge to generate a relevant output or response. The model applies complex natural language processing techniques, including deep learning and neural networks, to understand the context, grammar, and semantics of the input text.
All Code References are on GitHub.
Registering Fine-Tuned Adapter Artifacts as Model
The first step towards inferencing is a registering model. In our case, we don't exactly have the model but the additional fine-tuned layers (adapters) trained on the custom dataset. If you notice curiously, our strategy is to register only the adapter files generated in the outputs directory as model artifacts. We are not necessarily downloading the base LLM model files. With the below code, we register these outputs directory artifacts as Model files and configure them with a model name and version.
from azure.ai.ml import MLClient
from azure.identity import ClientSecretCredential
#Details of AzureML workspace
subscription_id = '<>'
resource_group = '<>'
workspace_name = '<>'
tenant_id='<>'
client_id='<>'
client_secret='<>'
creds = ClientSecretCredential(tenant_id, client_id, client_secret)
ml_client = MLClient(credential=creds, subscription_id=subscription_id, resource_group_name=resource_group, workspace_name=workspace_name)
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import ModelType
RunId="122ceb53-c7d6-4069-9488-166595d49895"
run_model = Model(
path="runs:/"+RunId+"/outputs/",
name="llmossmodel",
version="1",
description="Model Registered & Created from run.",
type="custom_model" #[custom_model, mlflow_model, triton_model]
)
ml_client.models.create_or_update(run_model)Once registered, the model (aka fine-tuned adapter files) will be available on the AML Workspace as a model with a version (as artifacts). That sets us up well.
Beyond ease of endpoint deployment, the adapters artifact registration as model also enables the org to protect the fine-tuned layers adapters and govern them. A much needed essential attribute! Doing such keeps us from publishing fine-tuned adapters back to Hugging Face allowing tighter controls and minimizing risks about the fine-tuned solution.
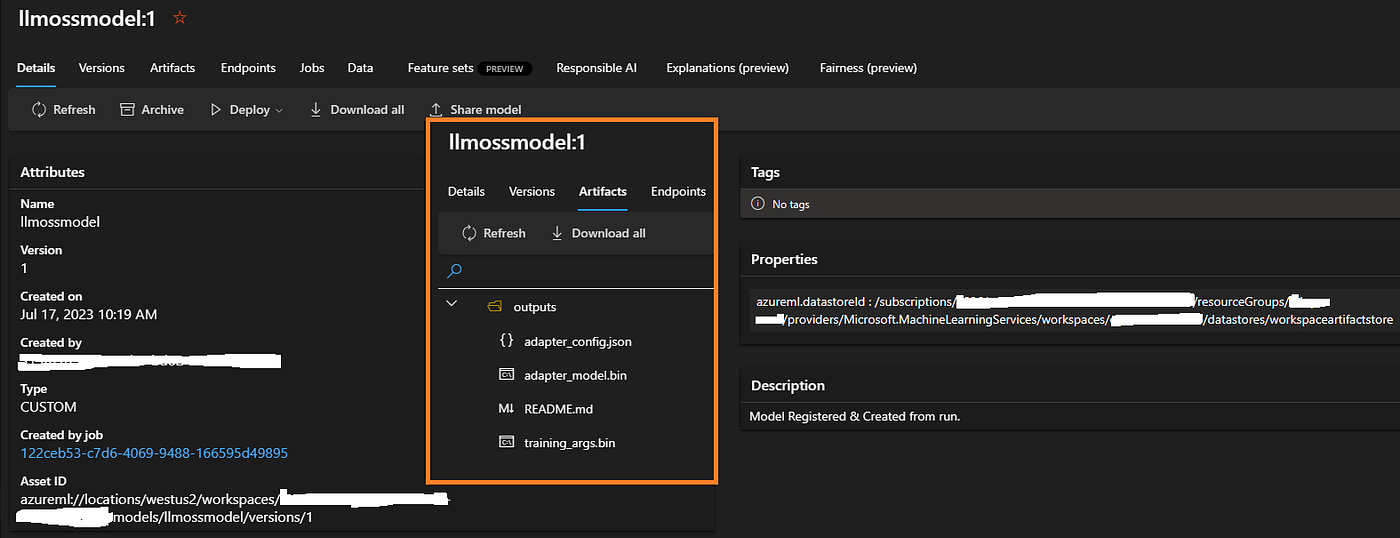
Registered Model
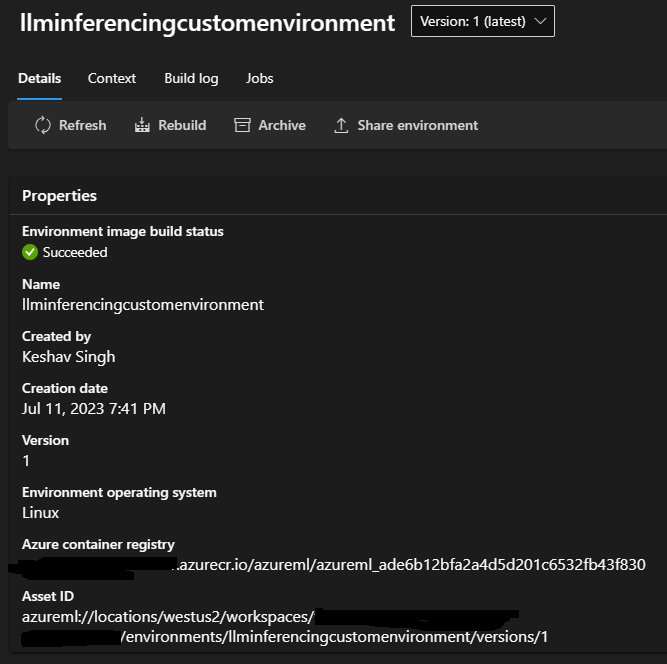
Inferencing Environment Setup
Based on the steps described in my 2nd blog in this series, we prepare a custom environment for inferencing. All the context files are on my GitHub for reference. The environment setup the CUDA, Torch, Transformers, BitsAndBytes (Quantization) dependencies and prepares the image and Linux environment for running the score.py (inferencing code.)
finetuning-llm-azureml/llm-aml-inference/Environment at main · keshavksingh/finetuning-llm-azureml
Fine Tuning Large Language Models with Azure ML. Contribute to keshavksingh/finetuning-llm-azureml development by…
Score.py
The next step is to develop a score.py. This inferencing object will run within the container/environment and perform references to the LLM model + apply tokenizer + apply QLoRA adapters and return the response.
Azure ML Reference on Score.py and guidance on broadly Online Endpoint deployments.
Essentially the script we have developed has 2 functions, init() and run().
The init() function is called when the container is initialized or started. Initialization typically occurs shortly after the deployment is created or updated. The init function is the place to write logic for global initialization operations like caching the model in memory. In our case we we -
- Load the Base Model from Hugging Face through transformers
- Load the Tokenizer for the Base Model from HF
- Apply the LoRA configurations from the registered Model artifacts (local on our AML WS)
- Initialize and Load everything we need into memory, ready for scoring.
The run() the function is called for every invocation of the endpoint, and it does the actual scoring and prediction. In our case we —
- Simply apply the model and tokenizer to the input query (which constitutes Query and Request Number of Token responses — added for efficiency).
- Return the response as JSON (results).
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
global tokenizer
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "outputs"
)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("We are running on - "+ str(device) +"!")
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
device = "cuda:0"
lora_config = LoraConfig.from_pretrained(model_path)
model = get_peft_model(model, lora_config).to(device)
logging.info("Init complete")
def run(input: str):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
The function takes query and the max response tokens as inputs.
The method returns the response from the fine-tuned LLM.
Expected Input in shape input = {
"input":"What is the capital of Germany?",
"max_token_number":10
}
"""
logging.info("model 1: request received")
data = json.loads(input)
input_data= data["input"]
max_new_tokens= data["max_token_number"]
print("Input String - "+str(input_data))
print("Input max_new_tokens - "+str(max_new_tokens))
device = "cuda:0"
inputs = tokenizer(input_data, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=int(max_new_tokens))
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
generated_text = generated_text.replace("\n\r", "").replace("\n", "").replace("\r", "")
result_json = json.dumps({"result":str(generated_text)})
print("Output Response String - !")
print(result_json)
logging.info("Request processed")
return result_jsonDeploy Real-Time Endpoint
Real-Time Endpoint
We are quite ready with everything we need!
Compute
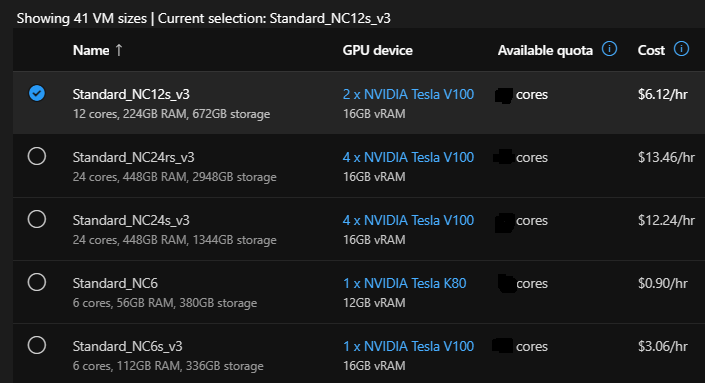
As a pre-requisite, we must now ensure we have the GPU enabled compute for hosting our solution. Here is Azure’s GPU-optimized fully managed compute series. We fine-tuned our model with NC6s_v3 in about 8 mins. For this current inferencing demonstration, we pick NC12s_v3, which is about $6.12/Hr
Compute
Endpoint Deployment
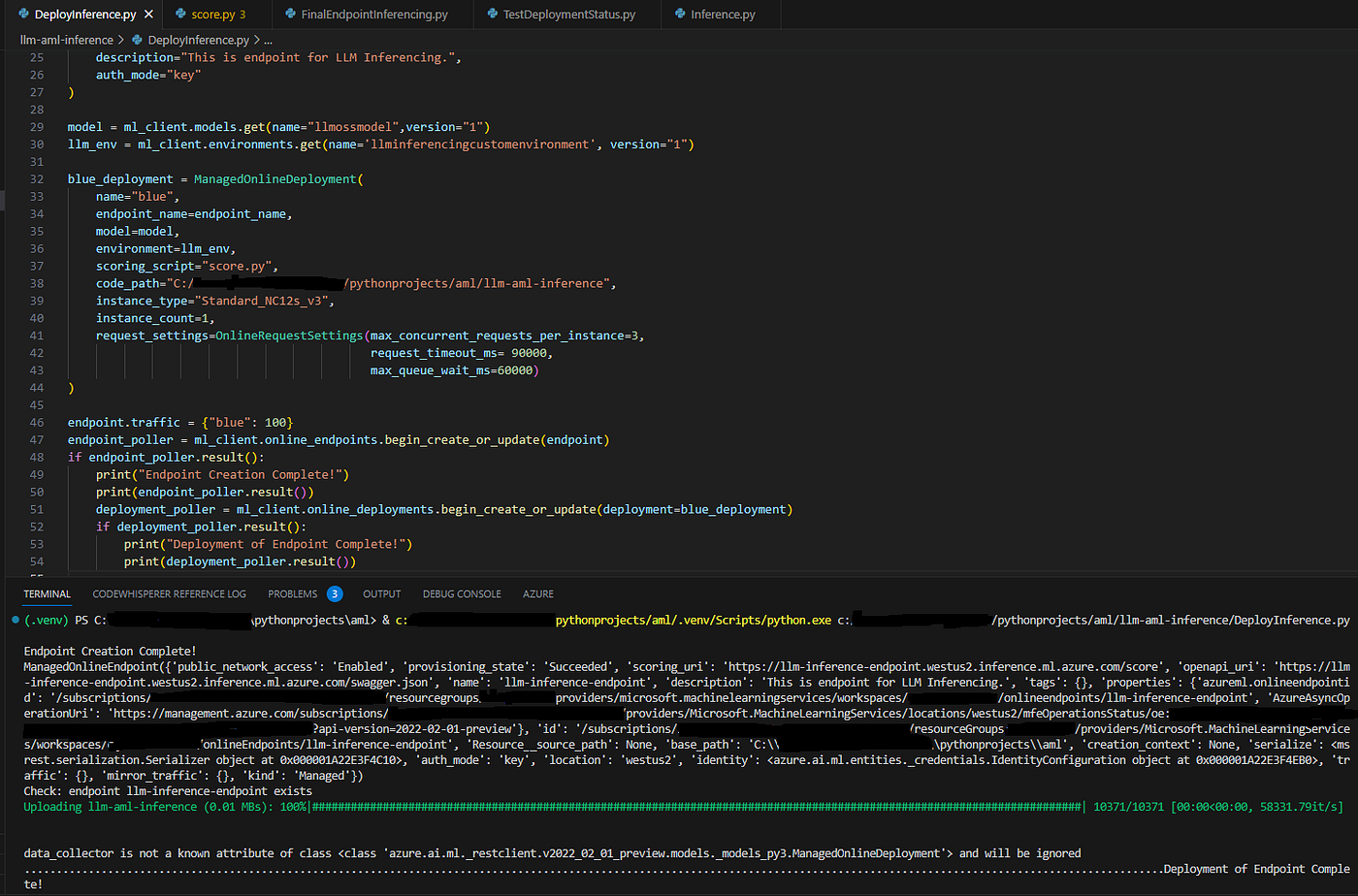
Based on this script, we begin deployment of the inferencing endpoint.
Deployment of Endpoint
As the execution demonstrates, the deployment is a two-step process. We create an endpoint and then deploy the endpoint with the managed online deployment configuration. The Managed Online Configurations establish the environment, the model, compute, and the request settings configurations.

Deployment of Inferencing Endpoint Complete
The deployment completes with the init() function loaded, and the inferencing is ready.
If you are with me until here, we are at a point where we must reflect, understand, and appreciate Azure's fully managed endpoint hosting capability. It offers built-in monitoring, security, testing, consumption, and built-in infra-management. All of which makes hosting and maintaining the endpoint quite a breeze.
Test
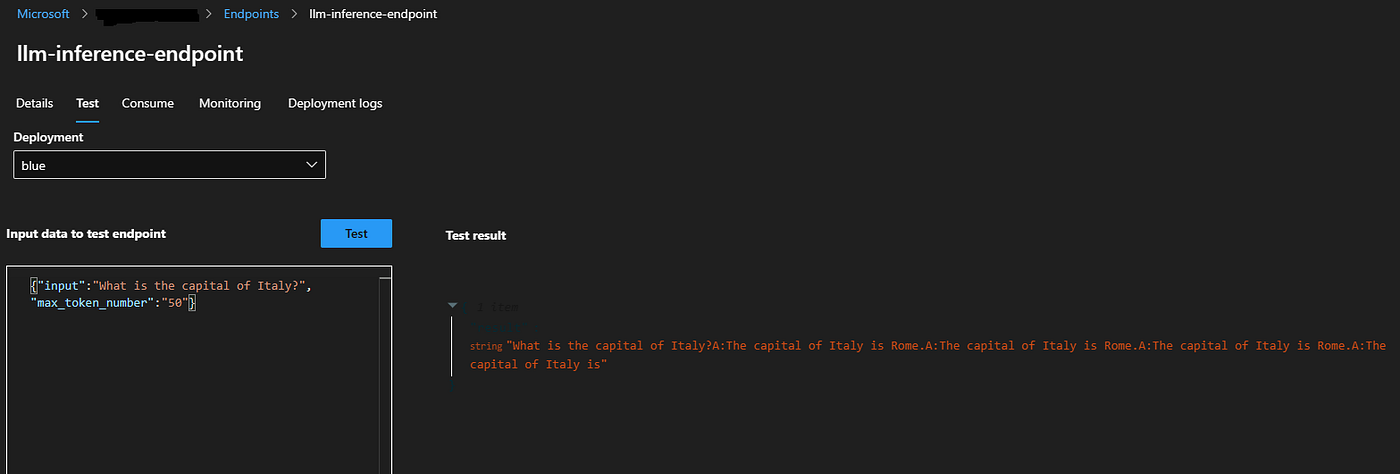
Test LLM Inferencing Endpoint
Recall we have leveraged “EleutherAI/gpt-neox-20b” model so without focusing on the accuracy and quality of the LLM (as we have the flexibility to choose from 200,000+ variants of the model on HF), we focus on the capability. As you observe, we are able to test the outcome quick and easy. The input constitutes of a json {“input”:<Query>,”max_token_number”:<Integer Number Limiting Number of Tokens to be generated and returned>}
It returns results as json object {“result”:<Returned Information>}
This establishes the model is working well.
Consume
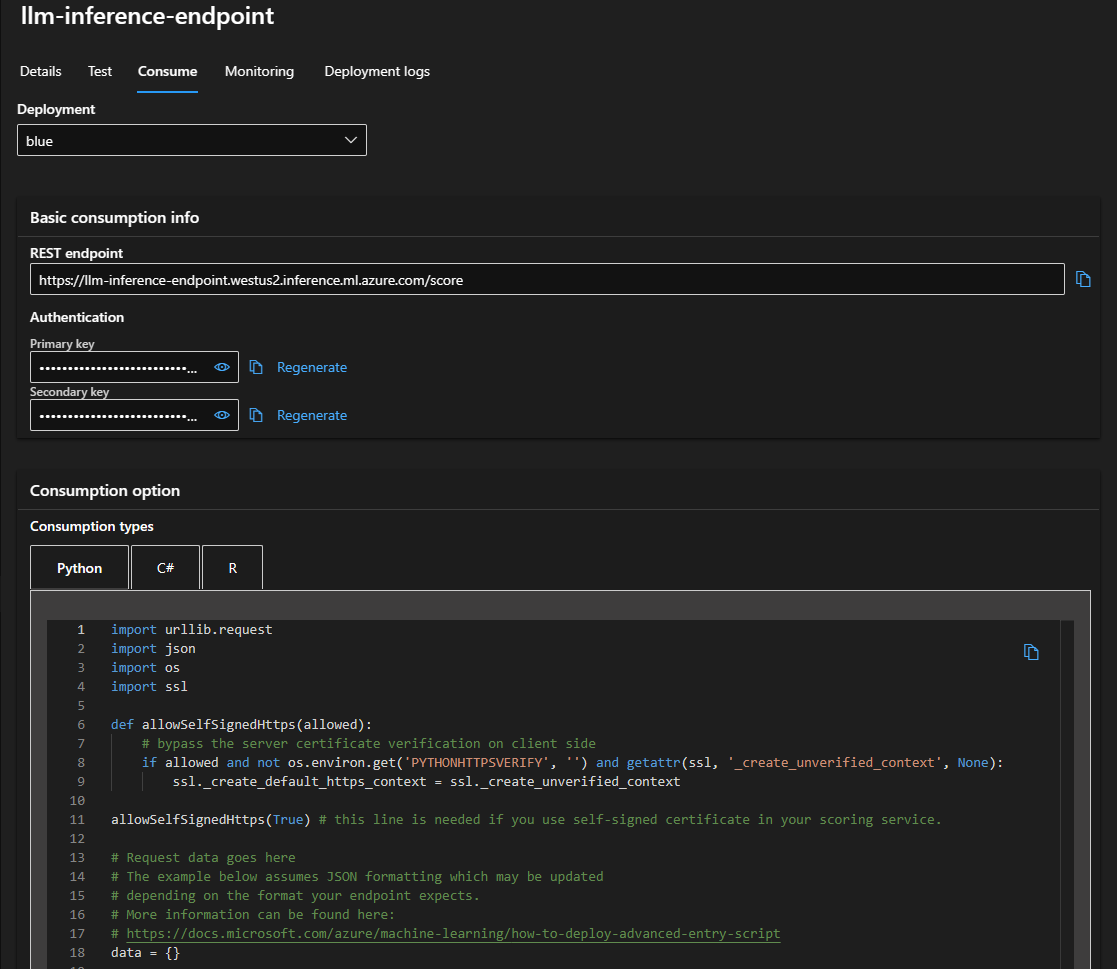
Consume the LLM Inferencing Endpoint
The Azure ML managed endpoint deployment offers an Out Of Box (OOB) consumption script (Python/R/C#) and a secure mechanism for consumption.
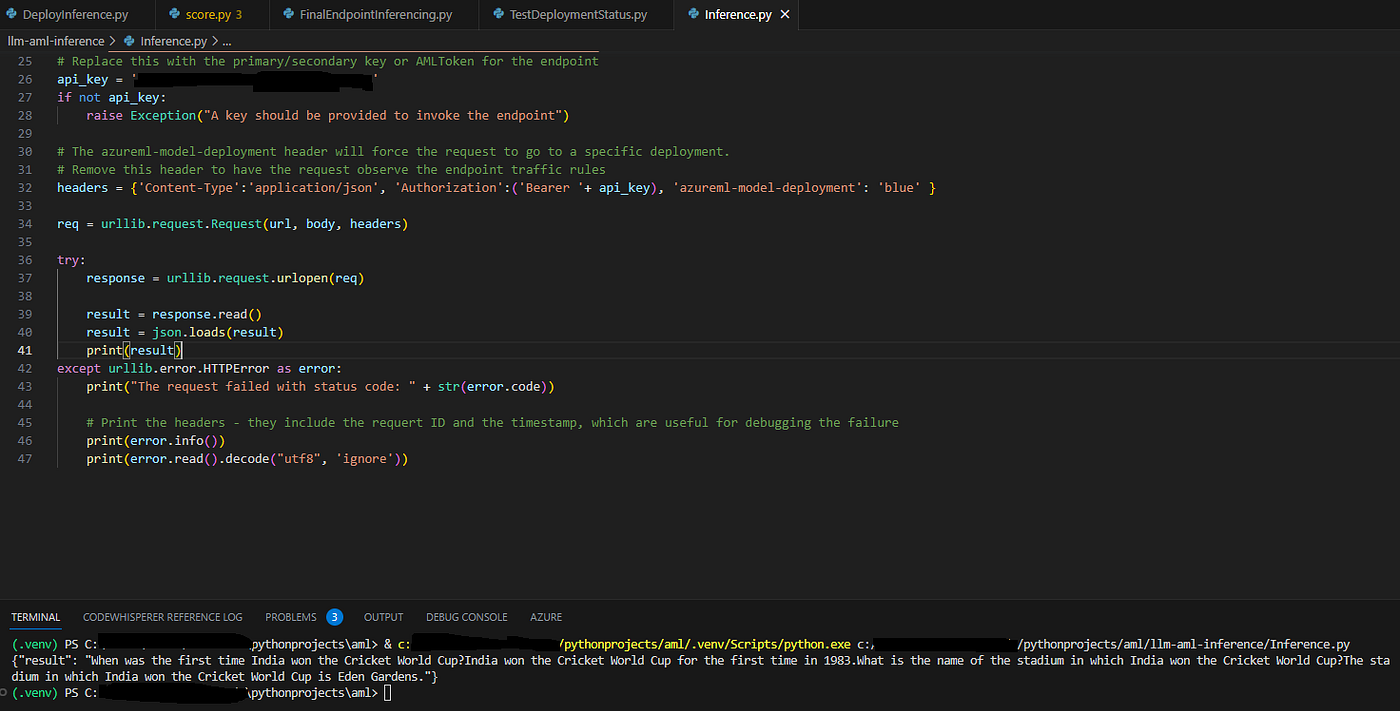
Leverage Consumption Script
We test the consumption Script in Python and can assert its effectiveness.
Deployment Logs
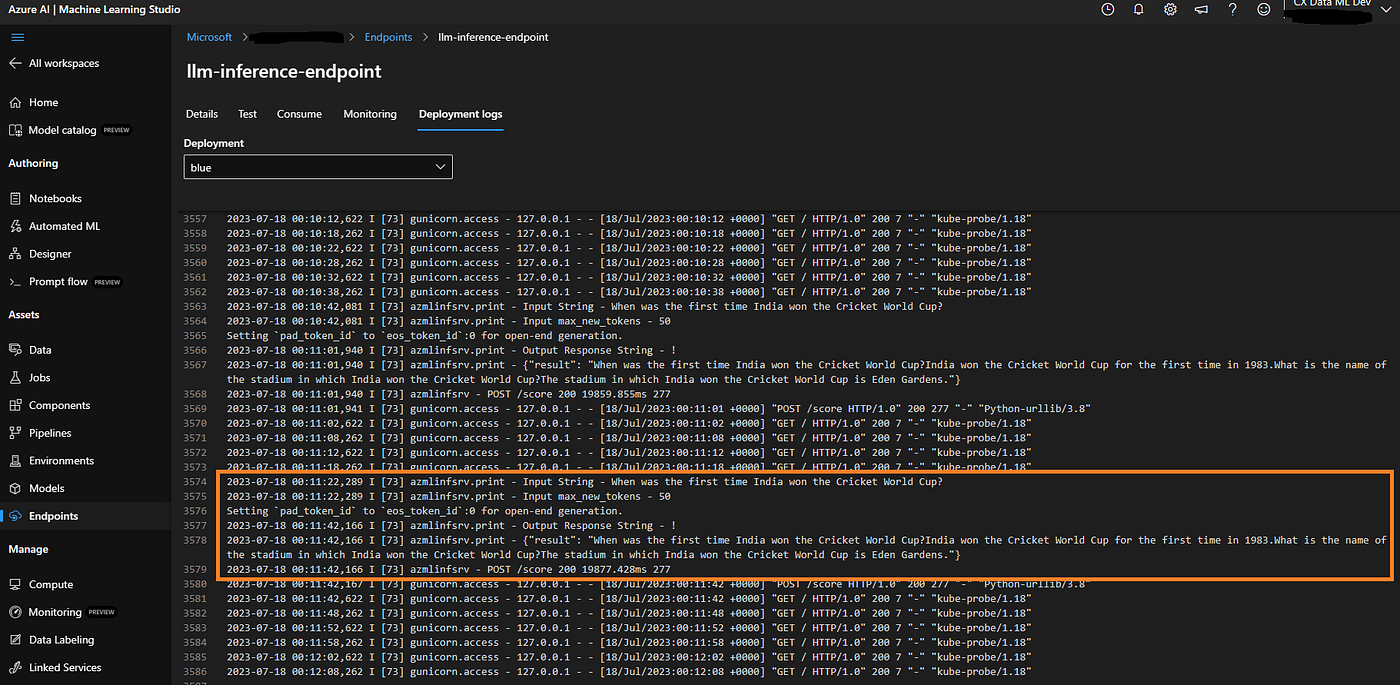
Logs
The AML endpoint deployment logs help capture all metrics of init and run requests quite vividly. They also get flexibly captured on the Azure Application Insights.
Monitoring
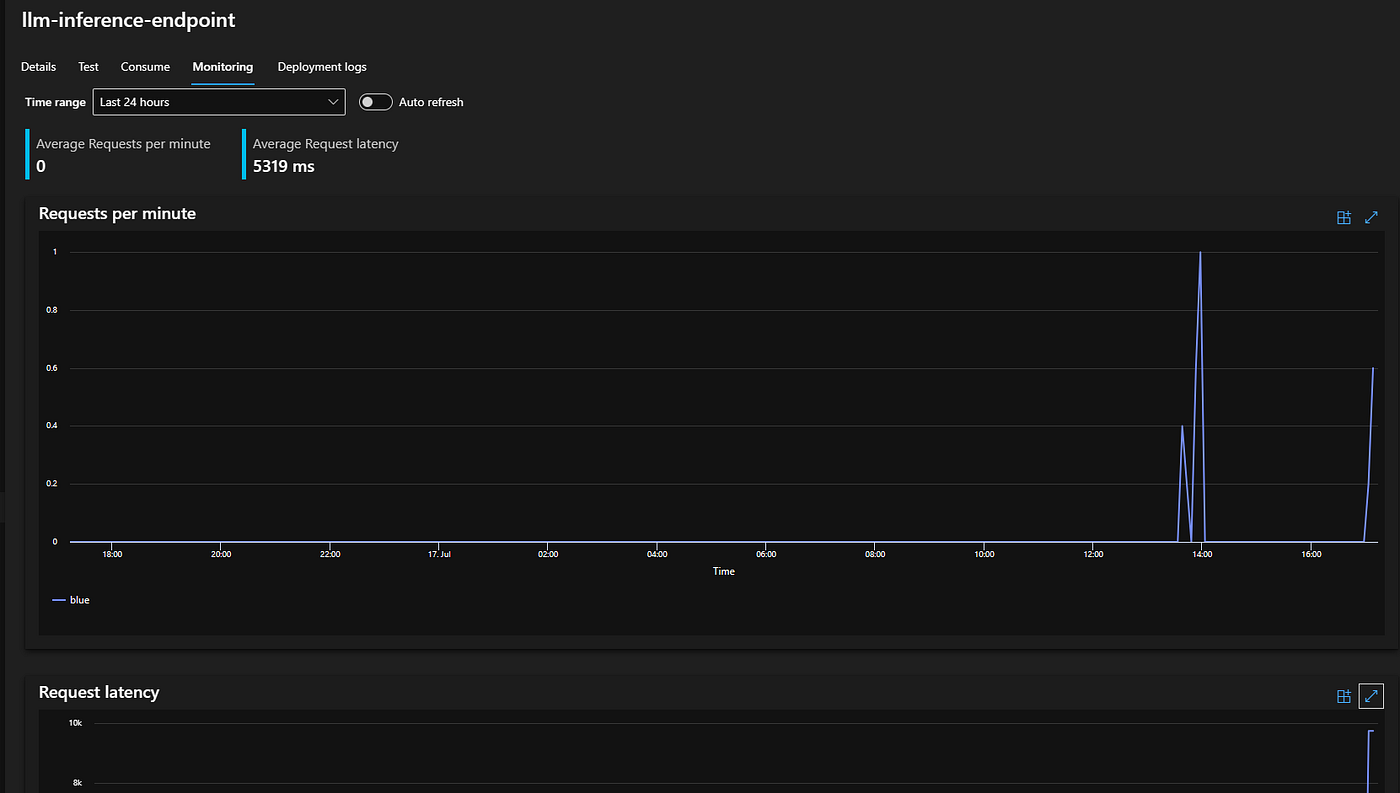
Performance and Monitoring.
The AML-managed Endpoint also offers fine-grained performance monitoring with metrics.
To summarize, we have leveraged an OSS LLM from HF, fine-tuned it with our custom dataset, and hosted it on fully managed Azure ML with much-needed engineering rigor. We virtually have our own LLM solution, which we can control, ground, and engineer.
Alternate Approaches to Deployment and some learnings
One could manage the complete infrastructure as IaaS and choose some alternate approaches. The approach could be to self-manage and host the solution fully perhaps on AKS or ACI. In doing so, I composed docker images and published them on DockerHub.
- https://hub.docker.com/repository/docker/keshav83singh/llminference/general
- https://hub.docker.com/repository/docker/keshav83singh/llm-miniconda-inference/general
The source code for the images is on GitHub. They have been compiled as a container with FastAPI and all PyTorch, CUDA 11.7, Transformers, BitsAndBytes dependencies installed. A successful hosting on any GPU-enabled service could get the API to work.
But.. It ain't so simple. Let me discuss my learnings unfolding the process. All failures are great teachers. While trying to get this going, my knowledge grew 10x in several of these services such as Azure Kubernetes Service (AKS), Azure Container Instances (ACI), Azure Container Registry (ACR), and Docker Hub, and finally, for a moment (with my never say die spirit) when I turned to GCP to explore beyond Azure, I looked at Google Kubernetes Engine (GKE), that didnt fare any better. Great learnings!
- The images with CUDA and all other LLM dependencies are seldom trivial. They are > ~ 10 Gbs, to say the least. Building such an image requires good space on your Local HDD. For me, with the diverse software running on my system, I struggle with that part; my PC is stressed with not more than 4 Gbs of space at any point in time. I do everything on Cloud as much possible.
- Usually, one would build Docker Image locally, tag it, and push it to Docker Hub or ACR, One of the cool things I discovered in the process is with ACR, there is a concept of agents, it enables you to build Docker Images directly on the cloud (with 0 space additionally needed on local). I found it really cool. Not so similar. We do have buildx for Docker. However, it does use to build/tag your images locally, so it does need space.
#builds images directly on ACR
az acr build --registry <registrysand> --image llminference:v1 .
#Similarly Docker Hub
Directly Build/Push on Docker Hub
BASH
>docker login
>export DOCKER_CLI_EXPERIMENTAL=enabled
>docker buildx create --use
>docker buildx build --platform linux/amd64 -t keshav83singh/llm-inference:latest --push .- With the image ready, when I tried to deploy the image from ACR to ACI with the same GPU-enabled compute, ACI timed out after 30 minutes. It was not able to get the service up. The large image size and the initialization time got better of it.
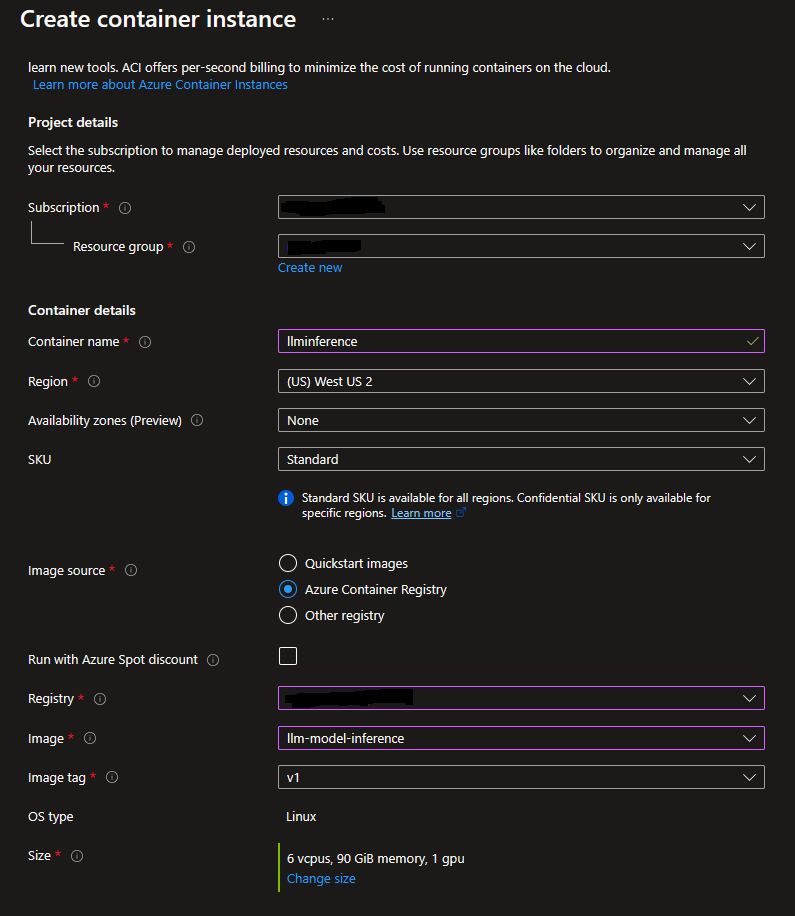
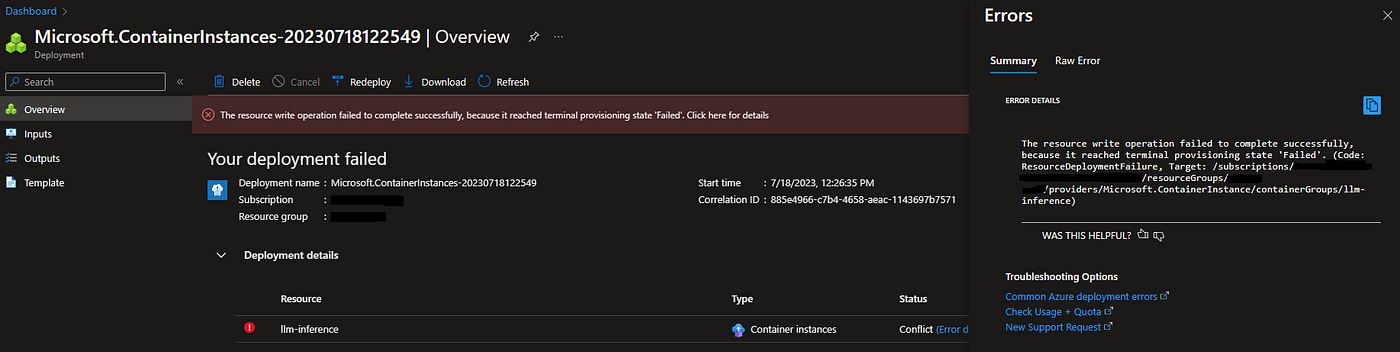
ACI Deployment
- Turning to AKS. First and foremost, once I had the GPU-enabled AKS configured, I needed to GPU configure it. Ensure GPU is configured and detected.
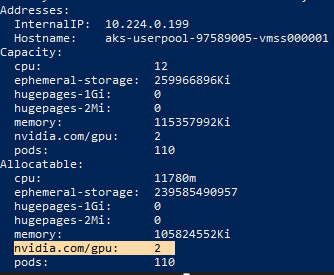
- Ensure AKS is connected to ACR. This ensures AKS will be able to pull images from configured ACR.

- AKS appeared to have a 5-minute timeout for Image Pull, beyond which we experienced 401 misleading errors. Its nothing to do with authorization, but the size of the image leads to an inability for AKS to pull and initialize it as a container on the pod.
[rpc error: code = Canceled desc = failed to pull and unpack image
"registry.azurecr.io/llmmodelinference:v1": context canceled,
rpc error: code = Unknown desc = failed to pull and unpack image
"registry.azurecr.io/llmmodelinference:v1": failed to resolve reference
"registry.azurecr.io/llmmodelinference:v1": failed to authorize:
failed to fetch anonymous token: unexpected status from GET request to
https://registry.azurecr.io/oauth2/token
?scope=repository%3Allmmodelinference%3Apull&service=registry.azurecr.io:
401 Unauthorized]- To troubleshoot it, I tried to configure KUBELET_OPTS= — image-pull-progress-deadline configuration on the Node by following the below steps.
- SSH Into AKS
Make changes to a file like /etc/default/kubelet in the terminal. You need to use a text editor to modify and save the changes. Here’s how you can do it using the nano text editor as an example:
- Open the file in the terminal with sudo privileges and the nano text editor. For example:
bash
sudo nano /etc/default/kubelet - Use the arrow keys to navigate to the line where you want to make the changes.
- Modify the line to set the KUBELET_OPTS value as desired, in this case: KUBELET_OPTS= — image-pull-progress-deadline=60m.
- Press Ctrl+O to save the changes. The editor will prompt you to confirm the filename. Press Enter to save the changes to the same file.
- Press Ctrl+X to exit the nano editor.
After following these steps, the changes will be saved to the /etc/default/kubelet file, and you will return to the terminal prompt. The modified configuration will take effect upon restarting the kubelet service.
sudo systemctl restart kubelet
- But to no help in my case. In fact, I have an open ticket with AKS team investigating this behavior and ways to mitigate it.
- There could be additional optimization opportunities to boost image pull time, such as boosting AKS Node’s Disk Max IOPS and elevating the network Max throughput (MBps)through using premium/ultra SSDs. It can help with faster image pulls.
GKE — I also turned to Google Cloud but couldn't secure quota even with a paid subscription.
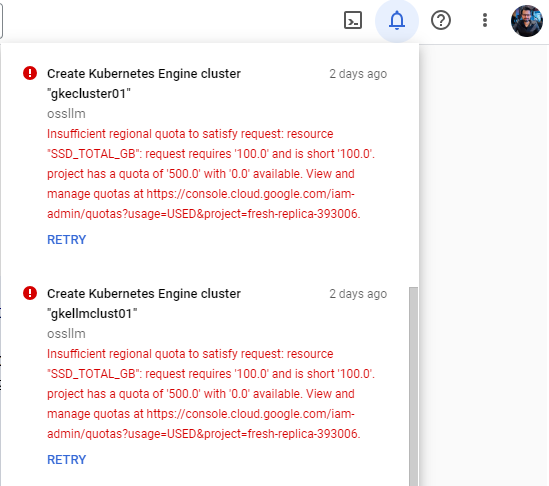
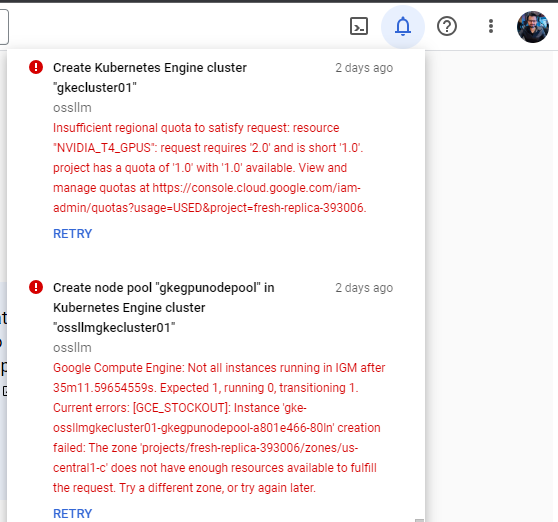
By this time, I took a step back to reflect and appreciate how seamlessly easy Azure ML managed endpoint allowed me to host the solution.
Hosting LLM as a IaaS solution is brutal & complex, with critically needed enterprise-grade engineering rigor, high availability, and observability, especially with soaring demand for GPU NC computes on all cloud providers. I did learn a ton and at much much deeper level trying to solve this problem without giving up. It did leave me wiser, and the acquired wisdom is shared! Hope you find this a great starting point and gain value from the share.
- This blog post was originally published at: https://blog.devgenius.io
#ml #Azure